本文记录周期字符串判别问题和它常见的两种方法:
问题 ¶
判断一个字符串是否由其一个子串重复多次构成。
例如:字符串 "abcabc" 是由子串 "abc" 重复两次构成的。
双倍字符串方法 ¶
把字符串翻倍,掐头去尾,如果原字符串在其中,那么原字符串就是周期串 。
假设字符串是 s ,把它的头尾字符分别染上黄色和蓝色:

把字符串 s 接到自身后面,然后掐头去尾,形成新字符串 s':
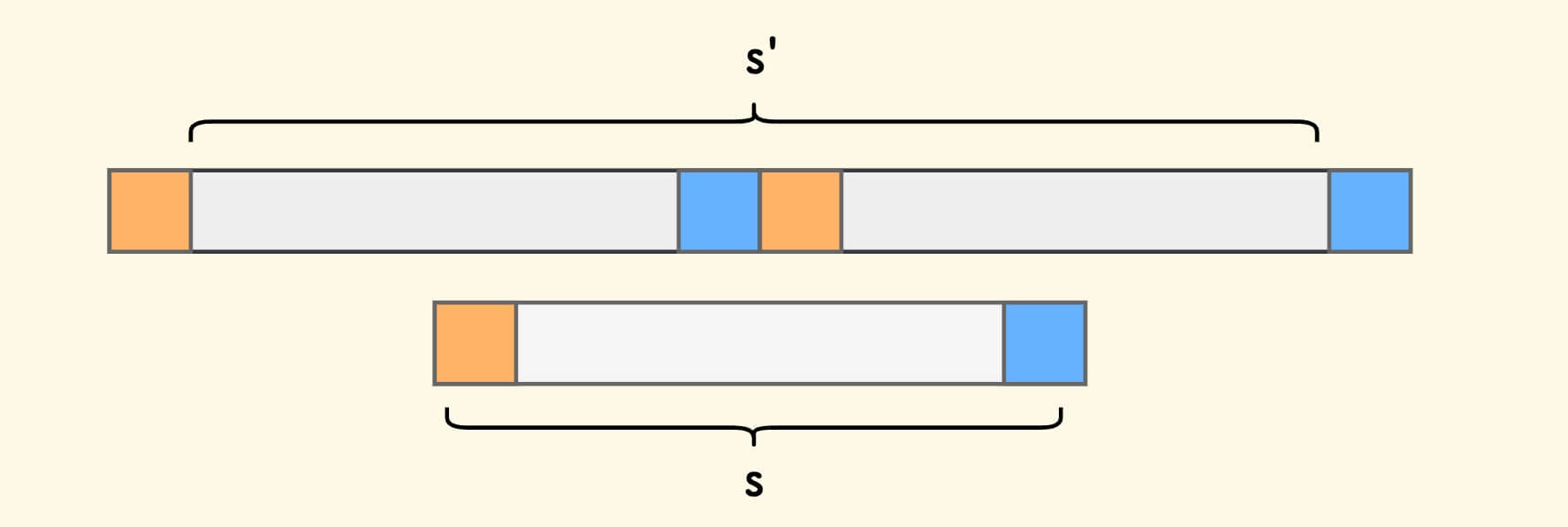
匹配意味着周期性
下面讨论原字符串 s 在新字符串 s' 中存在的情况。
一步一步对各部分涂色,使得相等的字符串颜色一样 。
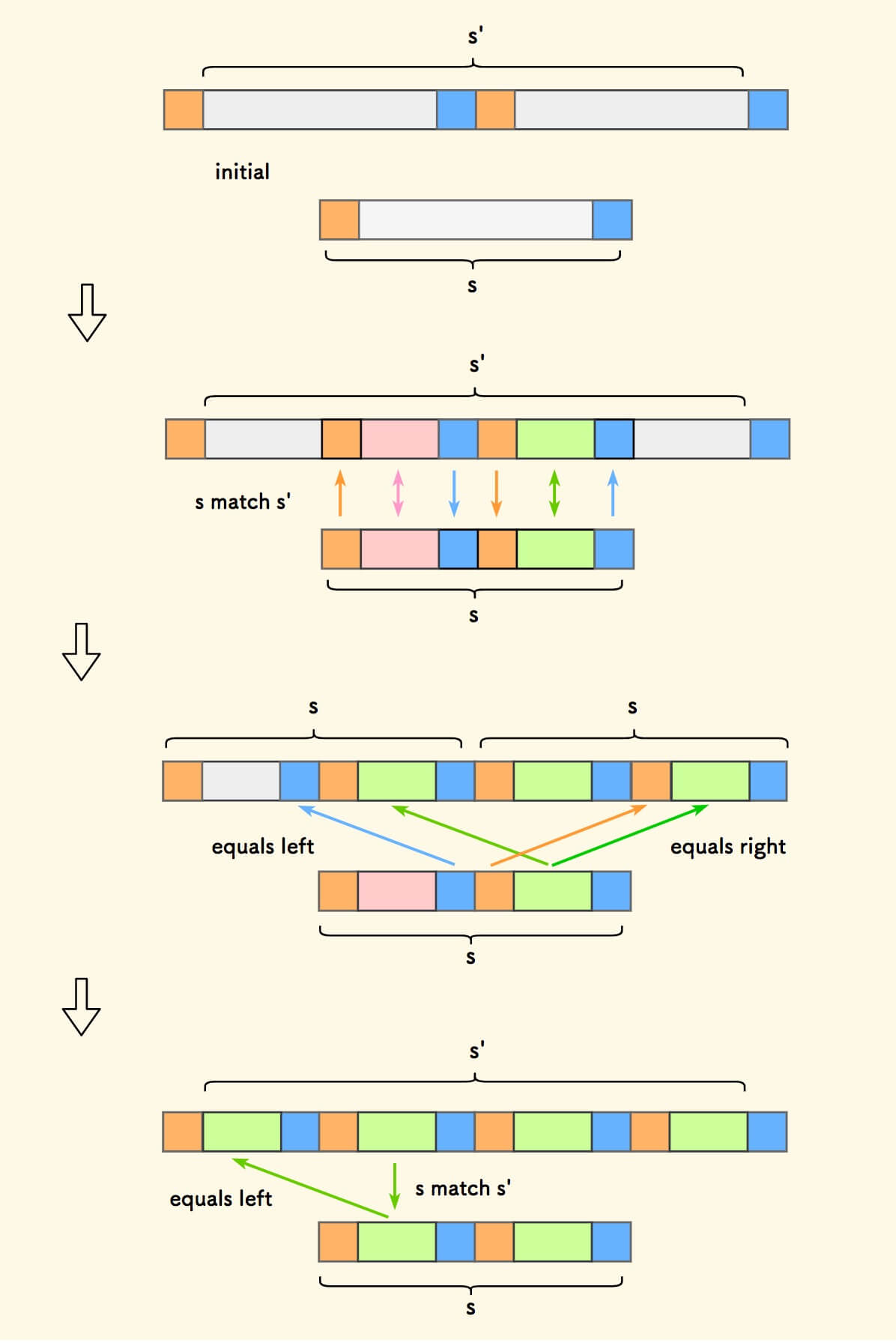
经过几轮的染色,可以看到最终 s 确实是一个周期串。
是否巧合?可以做一般性说明。
下图,不妨设右边匹配的少一些。对其中的任一字符 A ,可以按照如下的规则推演:
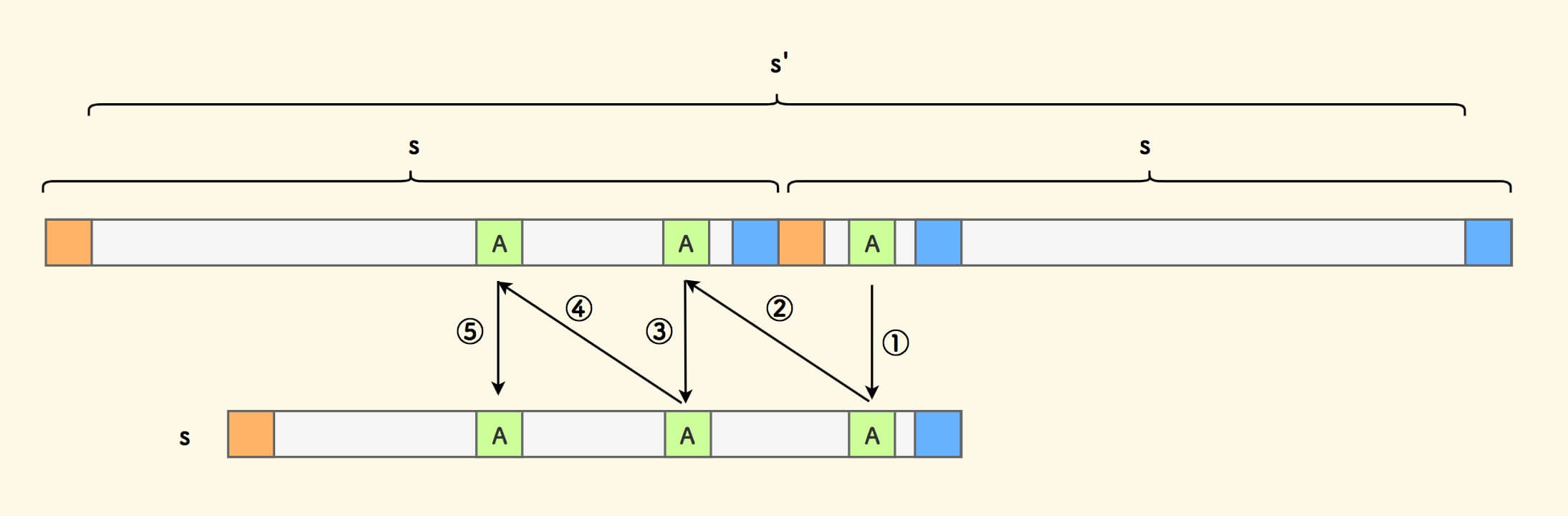
推演的细致说明
- ① 号推演,由于上下字符串匹配。
- ② 号推演,由于和左上方的自身相等。
- 如此反复推演。
如此,任一此区间上的字符 A 会在 s 中周期性出现。
即说明字符串 s 是周期串。
周期性意味着匹配
反过来,如果一个字符串 s 是周期串,那么它一定在对应的 s' 中吗?
任何一个周期串可以表达为: 由某个模式子串的重复多次构成 。
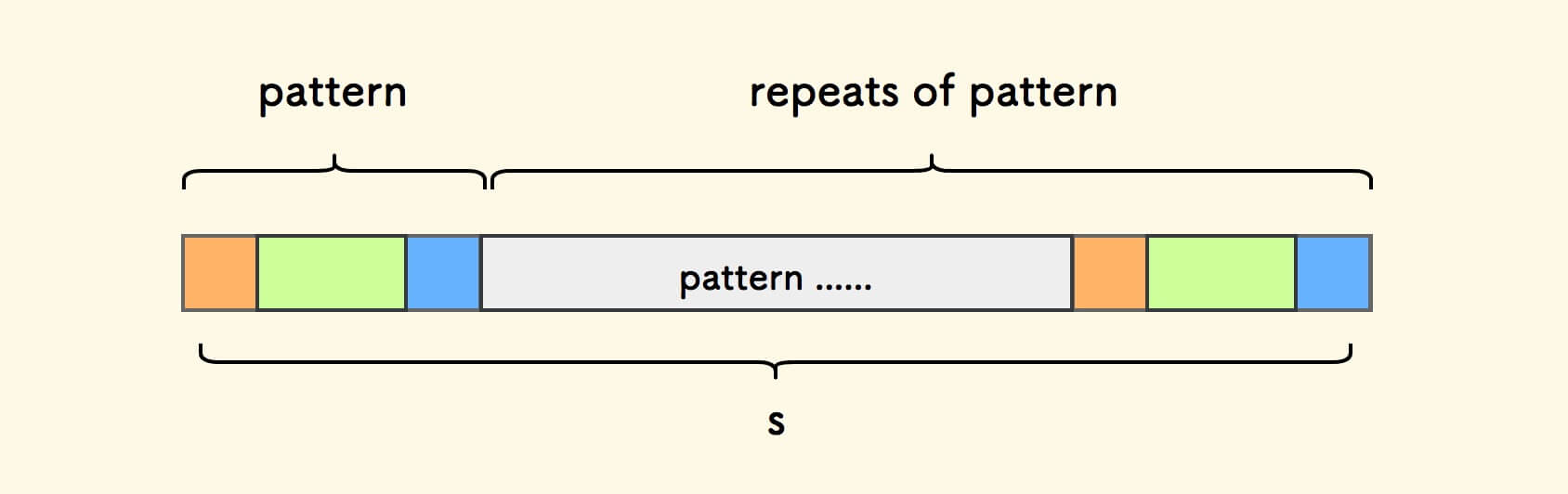
将周期串 s 的头字符对齐在第一个模式串后面, 每次右移一个模式串的长度。
可知,s 会在 s' 中有匹配,且可以有多个匹配。
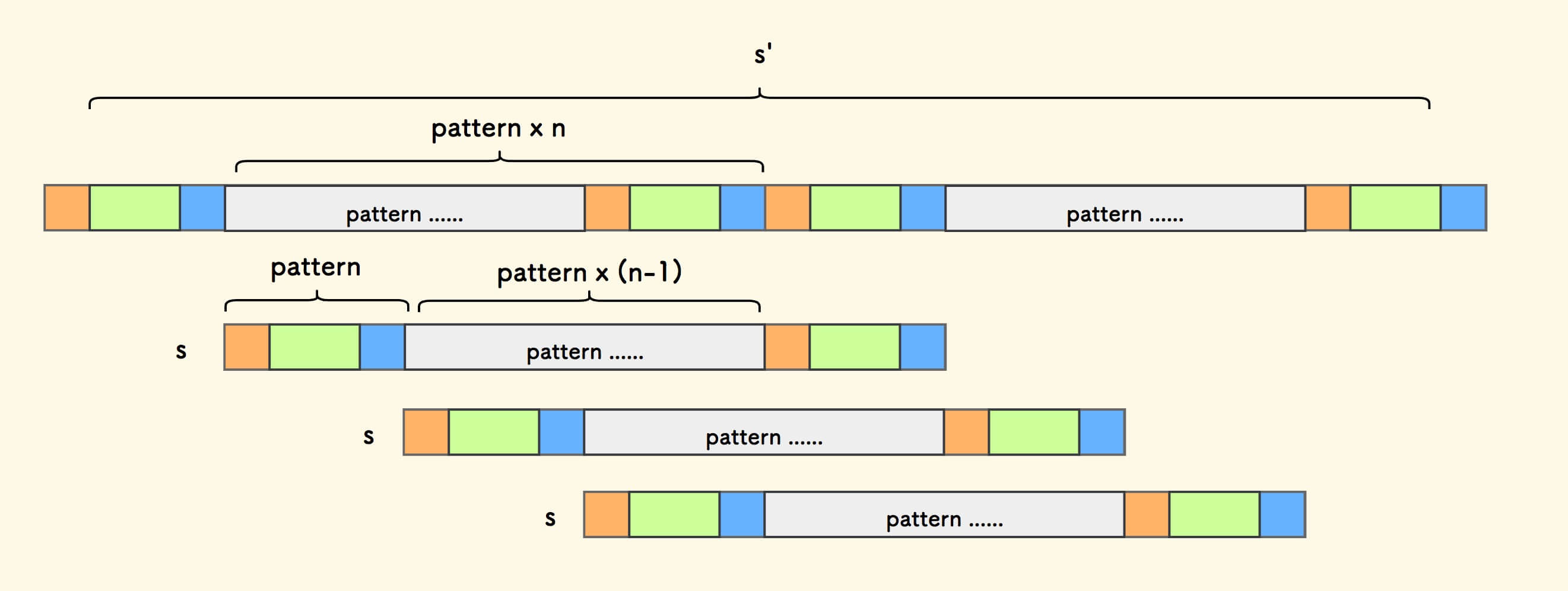
图中可看出, 因为模式串重复 n 次,所以会有 n 次匹配 。
构造双倍串 s' 时,移除头尾字符, 正是为了剔除最左和最右的两次必然匹配。 只有中间的 n 次匹配才用到了周期串重复模式串的性质。
结论
综上两方面说明了充分性和必要性,结论:
如果字符串在其掐头去尾的双倍字符串中,它就是周期串 。
周期串判断 - 双倍字符串方法 - C 语言实现
// 判断 s 是否是周期串模式
bool IsStringRepeatedPattern(char *s) {
int n = strlen(s);
if (n <= 0) return 0;
char a[2 * n - 2]; // s[1:] + s[:n-1]
strcpy(a, s + 1); // 拷贝 s[1:]
strncpy(a + n - 1, s, n - 1); // 拷贝 s[:n-1]
if (strstr(a, s) != NULL) return true;
return false;
}
本方法的实现,依赖语言自建的字符串搜索方法,将不做复杂度分析。
KMP 方法 ¶
假设要判断的字符串叫做 s ,将其尾巴字符标记为蓝色。
取 q 为不包含尾巴字符的前缀。
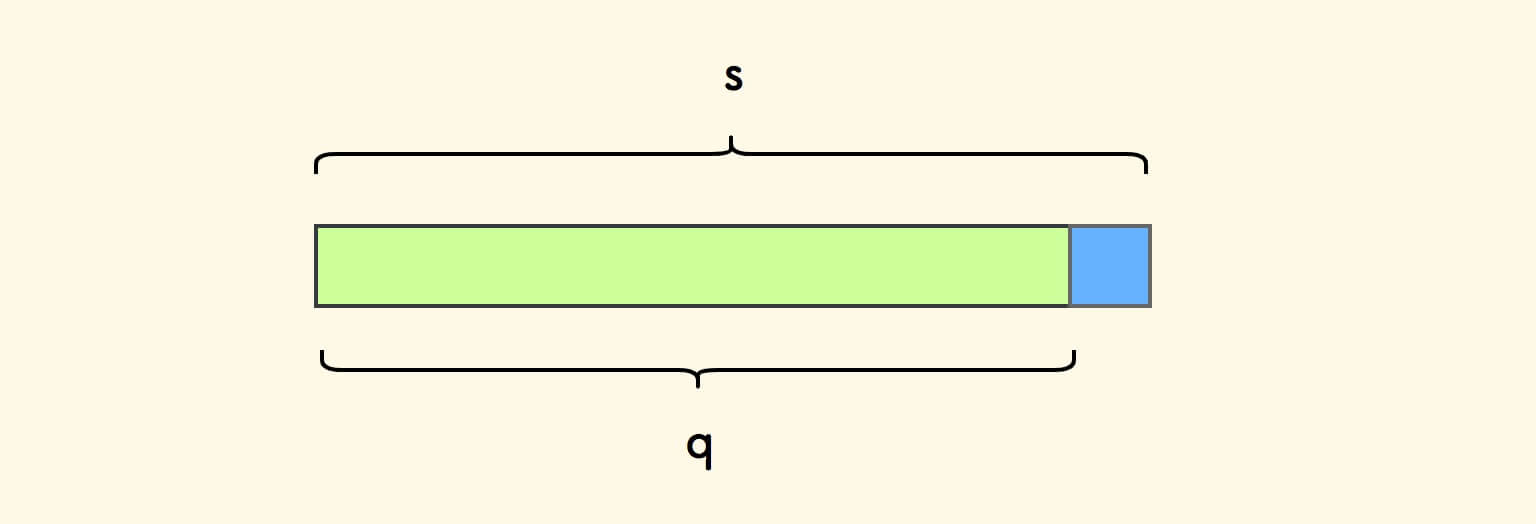
取 c 为 q 的最长前后公共缀。
前后公共缀的意思是,它是既出现在字符串的最前面,也出现在字符串的最后面的真子串 。
举例来说,比如 s 是字符串串 "abcabcabc" ,q 则是 "abcabcab" 。
q 的最长前后公共缀 c 则是 "abcab" 。

将说明,s 是周期串等价于 len(s) 是 len(q)-len(c) 的倍数 。
必要性说明
假设字符串 s 是一个周期串,它由模式串 p 重复多次构成。
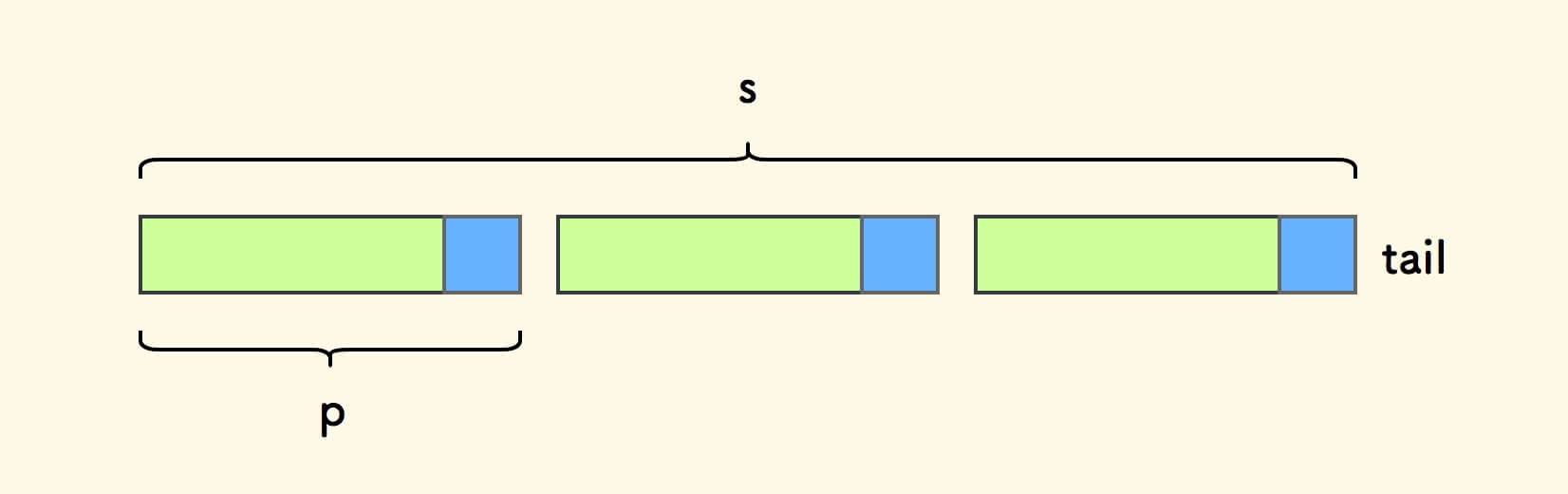
现在, 取 c1 为 q 中剔去一个模式串 p 后的后缀 。
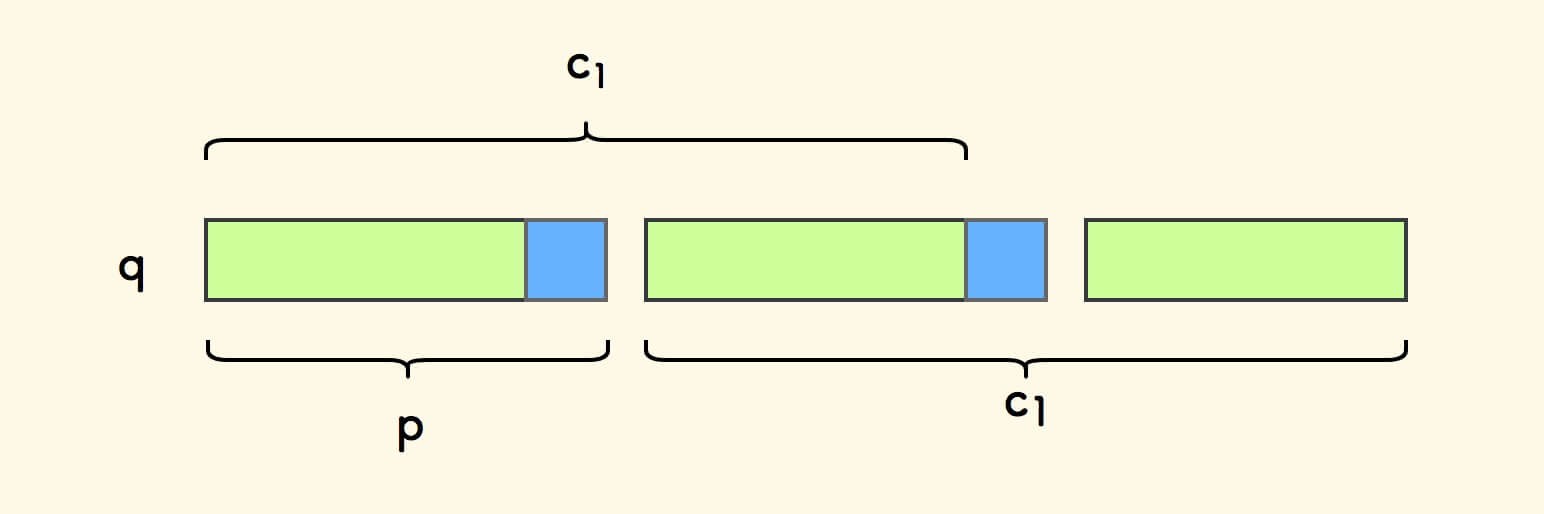
显然,字符串 c1 是 q 的一个 前后公共缀。
比如周期串 "abcabcabc" ,对应的 c1 是 "abcab" 。
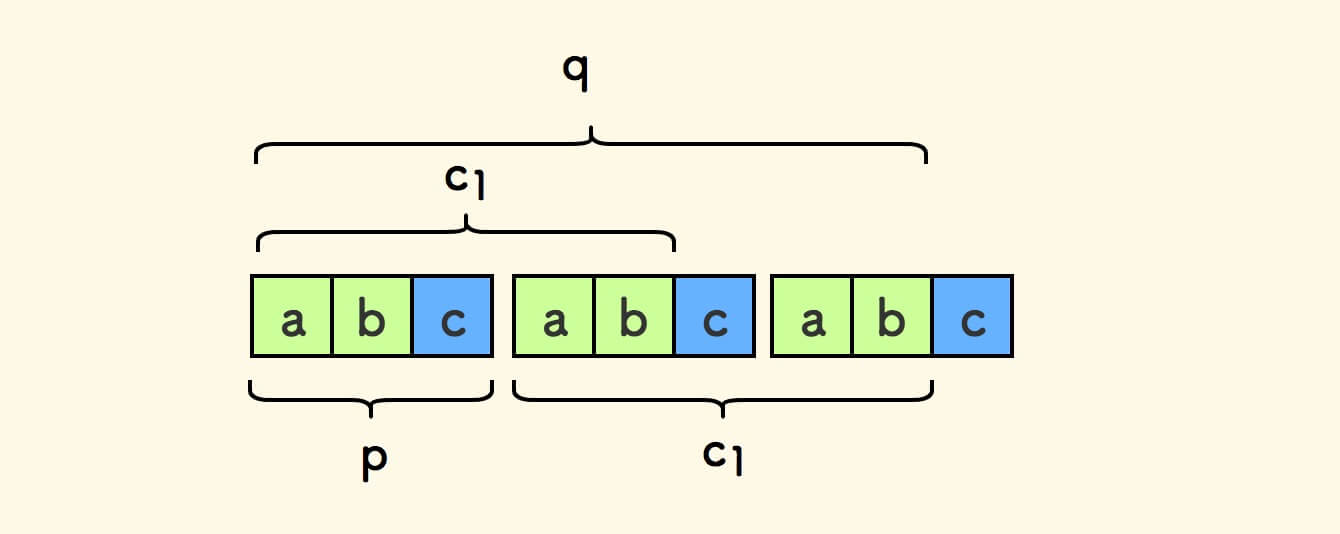
可以证明,c1 就是 q 最长的前后公共缀 c ,详细可展开下面内容。
`c1` 就是 `q` 最长的前后公共缀 `c` 的详细说明
采用反证法,假设存在一个字符串 c' 也是 q 的前后公共缀,而且它比 c1 长一位。
另外,假设尾巴字符叫做 A 。
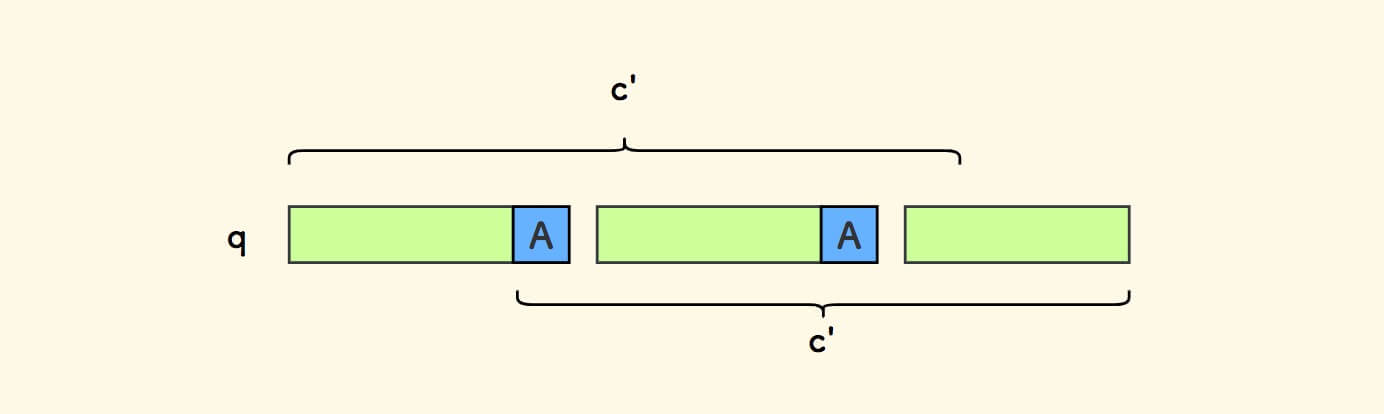
现在有两条性质:
- 周期性质:字符串
s的周期性。 - 前后公共缀性质:
c'是q的前后公共缀。
以下,反复利用此两条性质:
由于「前后公共缀性质」,
q的第一个字符也是A。
由于「周期性质」,后续的循环子串中的第一个字符也是
A。
由于「前后公共缀性质」,
q的第二个字符也是A。
由于「周期性质」,后续的循环子串中的第二个字符也是
A。
如上反复进行,最终,推断整个
q以及s都由字符A构成。
此时的模式串
p即单个字符A。根据 前面的定义 可以知道,此时的
c1如上图,长度是len(q)-1。前后公共缀是真子串,显然,不会存在比它更长的前后公共缀,造成矛盾。





因此,所定义的 c1 就是 q 的最长前后公共缀 c 。
根据 前面的定义 ,可知周期长度是 len(p) = len(q)-len(c) 。
因为字符串 s 是周期串,所以其长度一定是周期长度的倍数。
必要性得到说明。
充分性说明
令 d = len(q)-len(c) , 如果 s 的长度是 d 的倍数,是否 s 一定是周期串?
此时 s 一定可以每 d 个字符一份,切分为整数个小份串:
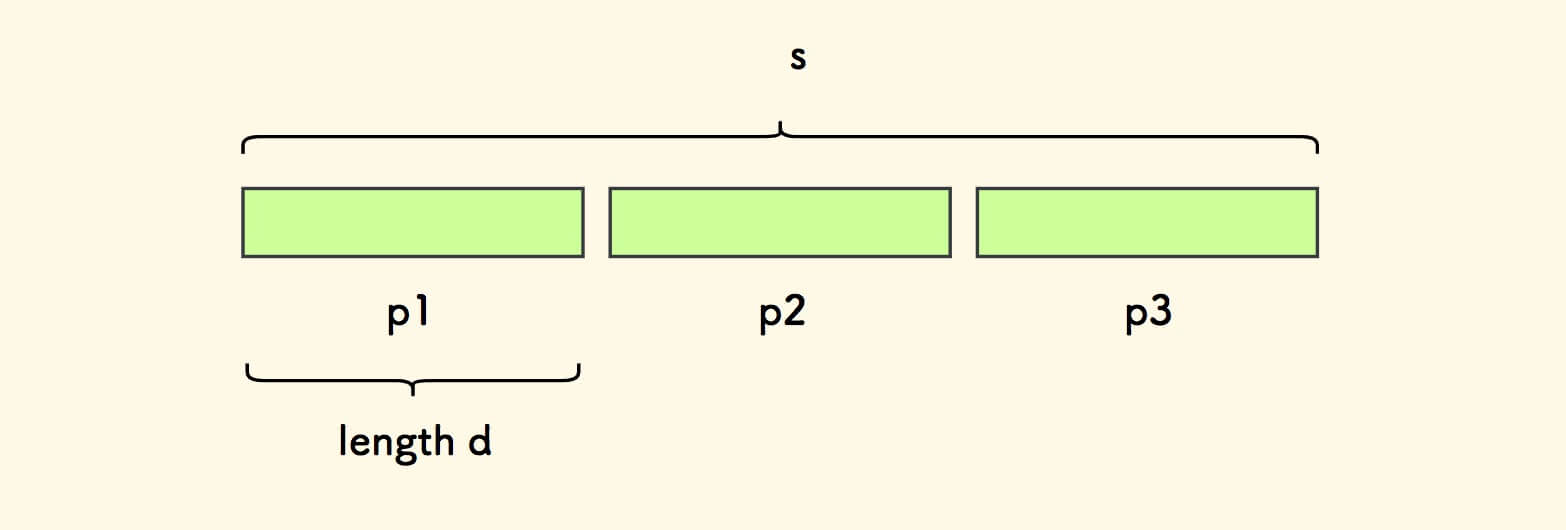
同样假设尾巴字符是蓝色的 A , 剔除尾巴字符后 q 和 其最长前后公共缀 c 如下所示:
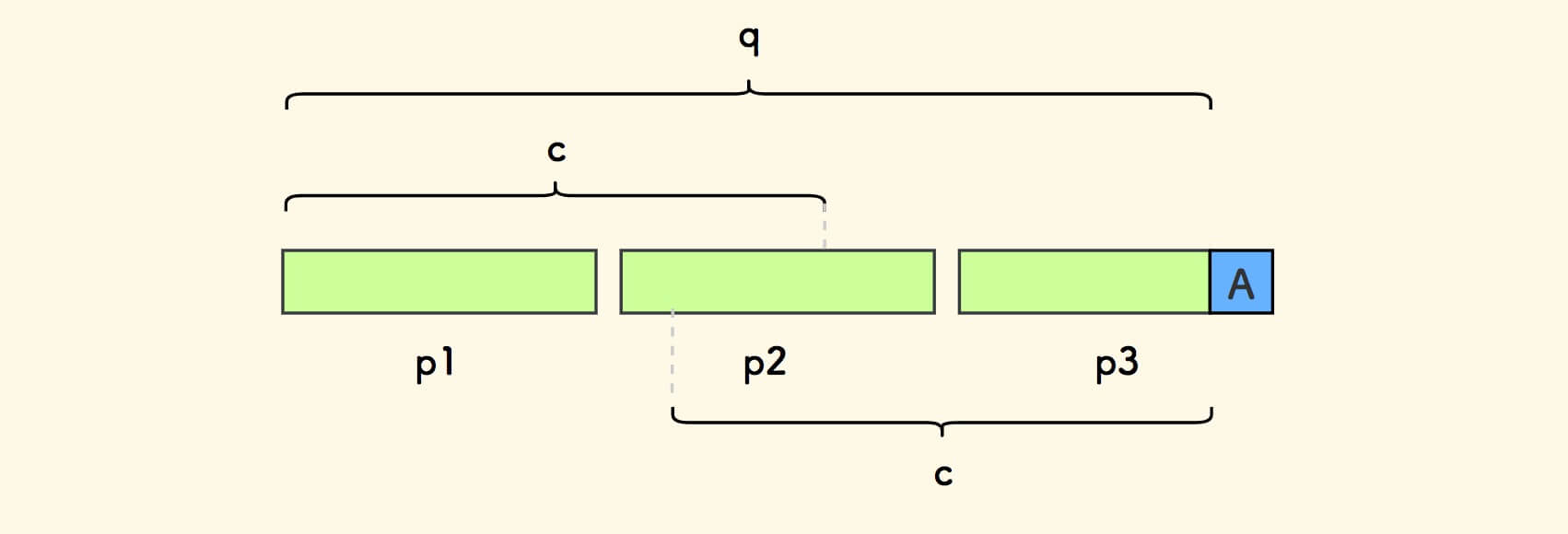
首先,显然 len(c)+1 是 d 的倍数。
`c` 的长度加一是 `d` 的倍数的说明
根据 d 的定义, 得 len(c) + 1 = len(q) - d + 1 。
又因 len(q) = len(s) - 1 ,且 len(s) 可以写作 len(s) = k*d 。
所以 len(c) + 1 = k*d - d = (k-1)*d ,是 d 的倍数。
因此,在下图中, c 必然上下对齐于某个 小份串 的开头。
又因 len(c)+1 = (k-1)*d ,所以 c 就是 q 中剔除第一个小份串 p1 的后缀 。
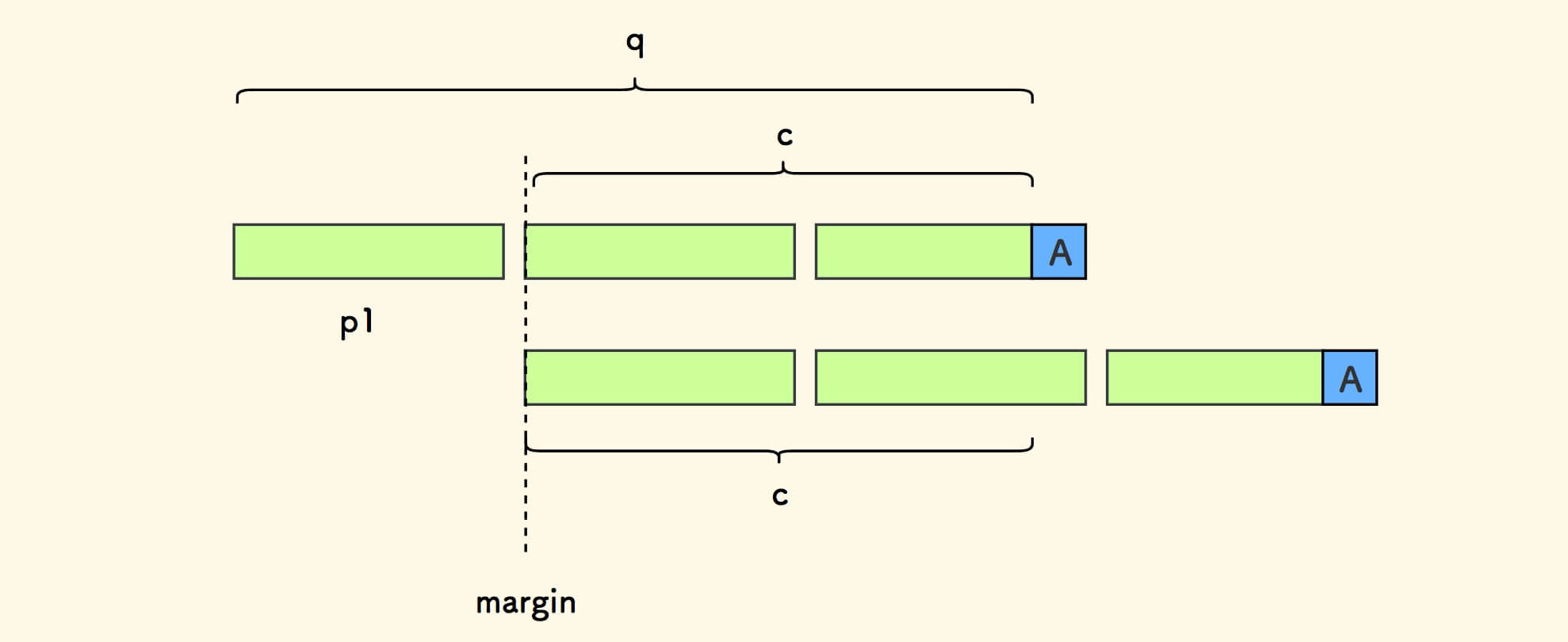
下面将说明,s 是一个周期串。
在最后一个小份串,从尾部取倒数第 j 个字符 B ,反复推演, 可以知道前面的所有小份串的相同位置,都是字符 B 。
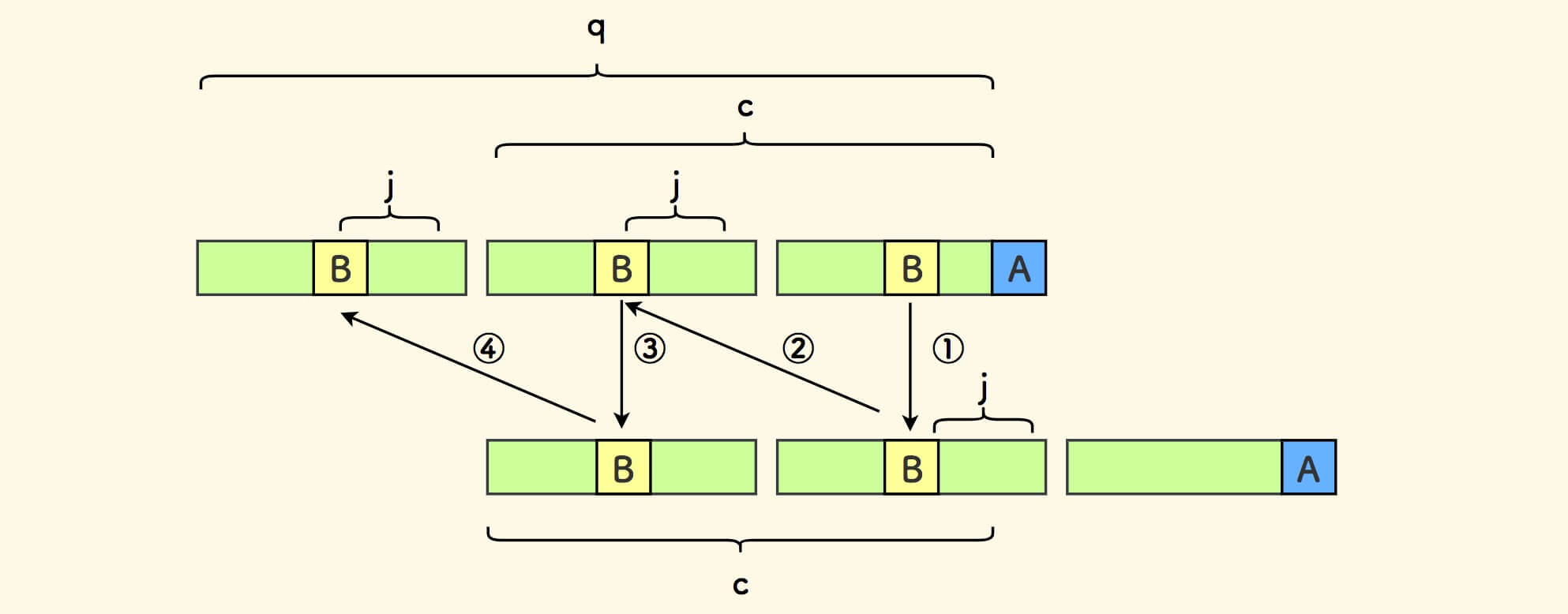
上面的图中:
- ① 号推演,由于上面后缀和下面前缀相等。
- ② 号推演,由于下面的小份串和上面的自身相等。
- 如此,反复进行。
对最后一个小份串上的所有字符, 都会在前面的小份串相同位置重复,那么 s 是一个周期串。
推演的一个细节处理
上面推演中的一个细节是,无法推演小份串的倒数第一个字符。
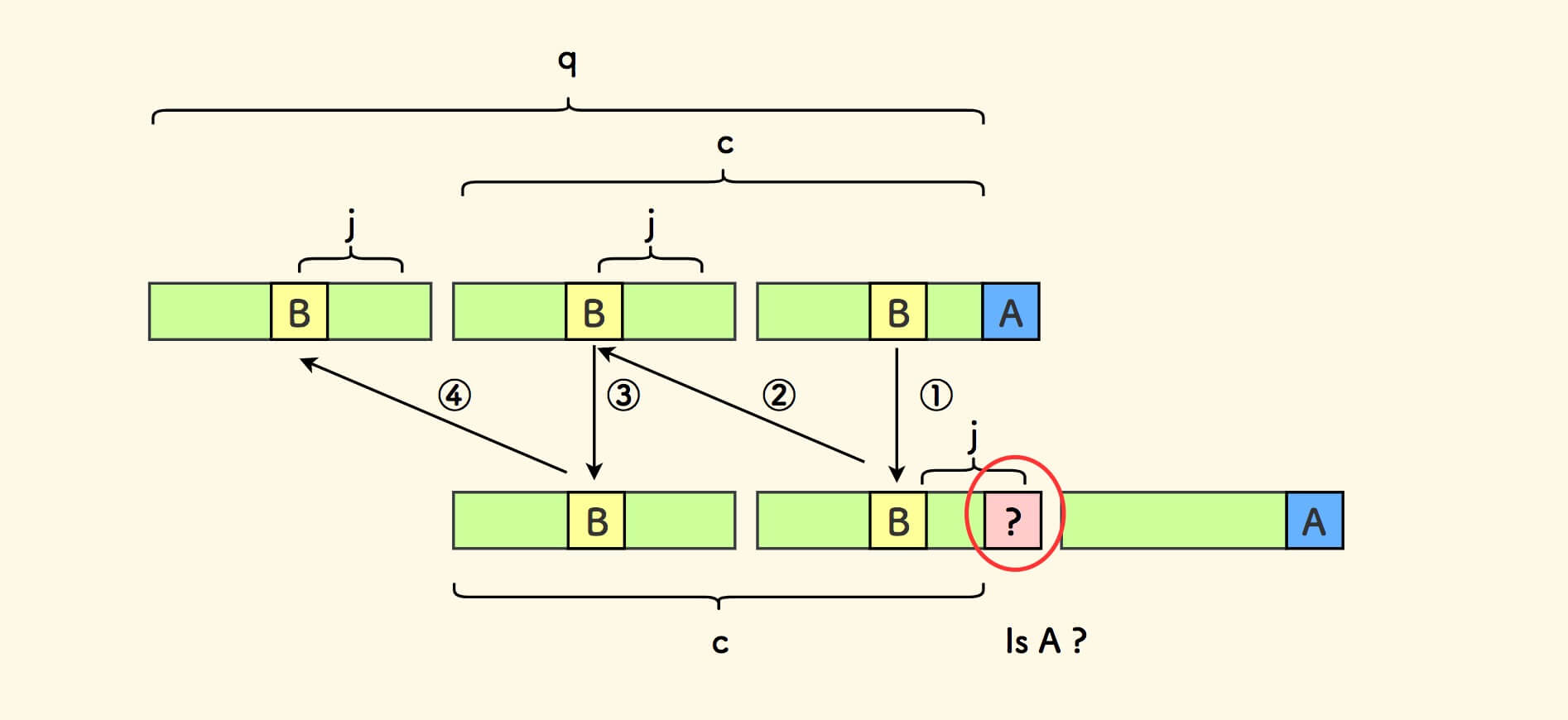
原因在于,尾巴字符不在最长前后公共缀的范围内。
细节处理就是,需要判断一次尾巴字符 A 是否和 上一个小份串对应位置的字符相等。
一旦此细节满足,即可完成整体推演过程,s 就一定是一个周期串。
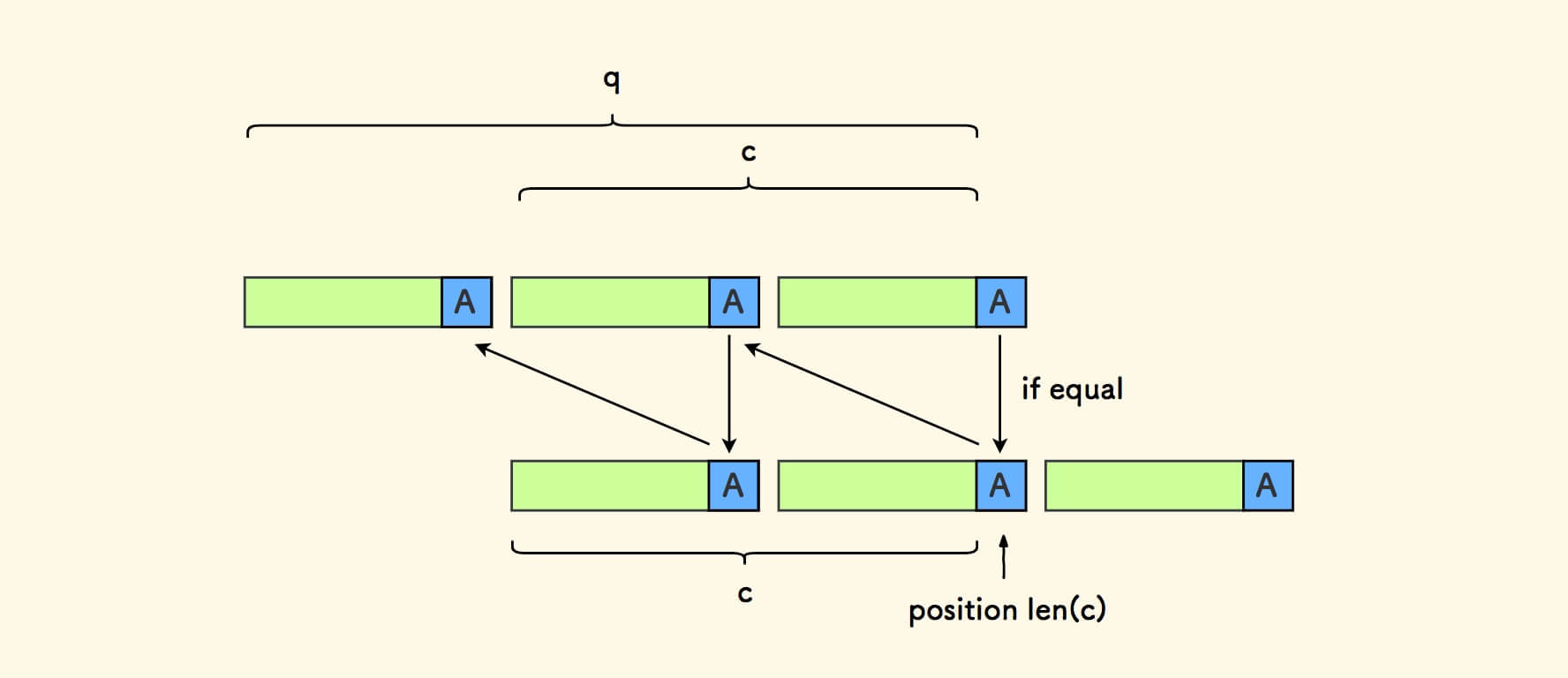
至此,充分性也说明完毕。
KMP 算法求解
KMP 算法中的 Next 数组 的含义就是前后公共缀的长度 ,即 len(c) = next[n-1] 。
周期串判断 - KMP Next 数组方法 - C 语言实现
// 同 KMP 的 Next 数组
// https://writings.sh/post/algorithm-string-searching-kmp
void ComputeNext(char *s, int n, int next[]) {
if (n > 0) next[0] = 0;
if (n > 1) next[1] = 0;
for (int j = 2; j < n; j++) {
char ch = s[j - 1];
int k = next[j - 1];
while (k != 0 && s[k] != ch) k = next[k];
next[j] = 0;
if (s[k] == ch) next[j] = k + 1;
}
}
// 判断 s 是否是周期串模式
bool IsStringRepeatedPattern(char *s) {
int n = strlen(s);
if (n == 0) return false;
int next[n];
ComputeNext(s, n, next);
// s[0:n-1] 的最长的前后公共缀长度
int c = next[n - 1];
// 预期的周期长度
int d = (n - 1) - c;
if (d > 0 && s[c] == s[n - 1] && n % d == 0) return true;
return false;
}
由 KMP 算法预处理的时间复杂度 可知,此方法的时间复杂度是 O(n) ,空间复杂度是 O(n) 。
(完)
相关阅读: KMP 字符串匹配算法
本文原始链接地址: https://writings.sh/post/algorithm-repeated-string-pattern
