bitproto 是一个比特级别的数据交换格式。 它类似 protobuf ,是一种通信数据的序列化机制。
下面是一个 bitproto 的例子:
message Data {
uint3 the = 1
uint3 bit = 2
uint5 level = 3
uint4 data = 4
uint11 interchange = 6
uint6 format = 7
} // 32 bits => 4B
可以看到,在 bitproto 中可以使用 uint3 这样的比特级别的类型。 上面的 Data 总共由 7 个 字段组成,总共在编码后占用 4 个字节。
各个字段在编码后的二进制数据中的分布如下图:
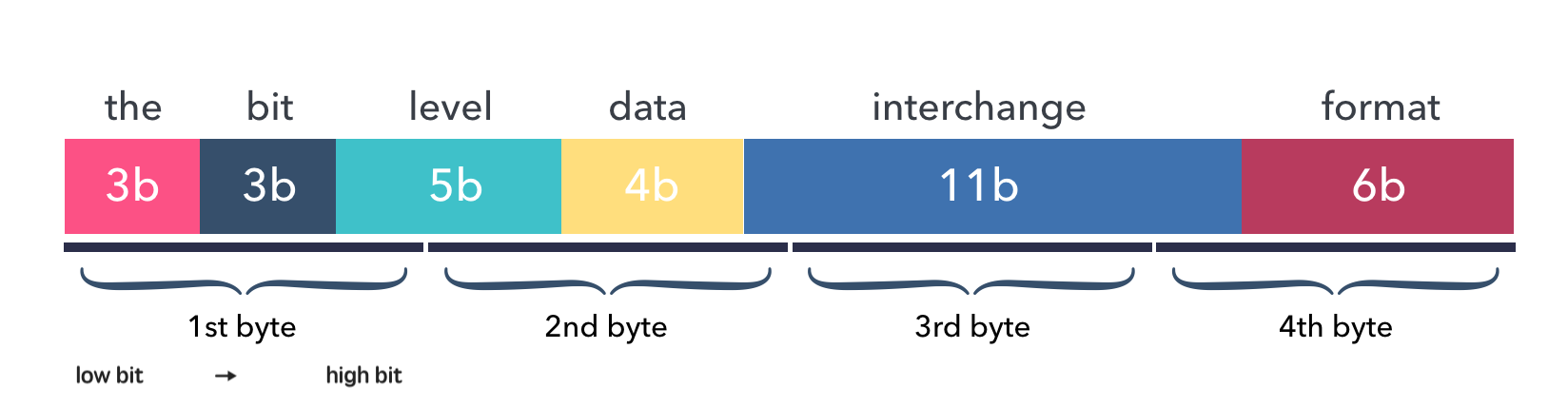
数据就如同在内存中的排列一样,没有添加任何类型反射信息,也没有任何的的缝隙。
本文主要记录 bitproto 的研发过程和工作原理。
项目的由来 ¶
2018 年中,我来到机器人创业公司 yogorobot 工作。 在这里第一次和嵌入式同学们合作。当时我开发的程序需要和一些单片机程序进行通信, 具有以下的特点:
- 通信量是非常受限的,而且字节数越少越好。
- 嵌入式系统的计算能力有限,因此协议的编解码速度越快越好。
同时,当和大家讨论协议的时候,我发现嵌入式同学给出的协议具有以下情况:
- 一些字节是拆开的,比如低位的比特表示一个字段,高位的表示另一个字段。
- 甚至为了 C 语言中的内存对齐,设计了一些冗余字节。
由于我当时需要在多个端用不同语言和一些单片机进行通信,因此,我可能需要针对多个协议格式编写多次编解码的逻辑。 于是,我开始想把互联网世界的 protobuf 引入进来。
对于互联网工程师而言,把 protobuf 带入 Python 或者 Golang 这些高级编程语言是比较容易的, 但是对于 嵌入式 C 语言而讲,事情没有这么简单。 protobuf 并没有天然支持纯 C 语言,需要寻找 替代品才可以。 而且,protobuf 没有支持比特级别的数据序列化,这无法满足我们想要协议设计的非常紧凑的期望。
读者可能会好奇,你们到底希望协议有多么紧凑?
举个例子来说,对于一个门的状态,会有两种:开的 和 关的。如果从长期来看,这个门还可能有 正在开 和 正在关 两个中间状态,再加上一个 未知状态,那么一个门的状态可能有 5 种。 如果门的结构不发生变化,那么一个门的状态不会再多了。如果我们用一个 8 位的整数 uint8_t 来表示一个门的状态的话,可以表示 256 种状态,但是我们只需要 5 种可辨状态就可以了, 也就是只需要 3 个比特就可以存储这个信息量。
你们真的需要节省这 5 个冗余的比特吗?是的,在我们的场景中,一些通信方式上的通信量限制是非常严格的, 可能需要十几个字节甚至几个字节来完成通信,除去头尾协议框和协议检验字节后, 协议内容部分的通信量将更为珍贵。
随着工作的展开,我也越来越理解为什么嵌软工程师们在协议设计上 “惜字如金” 。
protobuf 支持变长类型,它会在编码的数据中添加反射类型的信息,而我们不想浪费一点协议空间。 正因为 protobuf 是变长的,因此它的数据类型的颗粒度非常的大,比如没有 uint8 ,只有 uint32 。
protobuf 没有胜任这个工作还有一个非技术的原因: 我们希望从协议层面清楚地知道传输中的数据和内存中的数据的结构和大小。
因此,我开始构思一个类似 protobuf 语法的,但是符合嵌入式需求的消息格式。
第一个版本 ¶
第一个版本的 bitproto 主要考虑了以下特点:
- 人们要可以清楚地从协议层面知道数据的结构和大小。
- 需要支持比特级别的序列化。
- 速度要快,单片机上计算能力很弱。
- 生成的代码要足够简单,容易上手。
- C 语言是要支持的第一等语言。
我最初的构思,就是把大家手工设计的协议用一个类似 protobuf 的协议语言描述出来。 于是有了类似下面的语法设计:
proto pen
enum Color : uint3 {
COLOR_UNKNOWN = 0
COLOR_RED = 1
COLOR_BLUE = 2
COLOR_GREEN = 3
}
type Timestamp = int64
message Pen {
Color color = 1
Timestamp produced_at = 2
}
和 protobuf 一样的是, bitproto 的语法支持了枚举和消息类型。 另外,借鉴了一下 thrift 的语法,加入了类似 typedef 的自定义类型支持。
在对比特级别的支持上,直接采用了 uint{n} 的语法,非常有趣。
bitproto 包含两个主要的模块:语法解析器 和 代码生成器。
由于之前做 thriftpy 的经验, 我很快使用 ply 实现了语法解析器。
bitproto 编解码的工作原理则是:
首先把一个消息的字段进行递归遍历,直到所有要处理的对象都是一个基本类型。
然后对每一个基本类型,逐个字节的进行比特位对齐,之后考虑比特数据。
举个例子来说,比如我们要从一个 4 字节的基本类型 (比如说 uint32) 的第 i 个比特开始, 逐个拷贝 n 个比特到目标字节流 s 的第 j 个比特的位置上。
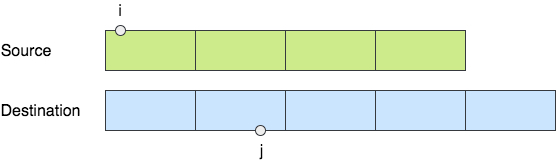
首先,要找出拷贝源和目标串的对应字节的位置 i/8 和 j/8,取出两个字节后, 依次进行字节内拷贝,直到 n 个比特都拷贝完成。
考虑字节内拷贝一次比特的数量 c , 它是以下三者中最小的一个数:
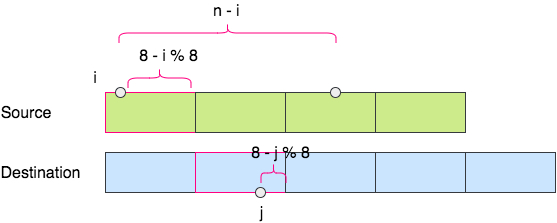
n-i当前处理类型的,剩余需要拷贝的比特数量。8-i%8源数据字节内剩余的比特数量。8-j%8目标串字节内可用的空间大小。
接下来,就是对两个字节做对齐处理:
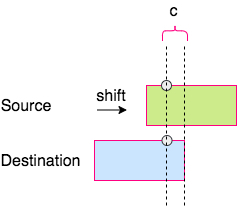
把源数据字节进行向右(或者向左,视目标字节位置靠左还是靠右而定)的位移, 然后用或操作符取出要拷贝的 c 个比特即可。
无论编码还是解码,都是一种比特拷贝。原理是一样的。
第一版的 bitproto 会递归遍历一个消息的所有基本类型,然后直接生成拷贝比特的语句。 比如, C 语言中生成的代码类似下面:
int EncodeDrone(struct Drone *m, unsigned char *s) {
s[0] |= (((unsigned char *)&((*m).position.latitude))[0] << 3) & 248;
s[1] = (((unsigned char *)&((*m).position.latitude))[0] >> 5) & 7;
...
}
int DecodeDrone(struct Drone *m, unsigned char *s) {
((unsigned char *)&((*m).position.latitude))[0] = (s[0] >> 3) & 31;
((unsigned char *)&((*m).position.latitude))[0] |= (s[1] << 5) & 224;
...
}
可以看到,生成的编解码函数中没有任何循环语句、if-else 判断,非常直白的对每个基本的数据字段进行比特级别的拷贝。
第一版的 bitproto 实现了对 C 、Go 和 Python 的支持。 在嵌入式环境下,编解码的单次调用开销仅消耗 10μs 左右的时间, 我们的嵌入式工程师非常喜欢这个工具。在随后的两年内,bitproto 应用到了公司基本上所有的和嵌入式通信的场景, 表现非常出色。
遗留问题 ¶
在 bitproto 第一版完成开发后,随后的两年时间内我基本没有时间来维护它。但是它仍然有一些缺点存在:
扩展性问题
由于 bitproto 中所有的类型都是定长的,因此对协议的向后兼容设计造成了麻烦。这一点上, protobuf 做的很好, 因为它向编码数据中加入了反射信息,这样编码端的单方面新增字段,解码端会跳过不认识的字段标号, 这样就到达了向后兼容的目的。而 bitproto 的编码数据中没有任何类型反射信息。 这一个问题是 bitproto 最为重要的一个缺点。
零字节问题
同样因为 bitproto 中所有类型是定长的,因此,当真正有意义的数据占用类型的大小不那么多的时候, 类型中其他的字节就会是零字节,这些零字节没有传输有效数据,但是在占用通信量。我没有花时间再去在 bitproto 层面解决这个问题,而直接在外面加了一层压缩机制,选用常用的 zlib 之类的压缩算法即可。
- 对于嵌入式环境下的通信,这一般不是问题,因为其通信量本来就很小, 其次, 压缩和解压缩本身也是耗费 CPU 计算资源的。
- 对于其他环境(unix 系统),外面套用一个通用的压缩算法,可以有效压缩空中的传输量。
生成代码大小的问题
前面的生成代码示例中可以看到,bitproto 会针对每个基本类型,拆解到字节级别进行比特拷贝。 当协议文件中消息比较多的时候, 或者定义的数组容量比较大的时候,语句生成的就会比较多。 生成的语句数目和类型的字节量是有线性增长关系的。 代码的大小之所以成为一个问题, 是因为嵌入式系统上通常会有很小的存储空间。
在 2020 年末,我最终离开了 yogo,和 leader 沟通后, 我利用离职在家的时间,开始解决这些问题,并对第一版的实现进行了重写。
新版本 ¶
新版本的 bitproto 已经开发完毕,主要完成了以下内容:
- 语法解析器的重写: 重新梳理抽象语法树,语法规则的实现更为优雅。 此外,加入了一个内置的语法风格检查器。
协议的向后兼容: 这一点作为新版 bitproto 最大的一个功能目标,为了达成这一点,还做出了如下改动:
加入对各个语言的编解码的库支持。
在第一版的 bitproto 中,无需下载和安装任何依赖,就可以实现编解码, 是因为 bitproto 的编译器直接把编解码语句全部生成了出来。而扩展性的功能是依赖动态计算的,因此必须把编解码交给库来完成。 同时,这样做可以打破代码生成量和通信字节数的线性增长的相关性。
新增了一个语法标记,来标记扩展性消息和传统消息。
对于协议的向后兼容性的支持,我也考虑过类似 protobuf 的方案 编码的数据带入字段的标号,解码侧只解码自己认识的字段。但是,这种方式带入的额外字节量比较大。
message Data {
uint32 field_old = 1;
// Decoder don't know this field number, skip it.
uint32 field_new = 2;
}
另外,放弃这个方式的主要原因是,如此的设计根本上把 bitproto 的协议编码布局从定长转向了变长,这引起了质的变化。
仔细分析 bitproto 真正发挥威力的场景,就可以知道,bitproto 还是应该以定长为根本点。 bitproto 主要的场景是在嵌入式场景, 或者和嵌入式发生关系的场景。 一般地,嵌入式固件的更新频率并不高,起码远远没有互联网程序的更新频率高。 也就是说,嵌入式其实对于扩展性的需求没那么强烈。
但是,也不是没有需求,比如典型的 CS 架构下, 当云端服务器单方面更新协议时,下挂的终端设备没有办法一次性完成固件更新时, 协议的向后兼容就是一个问题。
最终,我考虑这样的方式:以最小的额外信息的添加量,支持协议的扩展能力。
不过,无论如何设计,要支持协议的可扩展性,总逃不过要在编码数据中带入额外的反射信息。 于是,最终的方案是,花费 2 个字节的额外信息,来表示消息的大小(即所占用的 bit 数目)。 这样,当编码端单方面新增协议字段时,解码端会根据消息中的头两个字节,判断出消息字节流的截止位置, 来跳过自己不认识的新字段,就达到了对协议向后兼容的目的。
bitproto 的新版中,用一个单引号来标记消息是可扩展的,如果编码和解码两方对齐协议的时候, 已经标记一个消息是可扩展的, 那么未来一方单方面新增协议字段,是没有问题的:
// Single quote to mark a message to be extensible
message Data' {
uint3 field_old = 1
// Decoder will skip new fields.
uint4 field_new = 2
}
解码的原理如下图所示:
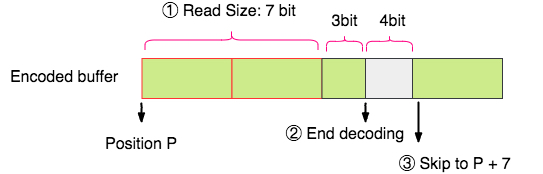
- 解码端在解码一个消息的时候,先记录起始位置
P(即在字节流中的比特索引)。 - 读取消息的头两个字节,获取到消息的大小 (多少个比特)。
- 然后按照解码端自身持有的协议结构信息进行正常解码。
- 解码完成后,把记录解码位置的指针设置到
P + Size, 来跳过冗余的比特流。
对扩展性的支持,不止语法层面上新增一个单引号的支持这么简单,真正的工作量,在于把编解码的实现方式, 从代码生成变成库支持,这部分工作占掉了我大部分时间。 因为需要用 C、Go 和 Python 分别对这套编解码机制进行编程实现。不过一个小的感想是, 这三个语言中,C 语言实现起来最为方便,原因在于它拥有指针的功能,可以直接通过指针操作数据区。 而对于 Go 和 Python 而言,则需要通过接口抽象的方式来达到目的,这就必须借助更多的代码生成的能力。
在设计上,编解码的支持库按以下原则进行:
C 语言支持库:没有采用任何动态内存分配机制。
是因为,C 语言的场景是嵌入式,而动态内存分配会拉低性能,同时会增加复杂性,嵌入式领域比较抵触这个事情。
Go 语言支持库:没有使用反射。
没有采用类似
encoding/json的序列化的实现办法,就是说,没有使用反射。对于 Go 来说, 要想操作数据,不走反射机制,又要针对这么多类型,那就要借助代码生成。 因此,Go 支持库采用了 “代码生成 + 接口抽象” 的方式。 同样,出于对性能的追求,也没有使用类型断言。
在扩展性的能力实现完毕后,看起来事情完成了,但是,还没有。
鱼和熊掌 ¶
一切都很好,直到在一个 stm32 开发板 (72 mhz, cortex-m3) 上进行性能测试。
最初在 stm32 的性能测试结果是,单次编码或者解码的耗时为 658μs ,在我的 macbook 上的测试结果为 6μs 。
这个结果,对于 macbook 当然足够快了,但是对于嵌入式程序,不 ok 。
于是,我开始针对 C 支持库进行优化:
- 第一步,消除一处结构体赋值开销,改用地址引用。
- 第二步,优化枚举类型的代码生成。
- 第三步,提取计算公因子。
- 第四步,优化取模操作、除法操作到位操作。
一顿优化下来,拿到的结果是:stm32 上 234.4μs , macbook 上 2.7μs。
接下来,真正的优化开始了,因为上面的四步都是语言层面的优化技巧而已。 真正的优化还是要在算法层面下功夫。
前面提到,无论编码还是解码,都是在把结构化数据拆解到基本类型后, 然后一个字节一个字节进行比特数据拷贝。所以,算法的优化点就在于,是否可以降低循环的次数! 因此,我寻求批量字节拷贝比特数据的方法。
用伪代码来看下优化前的算法逻辑:
while n > 0 { // 当前剩余的要拷贝的比特数量 > 0
c = min(...) // 计算单字节内需要拷贝的比特数量
copy(src, dst, c) // 对单字节进行拷贝
n -= c
}
可以看到,这个算法最快不超过 O(nbytes) , 其中 nbytes 是字节数量,最慢是 O(nbits)。
新算法的思路是:
- 先把要拷贝到的目标串的位置对齐。即目标串的比特索引值要是
8的整数倍。 这一过程可以复用当前的字节内拷贝比特的逻辑。 这个过程几乎一次到两次就可以把目标串进行对齐。 - 对齐后,当剩余需要拷贝的比特数量比较多的时候,把源数据用整型读出,进行右移操作后,直接进行逐字节复制。
新算法的第一步,是要先通过老的算法的方式,到达下面图示的状态,这个状态下,目标串的起始比特索引值处于字节的 0 bit 处, 这样为后面的直接赋值法做准备。
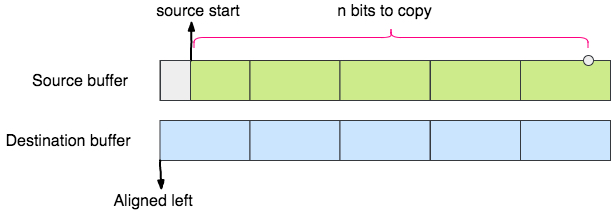
下面就是 C 语言指针展示威力的时候了,通过指针按照整型直接读取此时源数据区的数据。比如,如果还有大于 32bits 需要拷贝, 则可以直接读取一个 uint32_t 类型来:
uint32_t v32 = (*((uint32_t *)(src_ptr)));
读取后,将这个数字进行右移,以和目标串进行对齐 (注意上图中,低位在左,向低位位移应该是右移)。
v32 >>= shift;
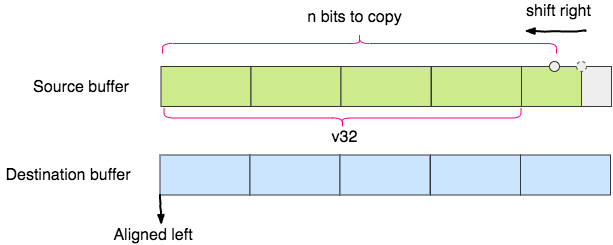
这时,就可以直接把 v32 的字节一个一个直接赋值到目标串了:
unsigned char *ptr = (unsigned char *)(&v32);
dst_ptr[0] = ptr[0];
dst_ptr[1] = ptr[1];
dst_ptr[2] = ptr[2];
dst_ptr[3] = ptr[3];
如法炮制出来 v16 和 v8 的情况。这样,比特拷贝就有机会进行批量拷贝了。
测试的结果是,stm32 上单次编解码消耗 130μs , macbook 上 1.3μs 。 至此,性能已经提升了 5 倍,不过,我还是没有满意。
为什么呢,因为老版本的性能是 stm32 上 10μs , 大概还有 13 倍的距离需要优化。
最终,我将老版本的代码生成方式叫做 优化模式 。 bitproto 的编译器在这个优化模式下,会直白的生成老版的编解码语句,而不必使用库支持。 代价则是,优化模式下无法保证协议的向后兼容设计。
目前,我仍然没有找到一个办法,可以同时达到 10μs 的编解码性能和实现消息的可扩展能力。 鱼和熊掌,不可兼得。
对于优化模式的使用场景,我的总结是:
- 如果程序是性能敏感的,比如,必须要在非常小的时间帧内完成密集计算的,那么,采用优化模式,放弃兼容性。
- 如果
100μs和10μs差别不大,那么还是建议走支持库的方式,也就是可以使用兼容性能力。
其他的遗留问题 ¶
截止目前,bitproto 仍然有一些遗留问题:
bitproto 的编解码操作使用了很多指针强转,当我们试图读取数据的内存布局的时候,大小端就是一个问题。 由于考虑到目前许多 CPU (x86, arm7, arm8 和大部分的 arm cortex-m3 mcu) 都是小端的,或者默认小端的。 因此我暂时没有打算来支持大端或者大小端无关性。就是说,目前 bitproto 还无法用于小端和大端系统之间通信。 另外,支持大端,还需要进行字节顺序的转换,这同样会引起性能上的进一步降低,也是我顾虑的一个点。
这一点,已经在前面提到。bitproto 的优化模式直白地生成了最终的编解码语句,这一切都是因为协议定长的设计。 然而,扩展性的支持需要依赖动态计算。bitproto 的标准模式通过编解码的支持库来支持扩展性,但是这降低了性能。
最后,欢迎你关注这个项目: https://github.com/hit9/bitproto
毕。
本文原始链接地址: https://writings.sh/post/bitproto-notes
