This article is a development log for a simple C++ behavior tree library bt.cc that I recently developed.
Behavior trees are one of the most commonly used programming patterns in AI for games and robotics.
The AI discussed here is not the machine learning kind, but rather “hard-coded AI,” or a type of “pseudo-AI.” This is because it doesn’t involve true intelligence; it’s the richness of behaviors that makes entities appear intelligent.
Put simply, it’s about how to modularly organize preset behavior modules, essentially a programming framework.
Design Considerations ¶
Separation of Entity State and Data from Behaviors.
If there are many entities of the same type with the same set of behaviors, we would prefer to store all entities together (e.g., in a contiguous memory block). The question then becomes: how do we separate behaviors from entity state data?
Organize Code in a Tree Structure to Describe the Behavior Tree.
A behavior tree itself is a tree structure, so the code should also be organized as a tree, making it clear and intuitive.
Support for Prioritized, Randomized, and Stateful Behaviors.
Behavior Tree ¶
Pre-designed behavior modules are organized into a tree. A Tick() call is propagated recursively from the root to its descendant nodes. Depending on the node type, different behavior patterns are formed.
After executing the Tick function, a node must report its status:
bt::Status::RUNNING // In progress
bt::Status::FAILURE // Failed
bt::Status::SUCCESS // Succeeded
The most basic types of nodes are categorized as follows:
Leaf Nodes: Nodes without any children.
There are two types:
ActionandCondition.Actionis responsible for executing a specific action, whileConditionchecks a specific condition and does not have aRUNNINGstate.For example, in the diagram below, action
Ais executed only after conditionCis successfully checked.
A schematic implementation of Condition
// Needs to be implemented virtual bool ConditionNode::Check(const Context& ctx); Status ConditionNode::Update(const Context& ctx) override { return Check(ctx) ? Status::SUCCESS : Status::FAILURE; }Some behavior tree libraries implement condition nodes directly as a type of decorator node, making them more convenient to use. In
bt.cc, I created a similar decorator node calledConditionalRun.A schematic implementation of ConditionRun
Status ConditionalRunNode::Update(const Context& ctx) { // condition is a Condition node, child is another child node if (condition->Tick(ctx) == Status::SUCCESS) return child->Tick(ctx); return Status::FAILURE; }And we can then use it in this way:
root .If<SomeCondition>() ._().Action<DoSomething>() .End() ;Single-Child Nodes: Nodes with only one child node, typically represented by
Decoratornodes.For example, in the diagram below,
Repeat(2)is a loop node. It reports success upwards only after its decorated child node has executed successfully twice. That is, in the second frame, when actionAsucceeds for the second time, the root node becomes successful.A schematic implementation of Repeat node
Status RepeatNode::Update(const Context& ctx) { auto status = child->Tick(ctx); if (status == Status::RUNNING) return Status::RUNNING; if (status == Status::FAILURE) return Status::FAILURE; if (++counter == n) return Status::SUCCESS; return Status::RUNNING; }
Composite Nodes: Nodes that can contain multiple child nodes.
These can be further subdivided into three types:
Sequence: Succeeds only when all child nodes return success; otherwise, it fails as soon as one child fails.A schematic implementation of Sequence node
Status SequenceNode::Update(const Context& ctx) override { for (auto& c : children) { auto status = c->Tick(ctx); if (status == Status::RUNNING) return Status::RUNNING; if (status == Status::FAILURE) return Status::FAILURE; } return Status::SUCCESS; }In the diagram below, the
sequencenode on the left reports success after all three child nodes succeed in 3 frames. On the right, it immediately reports failure and stops trying subsequent child nodes as soon as it encounters a failing child node.
Selector: Fails only when all child nodes return failure; otherwise, it succeeds as soon as one child succeeds.A schematic implementation of Selector node
Status SelectorNode::Update(const Context& ctx) override { for (auto& c : children) { auto status = c->Tick(ctx); if (status == Status::RUNNING) return Status::RUNNING; if (status == Status::SUCCESS) return Status::SUCCESS; } return Status::FAILURE; }In the diagram below, the
selectornode on the left reports success in frame 2 as soon as it encounters a successful child node. The one on the right reports failure in frame 3 after all child nodes have failed.
Parallel: Executes all child nodes in parallel. It succeeds only if all child nodes succeed; otherwise, it fails.Unlike the previous two, the
Parallelnode executes every child node once regardless, and then aggregates the results.A schematic implementation of Parallel node
Status ParallelNode::Update(const Context& ctx) override { int cntFailure = 0, cntSuccess = 0; for (auto& c : children) { auto status = c->Tick(ctx); if (status == Status::FAILURE) cntFailure++; if (status == Status::SUCCESS) cntSuccess++; } if (cntSuccess == children.size()) return Status::SUCCESS; if (cntFailure > 0) return Status::FAILURE; return Status::RUNNING; }For example, in the diagram below, both left and right sides ensure that each child node is executed, but the final result of
Parallelis determined by the number of successful child nodes.





Of course, the code snippets above represent the first version of implementation. The final implementation in bt.cc became slightly more complex due to the addition of Stateful composite nodes and priorities. However, the fundamental principles remain the same.
Visualization ¶
To represent a behavior tree visually, there are two possible styles:
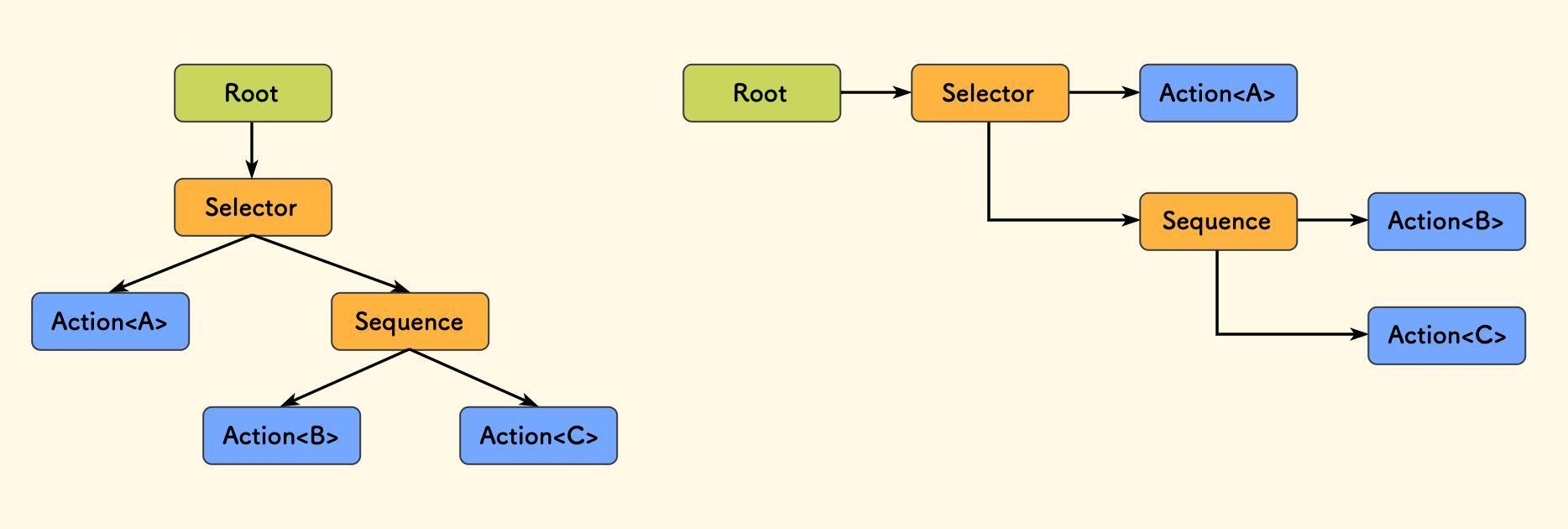
The left side shows a conventional tree structure. The right side is much more organized, so I recommend the style on the right. In this style:
- Top-to-bottom represents the priority relationship between sibling nodes, with higher nodes having higher priority.
- Left-to-right represents the parent-child relationship.
In a depth-first traversal, it goes from left to right, and then downwards.
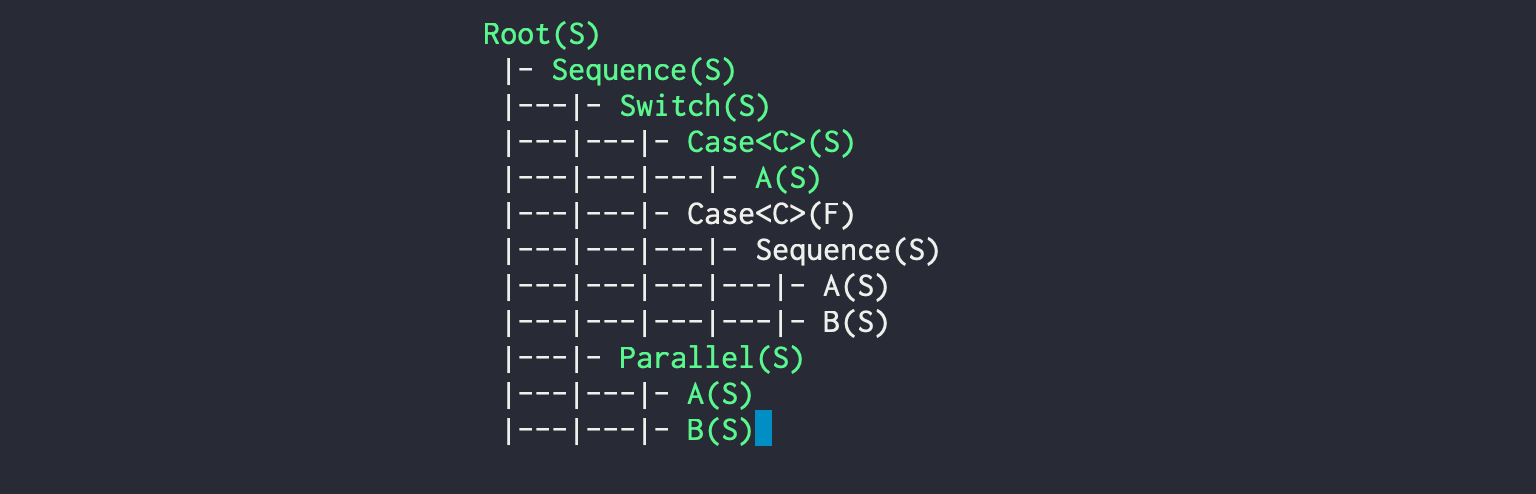
bt.cc supports a simple feature to visualize the behavior tree in the console for each frame. It also arranges the behavior tree in this style, where green indicates currently active nodes:
Organizing a Behavior Tree ¶
In code, the organization also follows this style:
bt::Tree root;
root
.Sequence()
._().If<A>()
._()._().Action<B>()
._().Selector()
._()._().Action<C>()
._()._().Parallel()
._()._()._().Action<D>()
._()._()._().Action<E>()
.End()
;
Here, the special method _() is responsible for increasing indentation, so the entire code looks like the final behavior tree structure.
The only detail is to not forget to call End().
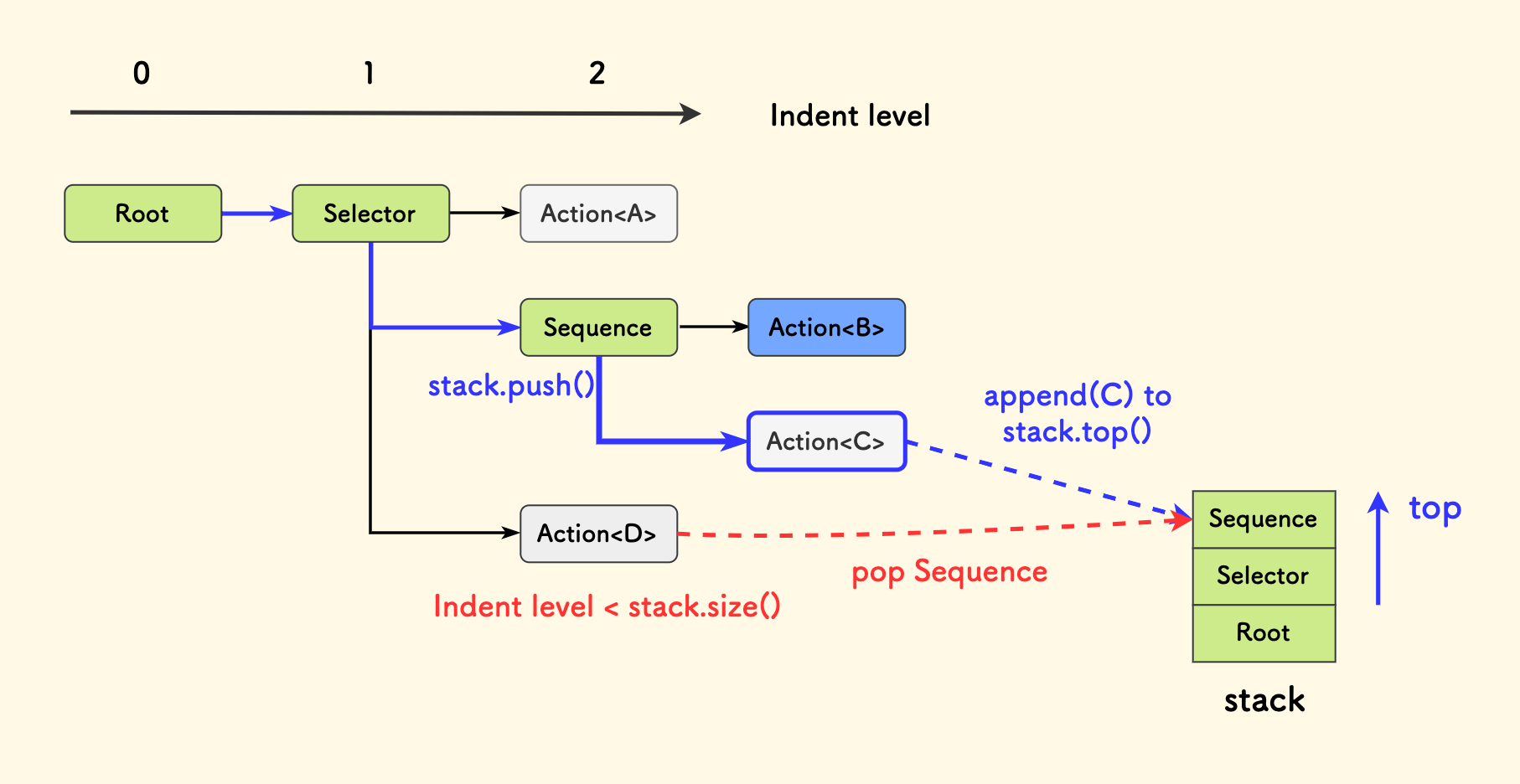
Internally, when building a tree, a stack is used to store the indentation path of “intermediate nodes”:
std::stack<InternalNode*> stack;
- When encountering an “intermediate node” (e.g., a composite node), it is
pushed onto the stack top. - When a new node is added, it looks at the “intermediate node” at the stack top (e.g., the
Sequencebelow) as its child node. - When indentation decreases, i.e., becomes less than the stack depth, the excess part at the stack top is flattened. At this point, the
Sequencenode is closed and popped from the stack.
Subtrees ¶
One of the most wonderful features of behavior trees is the modularity of behavioral capabilities.
Furthermore, we can organize a set of behaviors into a tree and then mount it onto another tree as a subtree. This is very similar to subroutine calls in functions.
// Walk function constructs a subtree
auto Walk = [&](int poi) {
bt::Tree subtree("Walk");
subtree
.Sequence()
._().Action<Movement>(poi)
._().Action<Standby>()
.End()
;
return subtree;
};
root.
.RandomSelector()
._().Subtree(Walk(point1)) // Here is move
._().Subtree(Walk(point2)) // Here is move
.End();
In fact, the description of a behavior tree itself is very similar to a programming language. Look, I even implemented Switch/Case:
root
.Switch()
._().Case<ConditionX>()
._()._().Action<TaskX>()
._().Case<ConditionY>()
._()._().Action<TaskY>()
.End()
;
Hook Functions ¶
The main supported hook functions are:
class MyAction : public bt::ActionNode {
public:
// Called at the beginning of a round, i.e., when the node's status changes from something else to RUNNING:
virtual void OnEnter(const Context& ctx) {}
// Called at the end of a round, i.e., when the node's status becomes FAILURE/SUCCESS:
virtual void OnTerminate(const Context& ctx, Status status) {}
// Called when this node is just built
virtual void OnBuild() {}
// Update executed every frame
virtual bt::Status Update(const Context& ctx) {}
};
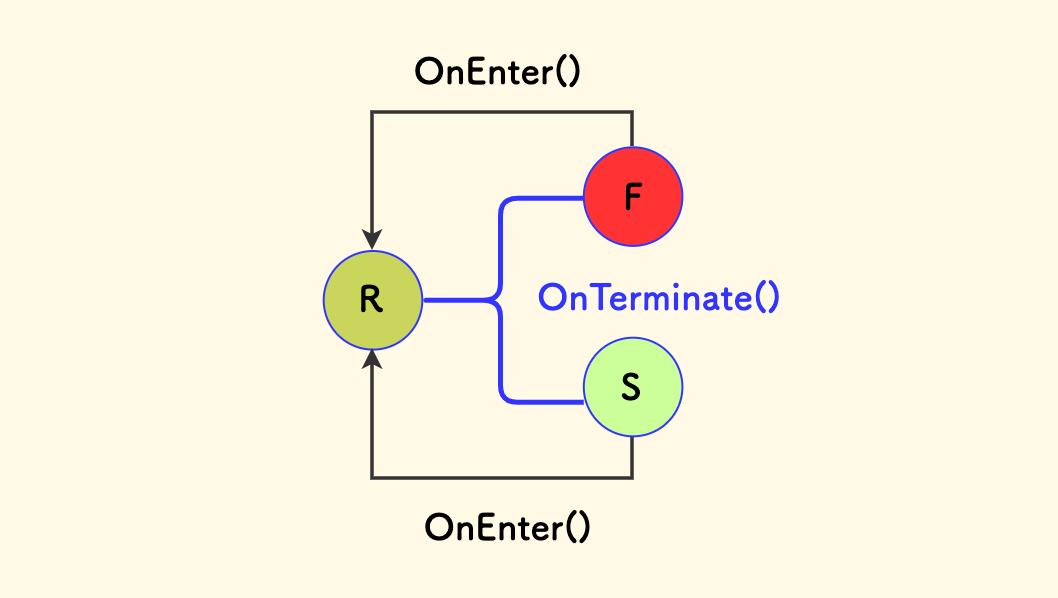
The timing of OnEnter and OnTerminate execution can be seen in the diagram below:
Of course, this depends on “stateful” data. So, how is this data separated from the organization of the behavior tree itself?
Separation of Data and Behavior ¶
Specifically, it’s about separating “entity-related data” from the behavior tree itself.
In terms of module implementation, it might be necessary to put all entities in one module and the classes of behavior trees and the tree structure code in another module (or system).
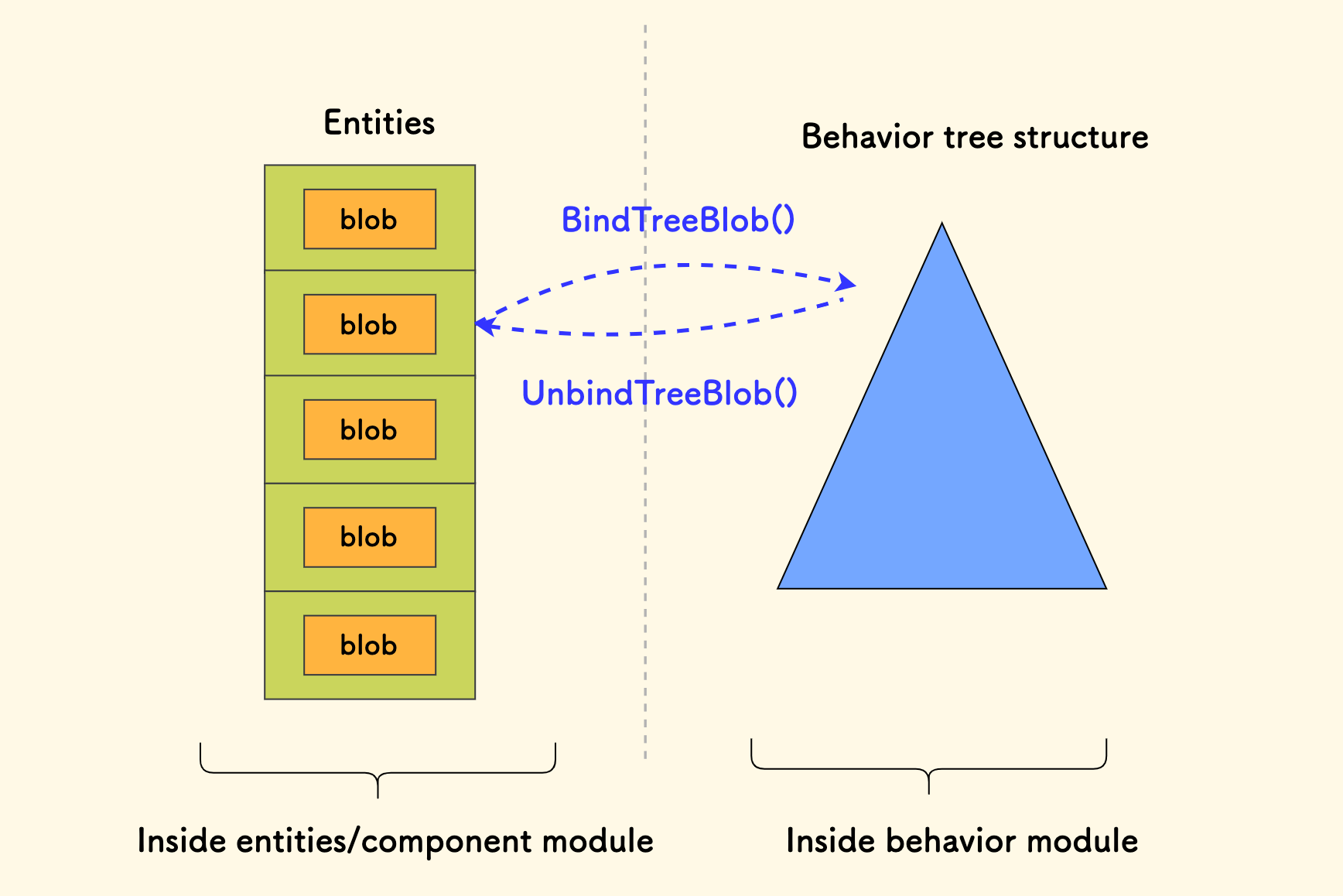
I came up with a concept called TreeBlob to store the data of a behavior tree for a specific entity. There are two implementations:
struct Entity {
// DynamicTreeBlob stores all entity-related state data in the behavior tree
bt::DynamicTreeBlob blob;
// Or use a fixed-size TreeBlob, which will be directly embedded in the Entity struct
// At most 8 nodes x at most 64 bytes per node, fixed-size 2D array
bt::FixedTreeBlob<8, 64> blob;
};
Either can be used. FixedTreeBlob is faster but also a bit more cumbersome. Its advantage is that it directly follows the entity’s memory storage, which is cache-friendly.
Then, entity data is operated on by the behavior tree through “temporary binding.” The main loop looks like this:
bt::Context ctx;
// Tick in the main loop
while(...) {
// Iterate through each entity's blob data block
for (auto& e : entities) {
// Bind an entity's data block
root.BindTreeBlob(e.blob);
++ctx.seq;
root.Tick(ctx)
// Unbind
root.UnbindTreeBlob();
}
}
Stateful nodes built into bt.cc (such as some decorators RepeatNode, RetryNode, etc., and general node state data) are stored in the blob, and not directly with the tree structure.
In summary, behaviors and entity data are separated in code and memory, and they work together through temporary binding:
Stateful Composite Nodes ¶
bt.cc supports “stateful” capabilities for the three composite node types. Their design purpose is to avoid repeatedly querying child nodes that have already succeeded (or failed) within one execution cycle, thus improving efficiency.
The diagram below uses StatefulSequence as an example. In frame 1, action A succeeds, and action B is in progress. In frame 2, A is skipped directly, and Tick querying starts from B. This continues until all child nodes succeed or fail, completing one execution cycle. The next execution starts from scratch.
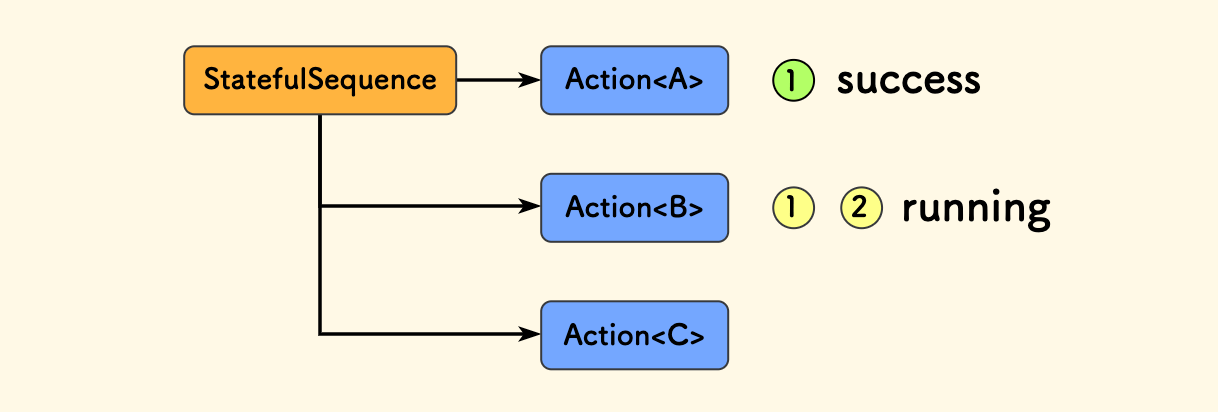
Internally, a container is used to store which child nodes need to be skipped, and it is cleared at the beginning of each execution cycle.
Prioritized Composite Nodes ¶
By default, all child nodes are of equal priority, set to 1. They are ticked in the order they are organized in the tree, from top to bottom.
However, you can override the Priority method to implement different priorities between sibling nodes:
class A : public bt::ActionNode {
public:
unsigned int Priority(const bt::Context& ctx) const override {
// TODO, return a positive integer
}
};
For example, for the selector node in the diagram below, the Tick() method of B will be queried first.
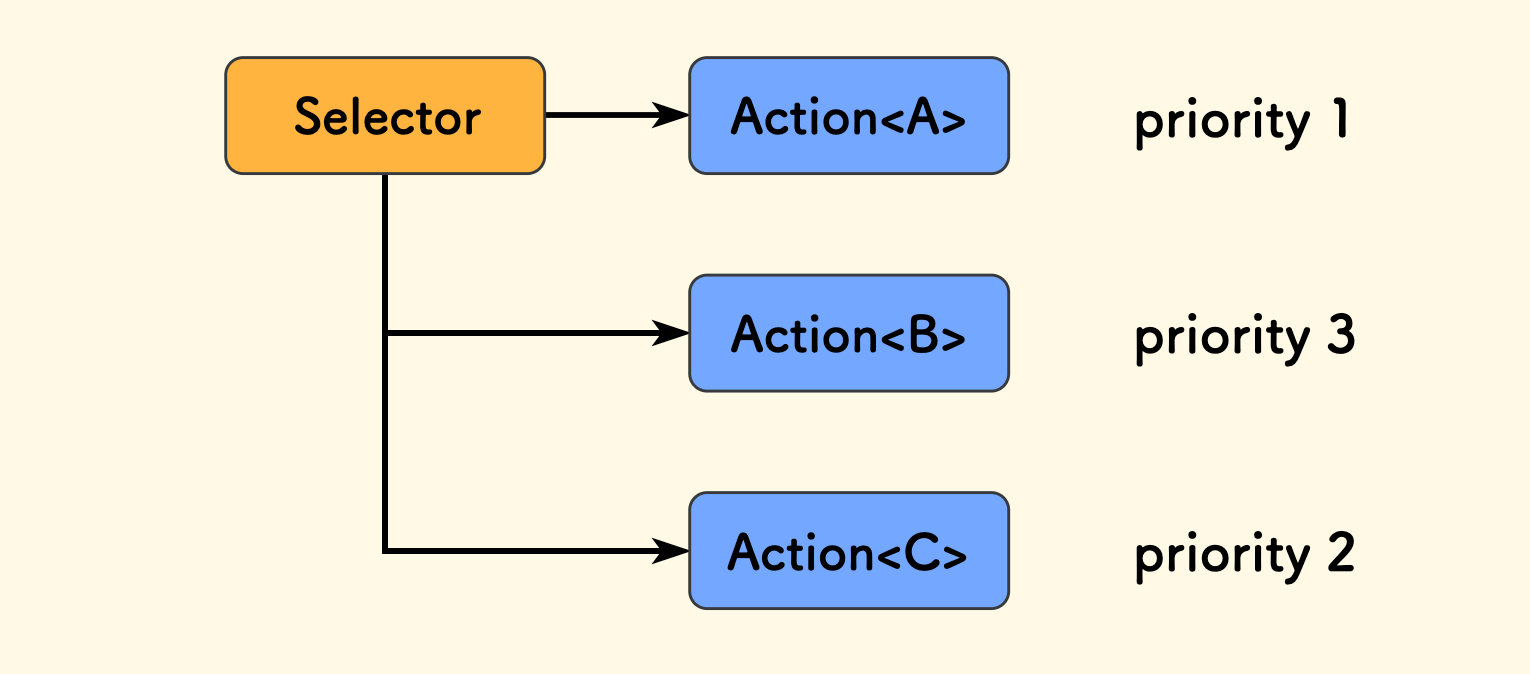
This priority is dynamic, meaning it can change between frames. A composite node will always prioritize ticking the highest priority child node.
Internally, a priority queue is used for implementation.
Two optimizations are implemented for details:
In-Frame Priority Caching
Because the
Priority()method is executed recursively in each frame, its performance is crucial. The priority of nodes in the current frame is cached internally.That is, it is guaranteed that the priority of each node is queried at most once in the same frame.
Furthermore, although node priority is entity-related data, because its lifecycle is limited to within a frame, it can be safely stored on the tree node, existing only as runtime data for the tree.
Equal Weight Optimization
Because a priority queue is used, the theoretical time complexity becomes
O(logN). However, this represents a performance degradation for cases where priority is not needed.One solution is for nodes to explicitly declare that they do not consider priority. However, I currently use a more “runtime” optimization, which is to check if all child nodes of a composite node are equally weighted when refreshing
Priorityeach frame. If they are equally weighted, then instead of using a priority queue, a general pre-allocated memoryO(N)queue is used as a replacement.In the diagram below, if the three child nodes are equally weighted in the current frame,
q1will be used, which is a simple FIFO queue (memory pre-allocated, no runtime memory allocation). Otherwise, if the three child nodes are not equally weighted,q2will be used, which is a priority queue, with an overall time complexity oflogN.

Randomly Selecting Nodes ¶
A random selector node RandomSelector is also supported. Its design purpose is that random selection can make AI less rigid, so it doesn’t always do exactly the same thing. Our monster NPCs can patrol to the left this time and patrol to the right next time.
The random selector node also considers node priorities, i.e., weighted random. This means that child nodes with higher weights have a greater probability of being selected.
And because it is a Selector node, it will continue to randomly select until it encounters a successful child node; otherwise, it ultimately fails.
For example, in the diagram below, it is uncertain which child node will be executed. It can only be said that B has the highest probability of being selected.
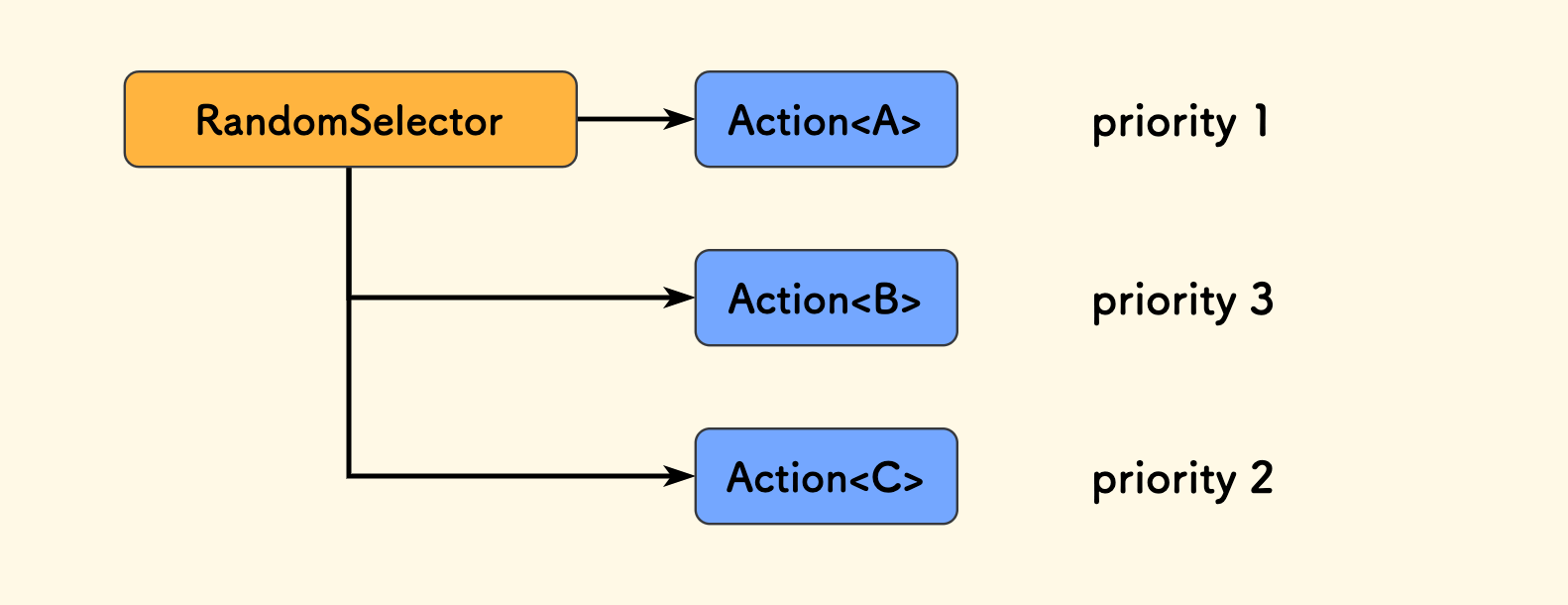
In addition, stateful random selection is also supported, called StatefulRandomSelector. In this case, child nodes that have already failed the test will not be considered again.
Blackboard ¶
In behavior trees, external data, such as world, is usually accessed using a blackboard.
I don’t think it’s necessary to encapsulate the blackboard into something like a hash table. A simple struct is sufficient, which is fast and simple. The core point is how to design the fields, business topics, and categories of this blackboard. The focus is on its content design, and the specific container form is not critical. Over-encapsulation can actually degrade performance.
The Tick() function supports a context structure parameter, where you can put a pointer to external data, such as a pointer to the blackboard struct, in data:
struct Context {
ull seq; // Current global tick frame number
std::chrono::nanoseconds delta; // Global time difference from the last tick to the current tick
std::any data; // User data, e.g., can store a pointer to a blackboard
}
Events ¶
I actually think state machines are more suitable for reacting to events, while behavior trees are more inclined to a polling-based working style. Therefore, behavior trees are relatively wasteful in terms of performance, as they always have to query all possible paths each time. There is an event-based behavior tree implementation, but I haven’t spent too much effort understanding whether this “event-driven” approach is formally defined as still being based on “polling.”
In traditional behavior tree implementations, everything starts with a frame function Tick(), or Update(). So how do we add events (signals) into this?
For this purpose, I separately implemented a signal library called blinker.h, which supports organizing signals into a tree by signal name, and then you can subscribe to a batch of signals by prefix matching.
Using it in a behavior tree, the diagram below is a schematic. OnSignal is a custom decorator node, indicating that Tick will only propagate downwards when the concerned signal is activated.
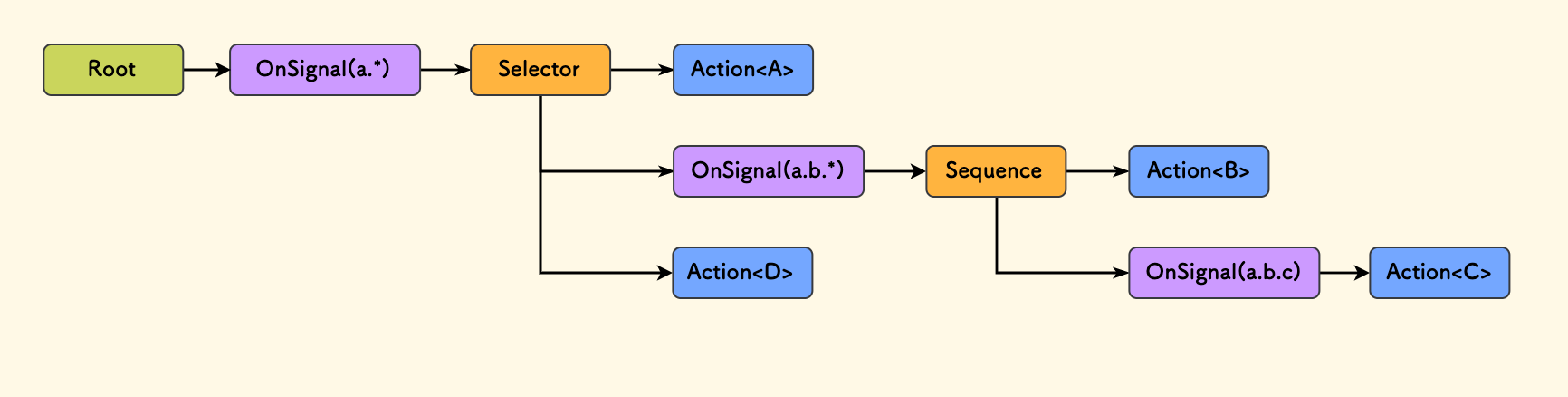
Since we can organize signals into a tree, raising the signals of concern as high up as possible can optimize the Tick polling process of the behavior tree and reduce empty queries. This is actually somewhat like an “event monitor.”
In code, it can be used like this:
root
.OnSignal("a.*") // Once no signal is matched here, it will not tick downwards
._().Selector()
._()._().Action<a>()
._()._().OnSignal("a.b.*")
._()._()._().Sequence()
._()._()._()._().Action<B>()
._()._()._()._().OnSignal("a.b.c")
._()._()._()._()._().Action<C>()
._()._().Action<D>()
.End()
;
Unfinished Performance Optimizations… ¶
There are currently several facts:
- Behavior trees are organized in DFS order in code.
- Our
Tickpropagation is in DFS order. - Every frame we need to execute
Tickstarting from the root of the tree.
So, a natural question arises: Can we arrange all nodes in memory contiguously in DFS order to improve CPU cache performance? In the behavior tree chapter of 《Game AI Pro 1》, this performance optimization method is mentioned. I excitedly tried to implement it twice, simply using a fixed-size contiguous memory approach, but the benchmarks showed no optimization effect, so it is considered an “unfinished performance optimization…”.
Furthermore, I don’t really consider “scripts” or “editors” because this library is currently for my own use (as a programmer), and programmers don’t really need the support of these things. Writing directly in C++ code is fast and lightweight~
Finally, code link: https://github.com/hit9/bt.cc, welcome to give a small star.
(End)
Please note that this post is an AI-automatically chinese-to-english translated version of my original blog post: http://writings.sh/post/behavior-tree.
Original Link: https://writings.sh/post/en/behavior-tree