Boyer–Moore 算法 是用来在字符串中搜索一个子字符串的算法,也简称 BM 算法。
本文内容较多,需要读者静心阅读。
内容目录:
问题 ¶
在长度为 n 的字符串 s 中搜索长度为 m 的子串 p 的位置。
本文以 ABCDABEABDCBCDDBBCDBACD 为主串 ,BCDBACD 为子串,作为用例。
算法过程 ¶
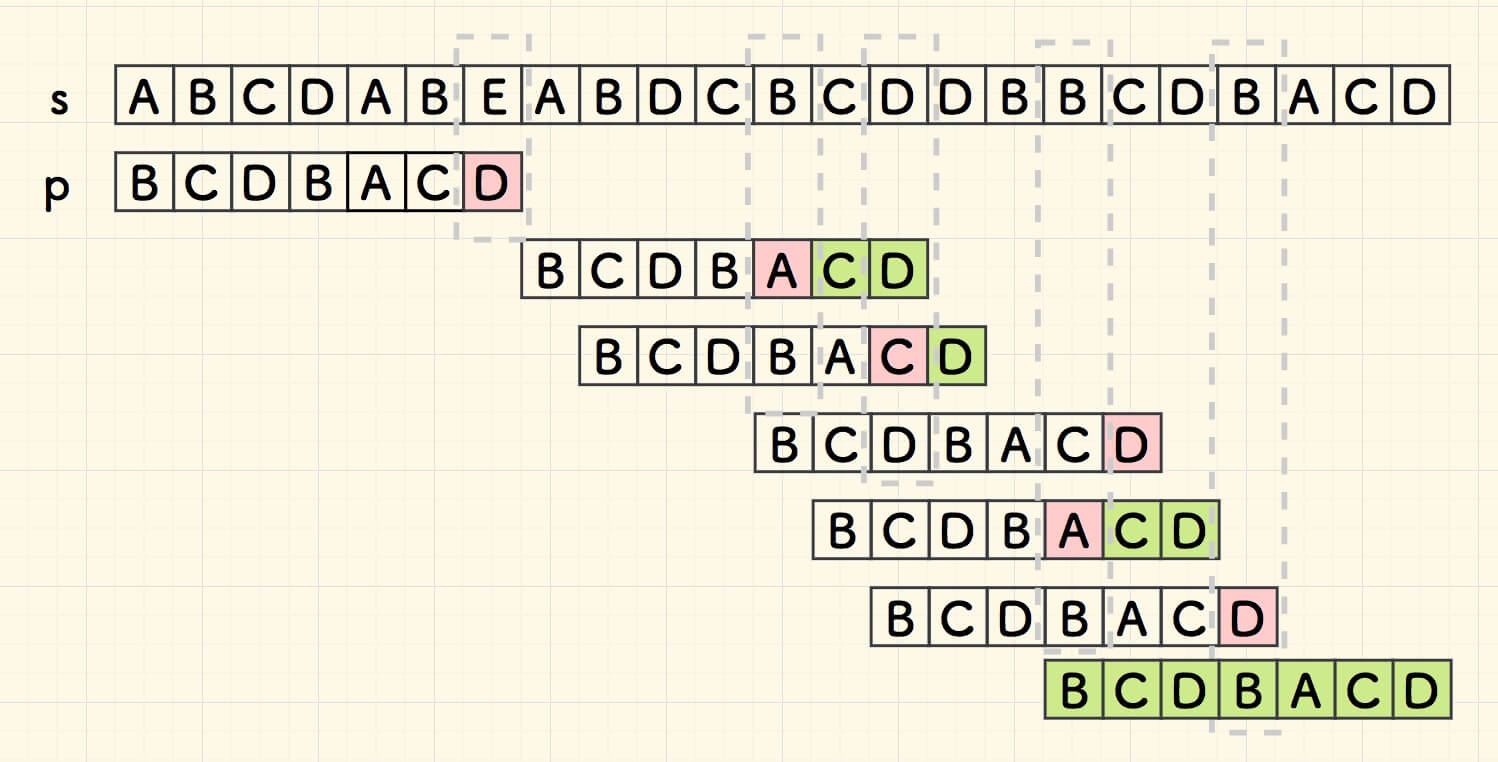
首先将两个字符串左对齐,对子串 p 进行 自右向左 的逐一比对。
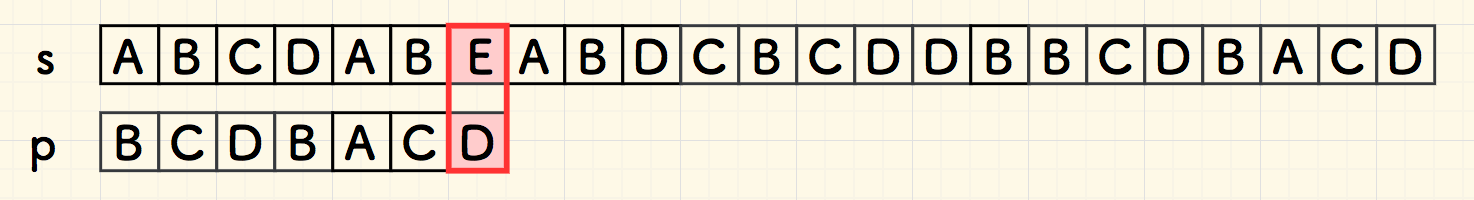
第一次比对,即在字符 E 失配。 由于 E 不在子串 p 中,因此,可以直接把整个子串右移到其右边。
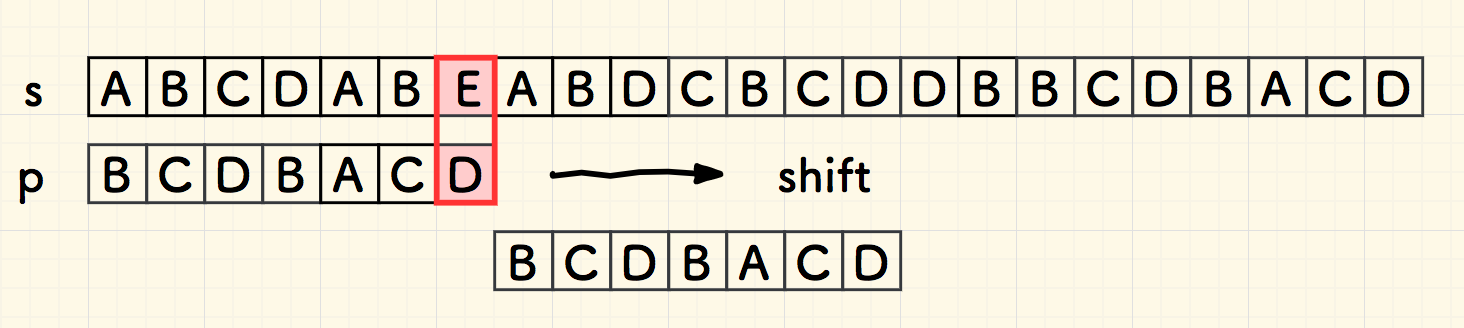
继续向前匹配,此时在下图 1.3 中的红色部分失配。

但是,失配的 B 在子串 p 中,就在当前位置靠左一位的位置。 要想子串和主串在附近匹配成功,至少字符 B 要对的齐。 为了避免错过 B 的匹配,只能找到靠的最近的 B 对齐,也就是右移一位。
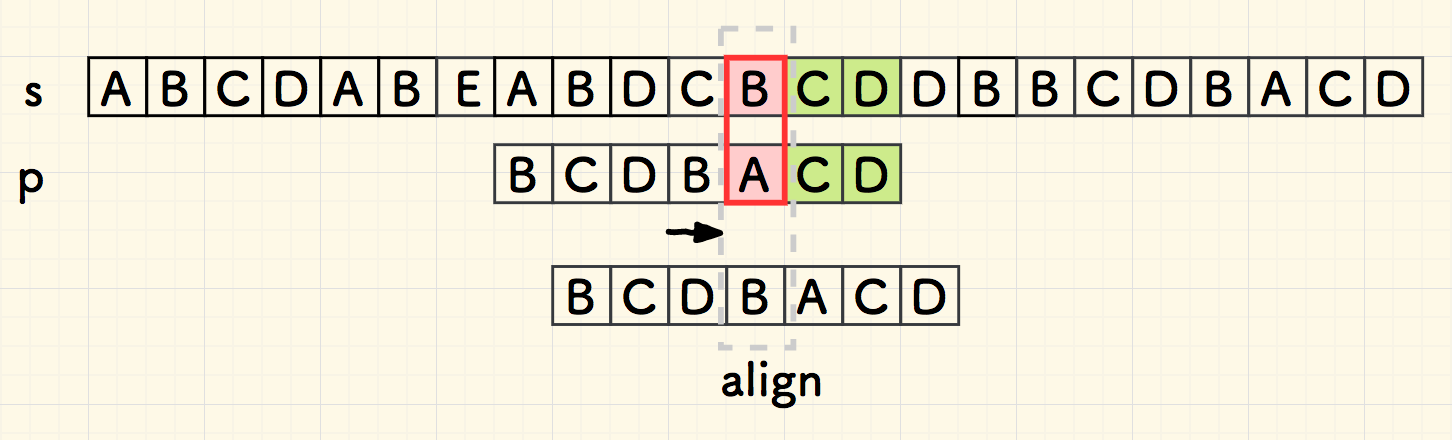
回到子串的尾部,自右向左,继续匹配,在下图中的红色部分失配。

沿用刚才上面的思路,失配的 D 也在子串中,右移 p ,让它们对齐:
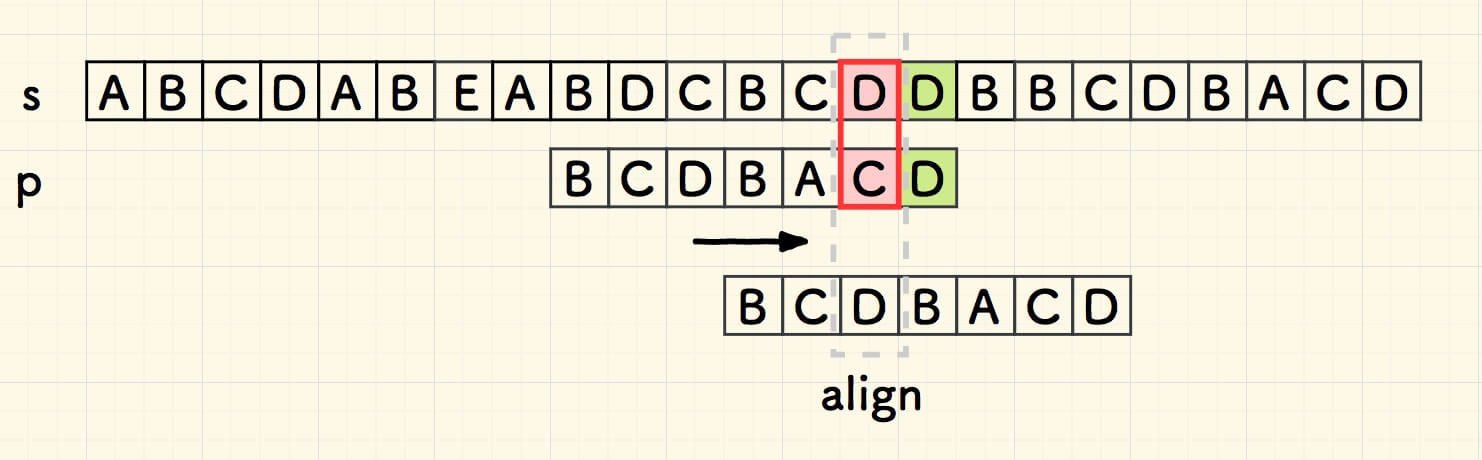
总结出来规律了, 当失配的时候,右移子串,使得主串中失配的字符和子串中左边最近的相同字符对齐。如果不存在相同字符,就把整个子串右移到失配字符的右侧。
坏字符的办法 ¶
常把失配处主串中的字符叫做「坏字符」,每次右移,就要把 坏字符和子串中最近的坏字符对齐。
Boyer–Moore 算法和 KMP 算法 的思路类似,都是在失配处动脑筋,跳过无必要的比对,以加快搜索。
按这个思路,可以继续匹配下去,直到命中。
好后缀的办法 ¶
上面坏字符的办法,还不够快。
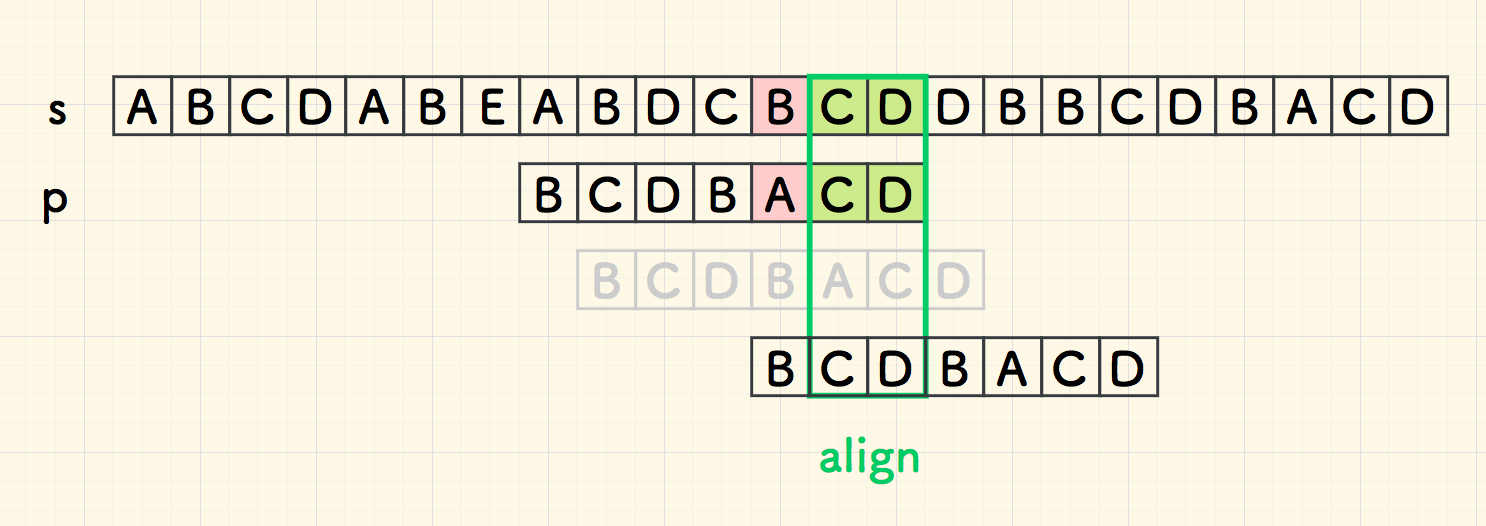
比如下面这次对齐:

此时,已知的信息是,主串中有已经匹配好的 CD ,它同时也是子串 p 的后缀,常叫做「好后缀」。
要想子串在附近和主串匹配成功,它们的共同子串 CD 就要对的齐,所以,把对齐坏字符的办法应用到好后缀上, 找到最近的好后缀进行右移对齐。
如此一来,右移的更多了些。
好后缀的办法就是, 失配时,右移子串,使得主串中的好后缀和子串中左边最近的重复串对齐 。 同样的,如果存在好后缀,而左边没有重复串时,那么直接把 p 右移到整个好后缀右边就好了。
综合两个办法后,整个搜索过程优化为下面的样子,总体上比只用坏字符的办法,少了两步。
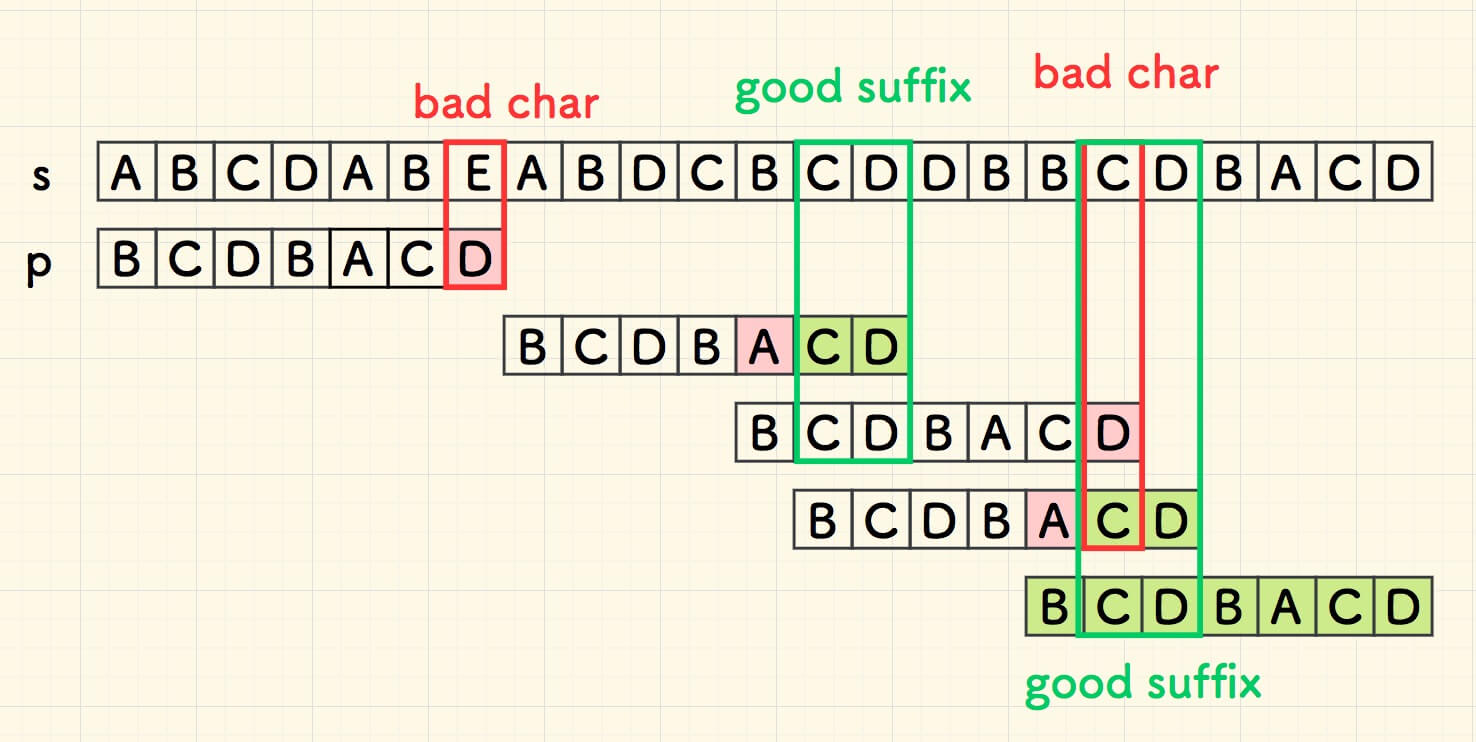
当存在好后缀的时候,由于其长度比坏字符要小,所以一般的,在子串的左边出现的概率相对更低。因此,优化效果更明显, 但不尽然。综合使用时采用右移距离更大的一个 。
编码思路 ¶
假设,主串和子串的迭代变量分别是 i 和 j 。
先考虑失配时两个迭代变量如何跳转的问题。
在失配时,显然, 子串回到尾巴,即 j → m - 1 。
关键是计算失配时 i 的迭代量。
坏字符的办法
先考虑坏字符的办法。遇到一个坏字符的时候,假设子串中左边 最近的 坏字符到子串尾巴的距离是 d。
从下图可以推断出主串的迭代量就是 d:
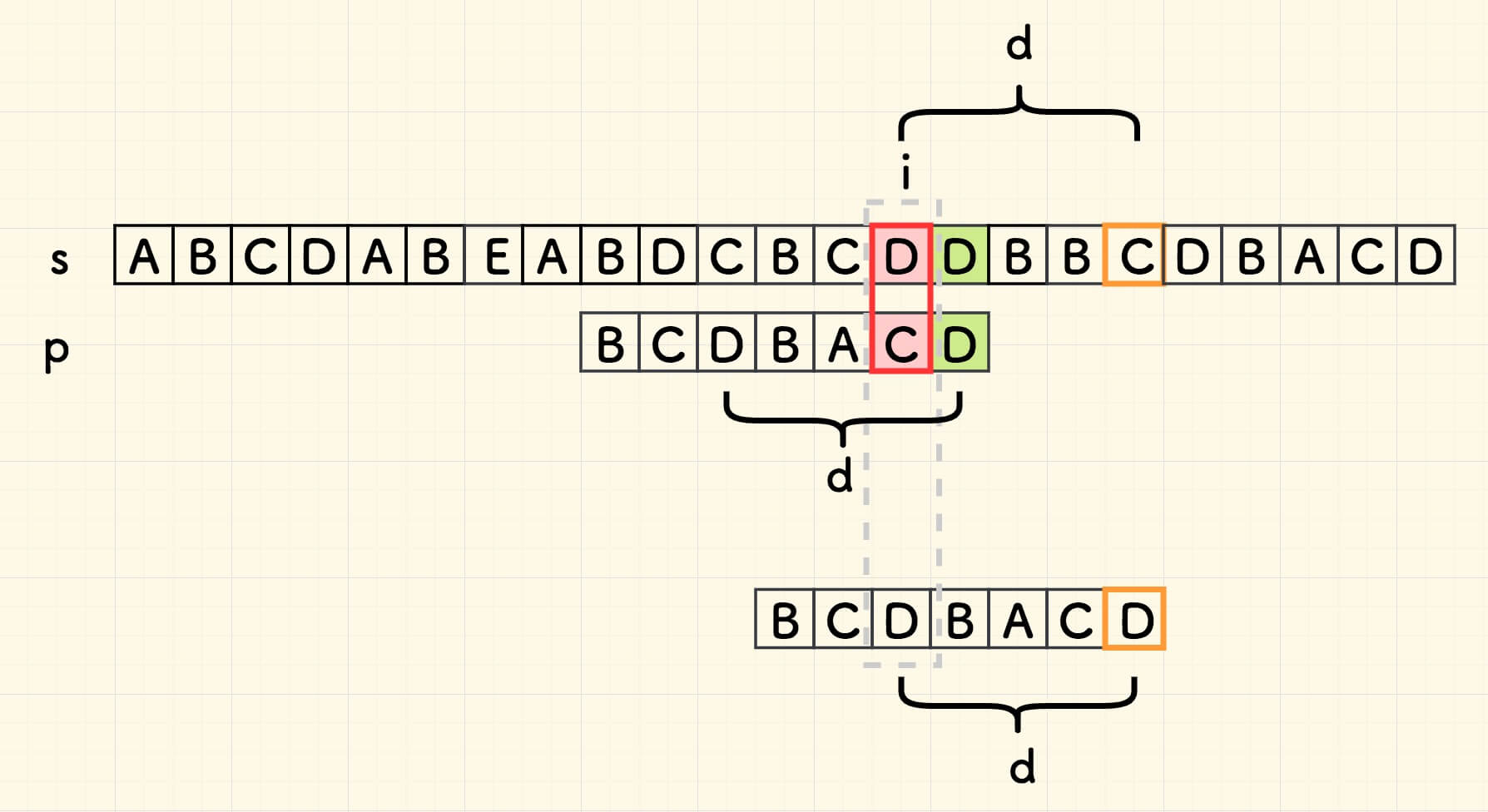
特殊地,坏字符在子串左边不存在时,会跳过整个子串的左边部分, 主串迭代的量应是子串长度 m ,则取 d = m 来满足。 例如下图中,坏字符 C 在子串左部没有出现,则跳过左边的 DDB ,主迭代变量的跳转量就是子串长度 d=m 。
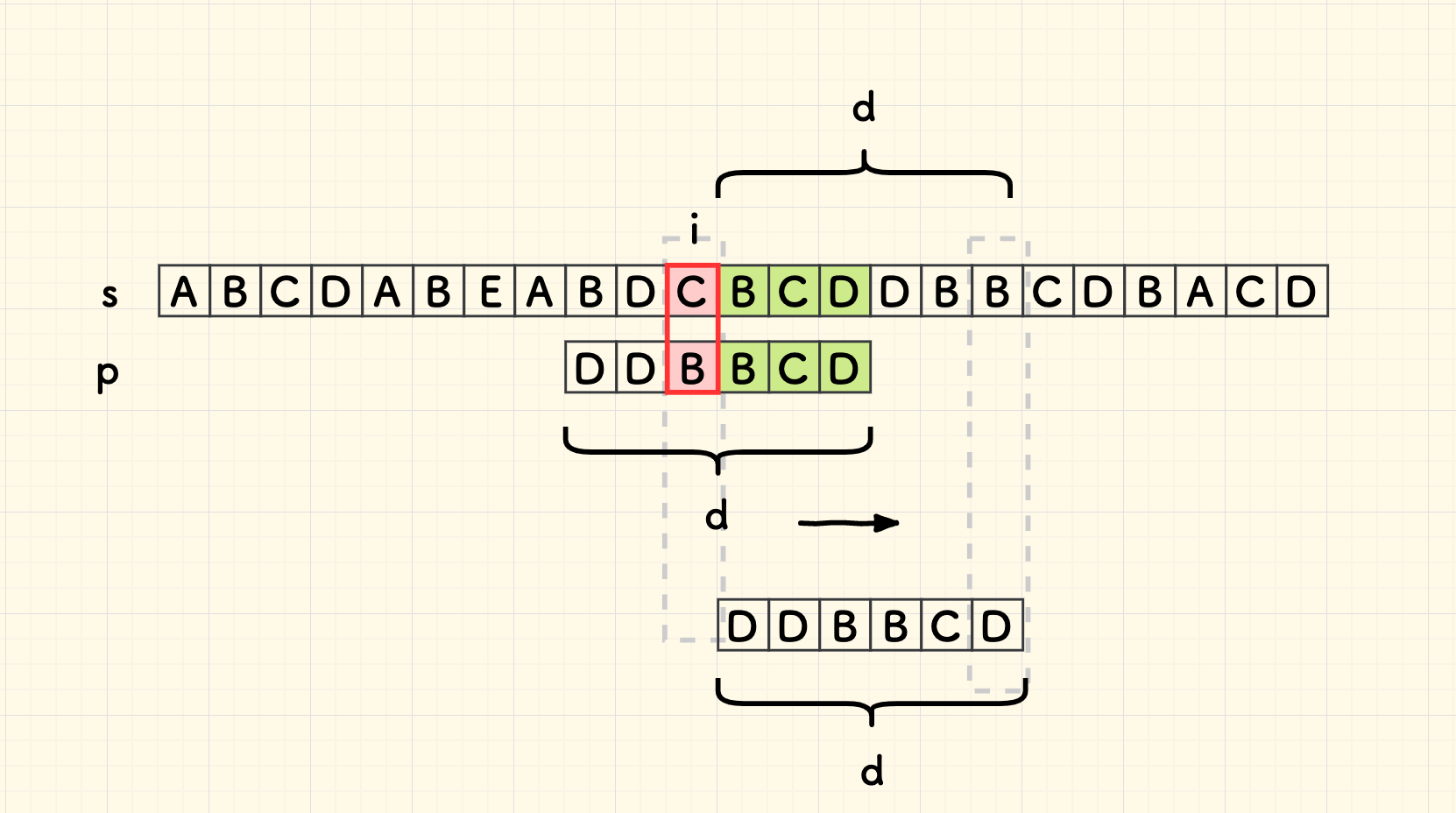
我们可以进一步总结规律, 主串迭代量 d 其实是: 坏字符在子串失配位置左侧 最靠右的出现位置、到子串尾巴的距离。 如果没找到,自然地,就是子串的长度。
也可看出,主串迭代量 d 其实只和子串相关,和主串无关。
此外,很容易知道,主串的迭代量 d 肯定大于失配位置到尾部的距离,也即不小于 m-j (j 是失配时子串当前的位置) 。
好后缀的办法
对于好后缀的办法,道理是相似的 。
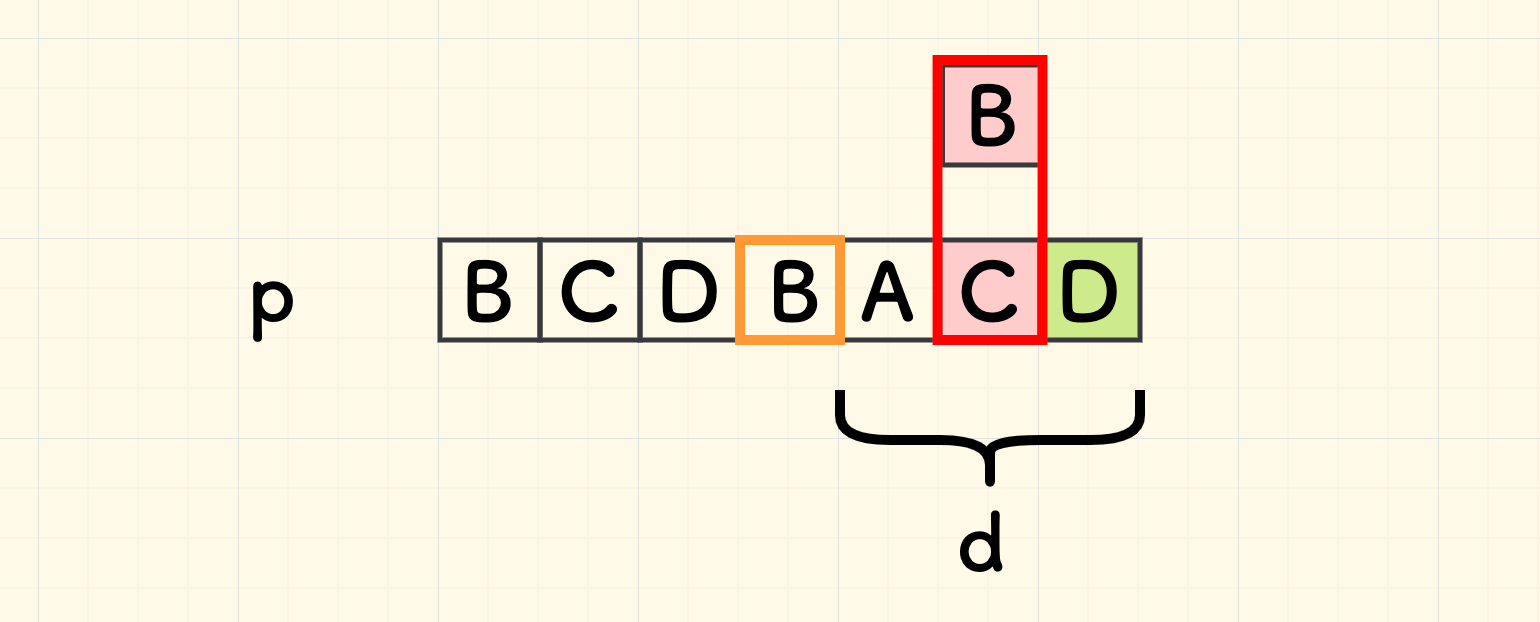
把拿来对齐的左边的重复串叫做 repeat, 把对齐好后缀的过程,看作对齐 repeat 前面那个字符的过程,即可复用上面的思路。 如此一来,假设 repeat 前面字符到尾巴字符的距离是 d ,则失配的时候,主串的迭代量就是 d。
进一步地,若假设重复串 repeat 的头部的位置是 t 的话, d 其实是 m - t 。
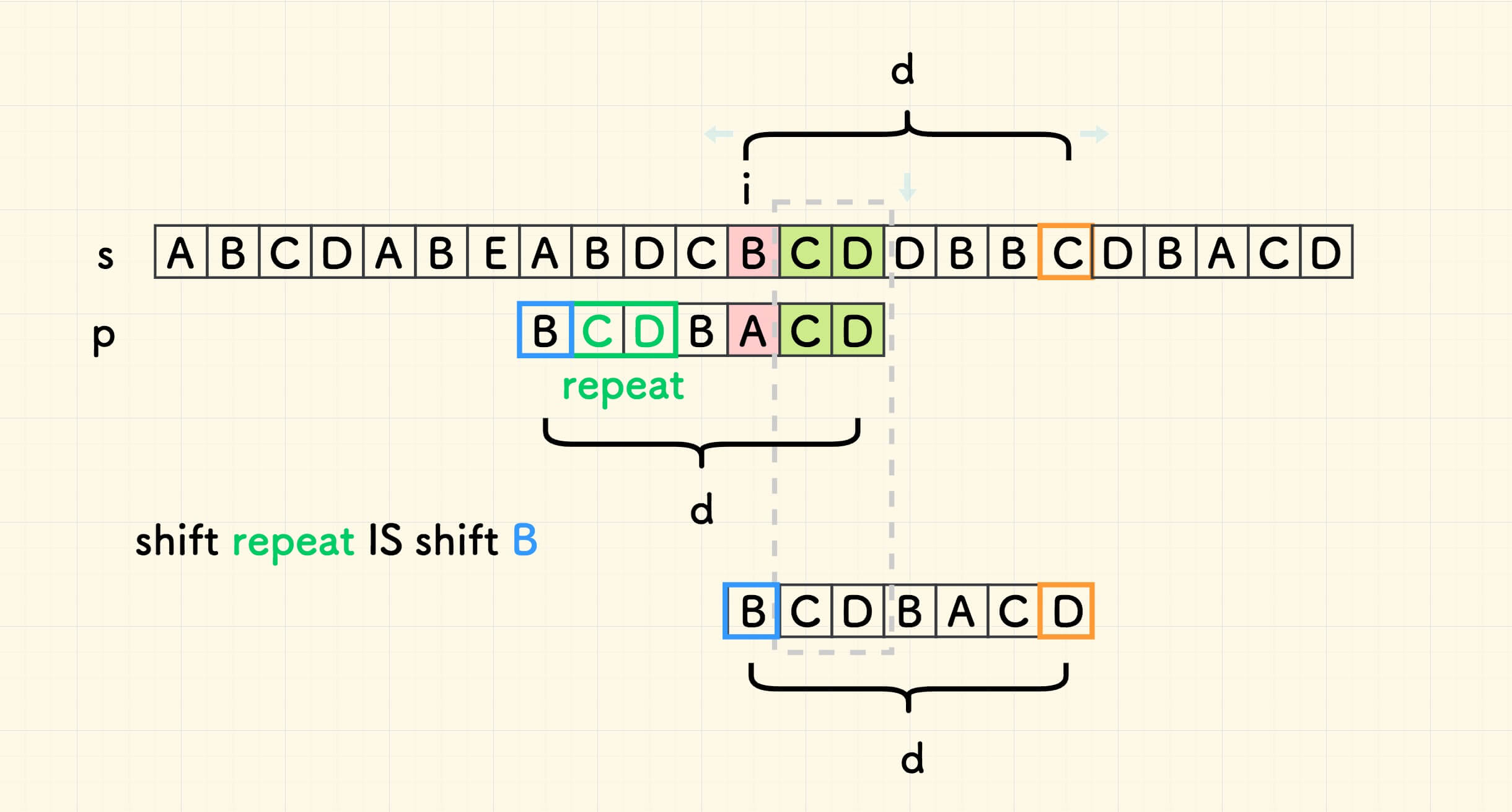
如果重复串 repeat 在 p 的开头,前面没有字符,此时主串的迭代量是 m,而 t 恰好是 0 ,仍然满足 d = m - t 的关系。 下面的图 2.4 构造了这种情况 (为说明问题,对本文用例稍加改造):
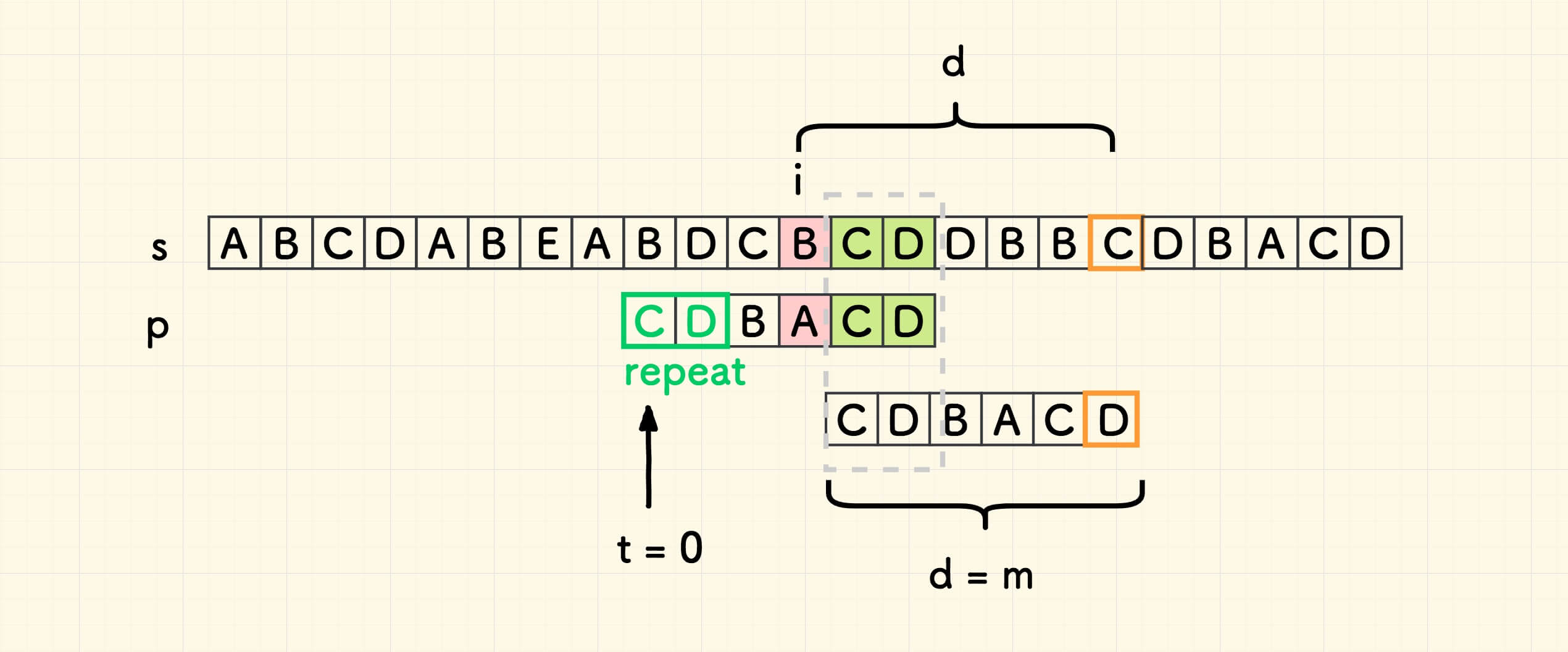
但是,如果重复串 repeat 在 p 的左边不存在,情况变得复杂起来,分情况讨论:
好后缀部分匹配到了
p的一个前缀下图 2.5 构造了这一种情况,此时应该右移到对齐 「匹配到的部分」。
在下图中需要对齐绿色的
CD。 可以看到此时的主串迭代量d比搜索串的长度m要大。
图 2.5 - 好后缀部分匹配到子串的前缀的情况 为了进一步找出计算公式,可以虚假地构造一部分前缀
fake,即可套用 完全匹配到开头 的情况。
图 2.6 - 构造虚拟前缀来套用完全匹配的情况 可以看到,
d = m + len(fake),实际即是m + len(suffix) - len(prefix)。好后缀在
p的左边完全没有匹配上主串迭代量
d则是m + 好后缀长度。下图 2.7 构造了这一种情况。可以看到,这是第一个情况,即 部分匹配前缀 的一种特例。

图 2.7 - 好后缀和搜索串完全失配的情况



总而言之,好后缀的办法,分为两种情况:
- 好后缀在左边:
d = m - t - 好后缀不在左边:
d = m + len(suffix) - len(prefix)
此外,也容易知道,主串的迭代量 d 肯定不小于 m-j (j 是失配时子串当前的位置) 。
事实上,无论坏字符的办法、还是好后缀的办法, 失配情况下,主串的迭代量是与主串无关的 。
坏字符表 ¶
前面所说的 主串迭代量 d 其实可以预处理成为一个表格, 包括两个维度:
- 行: 主串中的字符
- 列: 子串失配的位置
下图是预处理好的表格,问号表示不在子串中出现的其他字符,m 是子串的长度:
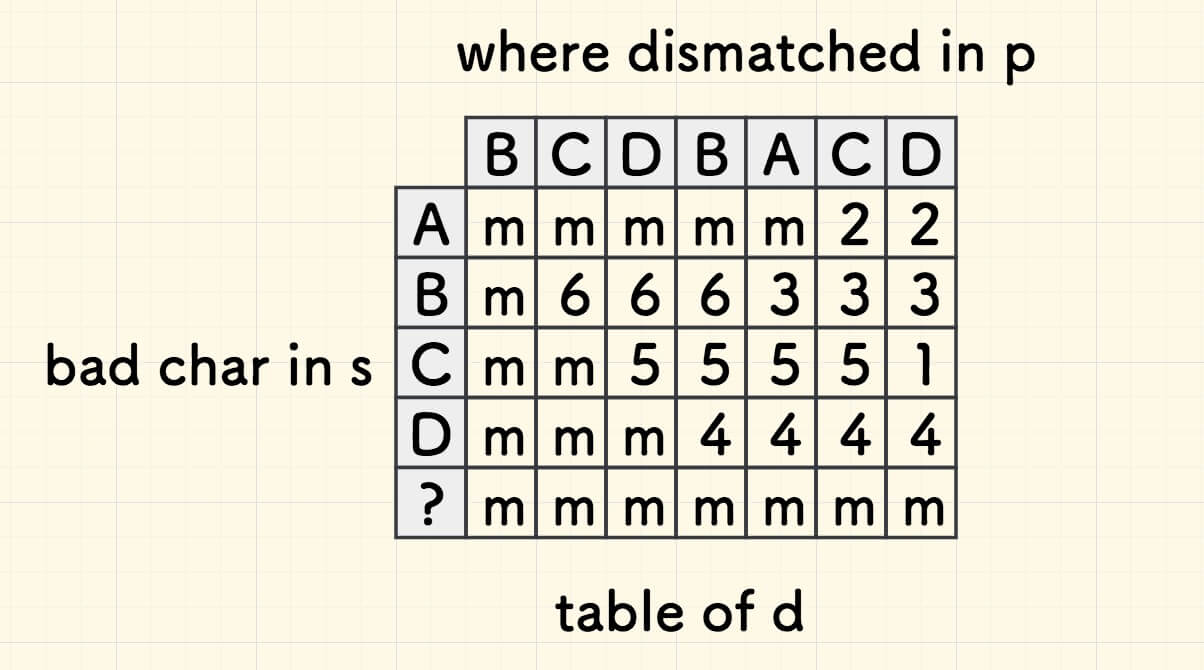
假设字符集的大小是常量 S (一般取 ASCII 表 的大小 256, 这个表格最多就有 256 行)。 第 x 行、第 k 列的元素的含义就是,在子串位置 k 处失配的坏字符 x 对应的主串迭代量 d 的值。
事实上,此表格可以用 归纳的方法,以 O(S * m) 的线性时间复杂度计算得出。
其方法是, 假设当前格子对应的子串失配的字符是 p[k] ,自上而下,自左而右地填表。
首先,回顾前面的总结,在子串首字符处失配,左侧无任何字符,所以第一列全部填写 m 。
可以再次回顾下 前面总结的规律,接下来进行归纳递推:
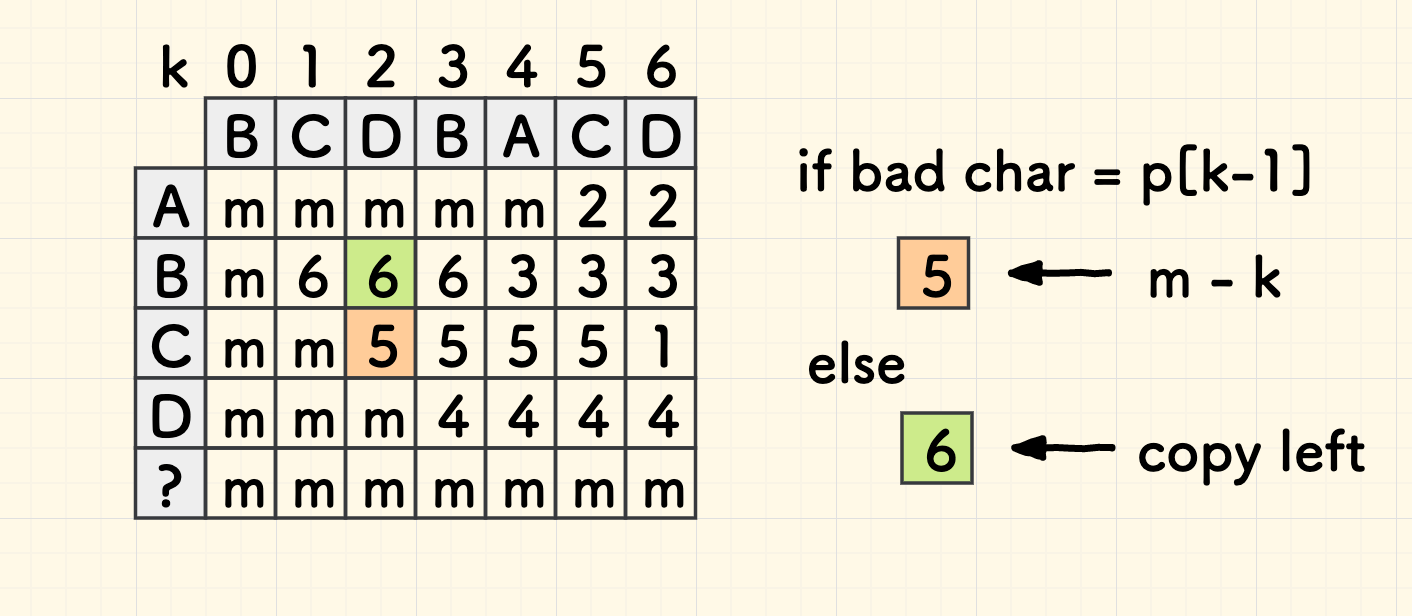
如果「坏字符」等于失配处的前一个字符
p[k-1]的话,则一定取得更短的d,填入m-k。 因为失配处左侧这个字符一定最靠右、是离子串尾部最近的了。
否则,如果坏字符和失配处左边的字符不匹配,
d的含义是坏字符在失配处左侧距离子串尾部的最短距离。 那么d的值并无变化。可以直接拷贝当前格子左边格子的数值。


最终的填表方式如下图所示:
这个表格的空间占用则是 O(S * m) ,代码实现如下:
C 语言实现 - 填写二维坏字符表
#define S 256
// ComputeBadCharTable 计算二维坏字符表
void ComputeBadCharTable(char *p, int m, int table[S][m]) {
// 初始化第一列为 m
for (int x = 0; x < S; x++) {
table[x][0] = m;
}
// 填表
for (int x = 0; x < S; x++) {
for (int k = 1; k < m; k++) {
if (x == p[k - 1])
table[x][k] = m - k;
else // Copy left
table[x][k] = table[x][k - 1];
}
}
}
另外,Boyer-Moore 算法 - 维基百科 中也确有指出 创建二维坏字符表的方法, 并且有给出使用二维坏字符表的 Python 实现。
实际中,大多数的编码实现都只取最后一列,即只用一维表格,这样空间占用更小。 例如,Golang 官方的字符串搜索 采用 Boyer-Moore 算法,构建的是一维坏字符表。 此时,表格含义即退化为:所有字符在剪去尾巴外的子串中最右侧出现的位置、距离尾巴字符的距离。
形象点说:所有字符在下图中黄色字符串中最后一次出现的位置(绿色框)、距离子串尾部的距离,构成的一维表格。 排除尾部字符 (灰色的 D) 的原因是,它本来就不会成为「失配时左侧的字符串中的一员」。
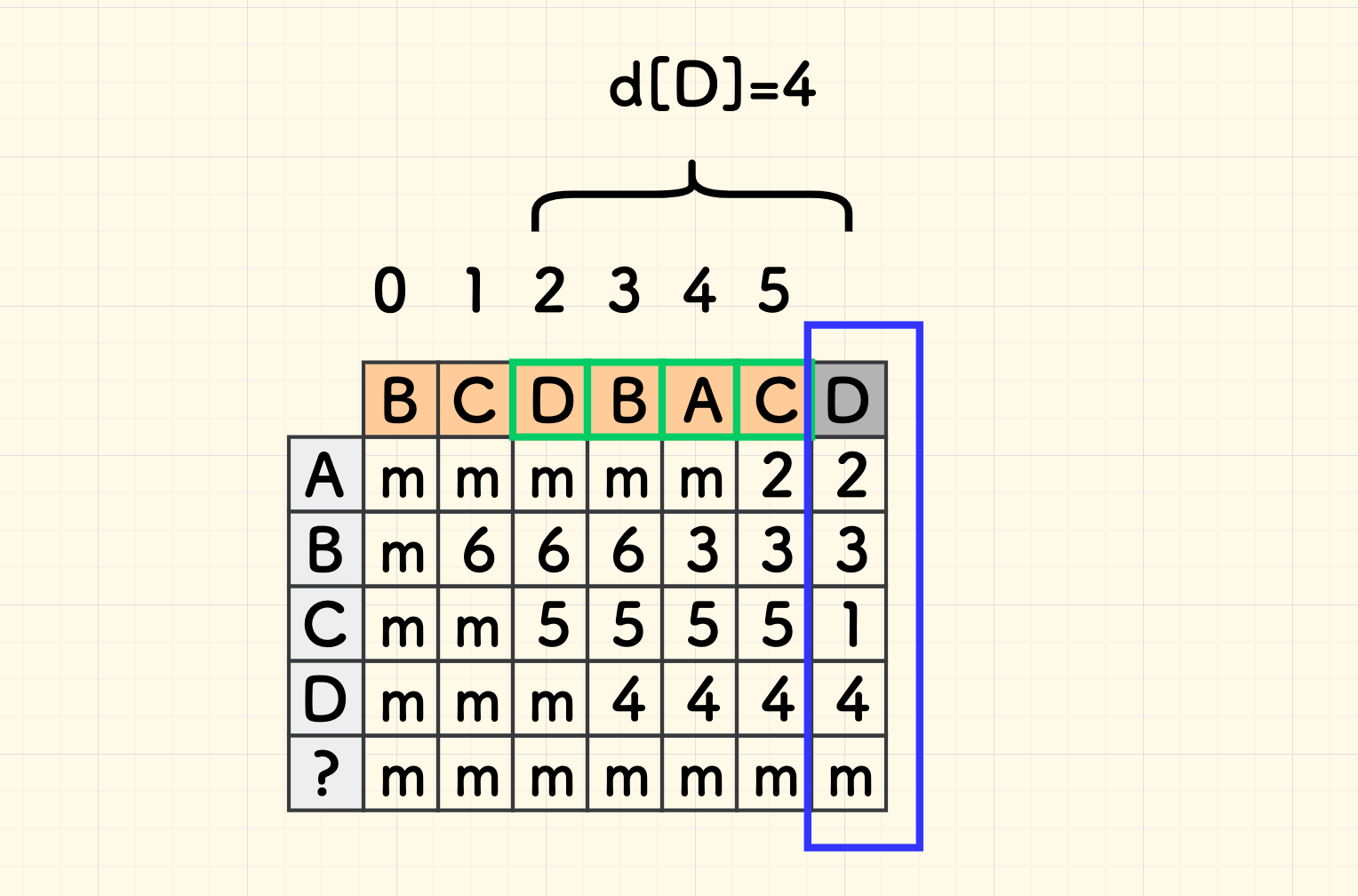
同时,构建坏字符表格的方法也会更简单:
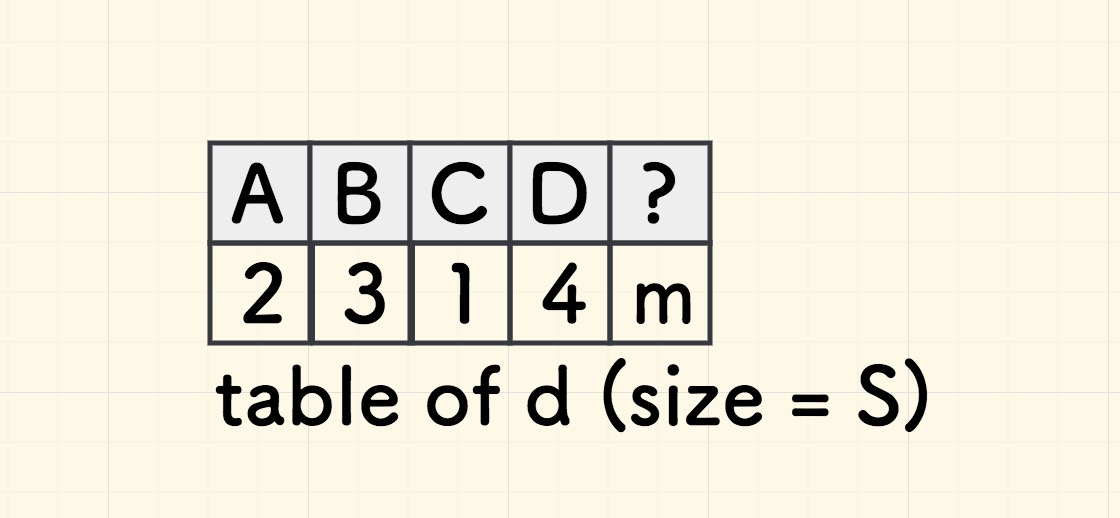
- 初始化一维表格
table的每一项是m。 假设
p的尾巴字符的位置是last = m-1:对尾巴左边的每个字符
ch = p[k],不断覆盖table[ch] = last-k即可。注意排除最后一个字符,即
k<last而不是k<=last, 因为尾巴字符左边的字符才有可能成为坏字符的对齐目标。
一维的坏字符表格如下所示:
C 语言实现 - 填写一维坏字符表 (退化情况)
// ComputeBadCharTable 计算一维坏字符表
void ComputeBadCharTable(char *p, int m, int table[]) {
// 初始化每一个字符的坏字符表值为 m
for (int i = 0; i < ALPHABET_SIZE; i++) {
table[i] = m;
}
// 对尾巴左边的字符,不断覆盖它到尾巴 last 的距离
// 坏字符的对齐目标绝不在尾巴字符上。
int last = m - 1;
for (int i = 0; i < last; i++) {
char ch = p[i];
table[ch] = last - i;
}
}
从构造二维表格的方法上看,右侧的列一定不会比左侧的列的值大。 所以,最后一列的主串迭代量不会比原本的大, 也就不至于错过匹配点。
但是,采用一维坏字符表时,太小的主串迭代量可能会导致匹配回溯,引发无限循环。
下图的例子中,在字符 C 处失配时,主串前进过小,同时 j 跳回尾部,导致下一次对齐实际是回溯左移了。这样就可能回到之前的某个状态上,引发死循环。
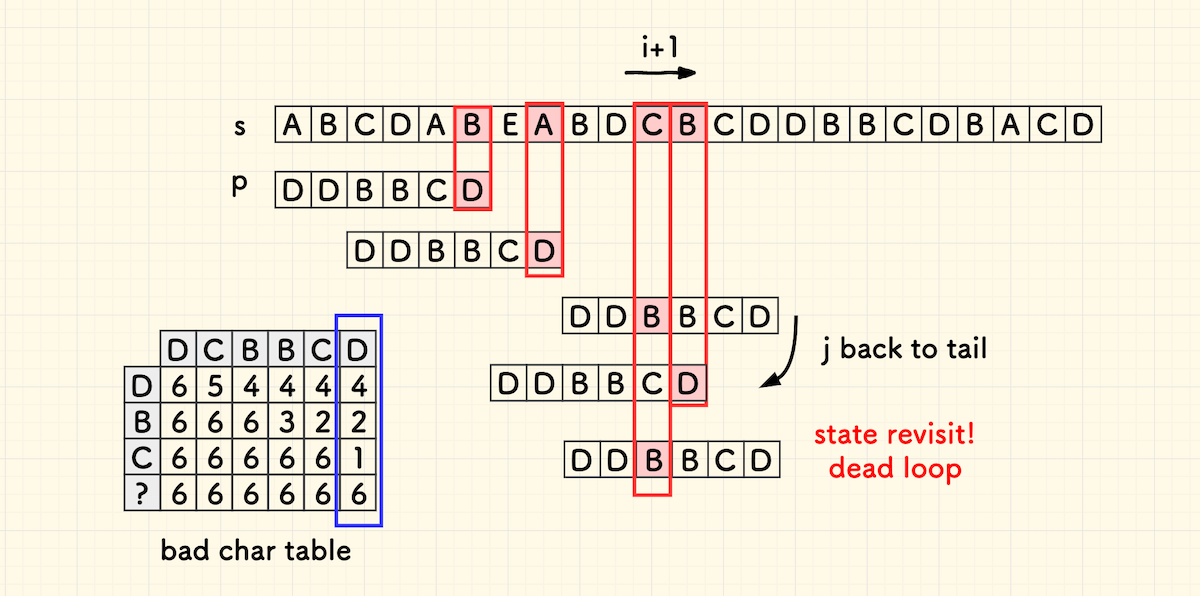
解决的办法是,要保证子串至少右移一位,也就是说,要保证主串迭代量不小于 m-j 。
在前面的结论中,已经知道:
这是显而易见的,因为无论寻找坏字符还是好后缀的匹配都是在失配处的左侧子串中查找。 因此,采用二维版本的坏字符表没有回溯问题,结合一维坏字符表和好后缀表的方式也不会有回溯问题, 而单纯采用一维退化版本的坏字符表时,要注意回溯带来的死循环问题。
好后缀表 ¶
好后缀表的构造一般被认为是 Boyer-Moore 算法中最难的部分。
前面已经分析 好后缀方法中的 d 存在两种情况。
明确现在的问题,对于搜索串 p 的所有后缀 suffix(k) ,找出对应的 d,其中 k 是失配的位置。
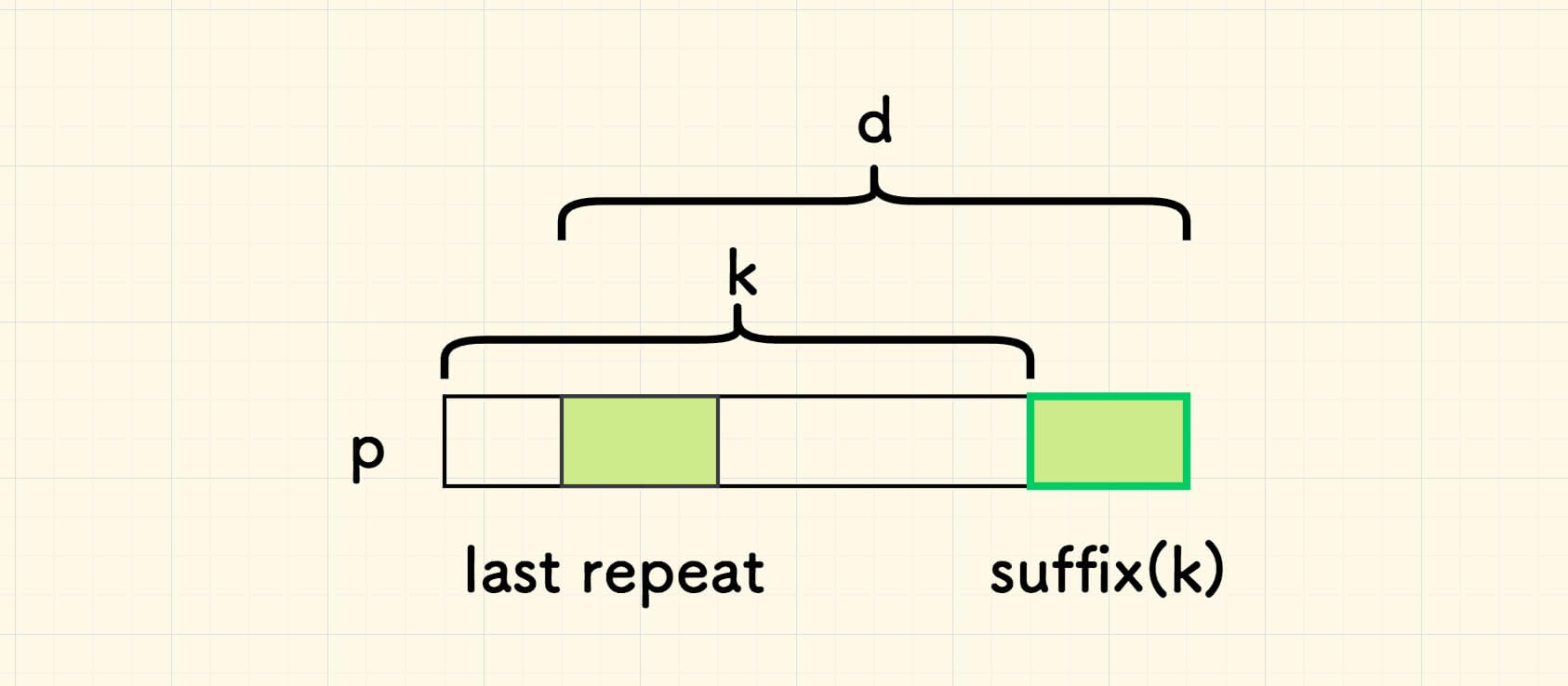
假设存放 d 的一维数组是 table ,考虑此表格如何填写。
参考 前面的分析 , 共有两种情况,分两次填表。
先处理第二种情况的填表过程,即 好后缀不在左边的情况。
原因在于,table 的意义是失配时,主串迭代的多少。 第二种情况的值更大。 先填写更大的,再覆盖以小的, 这样才不至于错过小迭代量的匹配点。
好后缀不在左边的情况
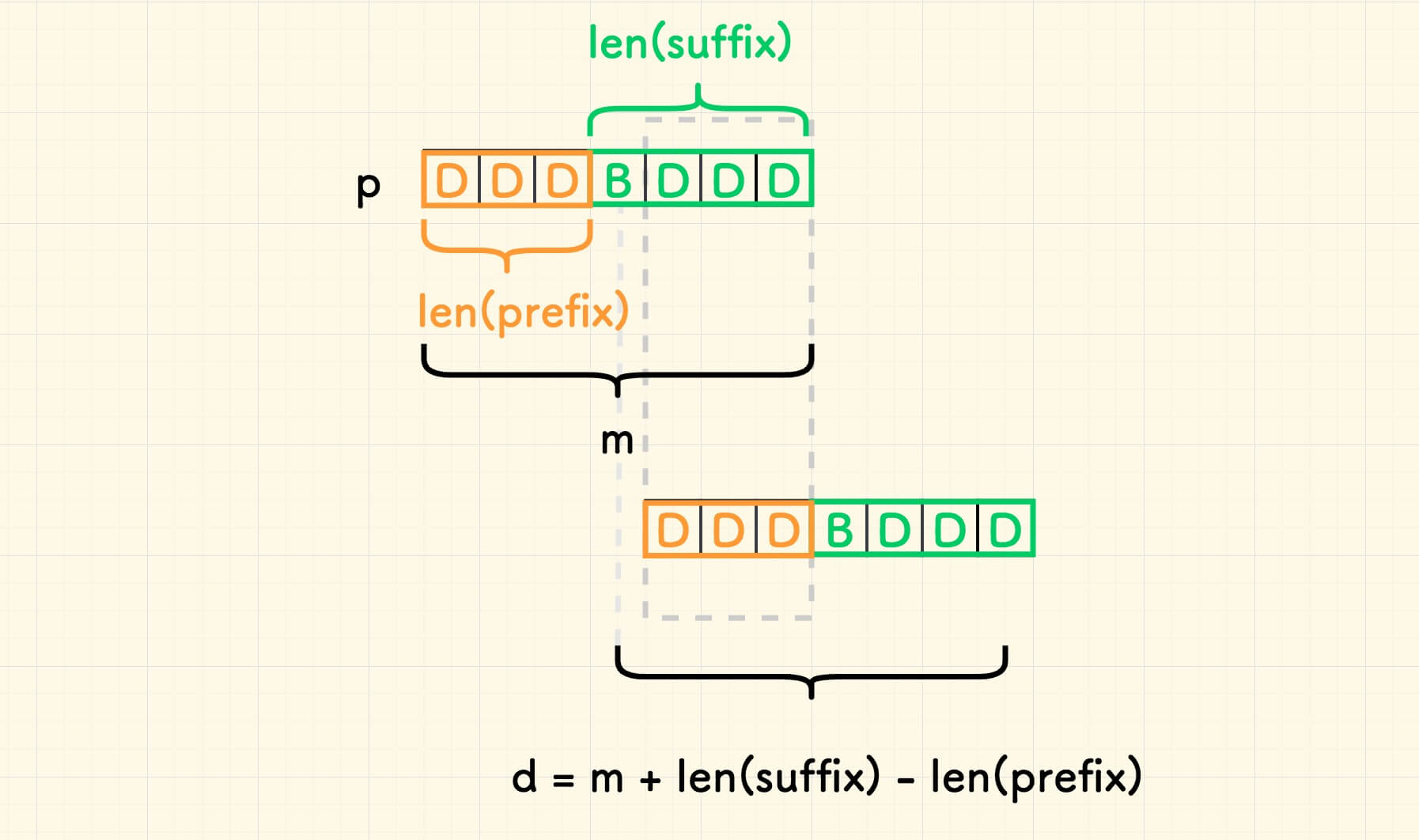
为方便说明,本部分的搜索串的示例调整为 DDDBDDD 。
参考 前面的分析 ,此情况下的 d = m + len(suffix) - len(prefix) 。
举例来说,当好后缀为 BDDD 的时候,d 的求值如下图所示:
问题是:如何找到搜索串的每一个后缀的部分匹配前缀 ?
下图中,suffix(k) 表示在 k 处失配时的好后缀,黄色框表示其对应的部分匹配前缀, 右边依次列出前缀的长度:
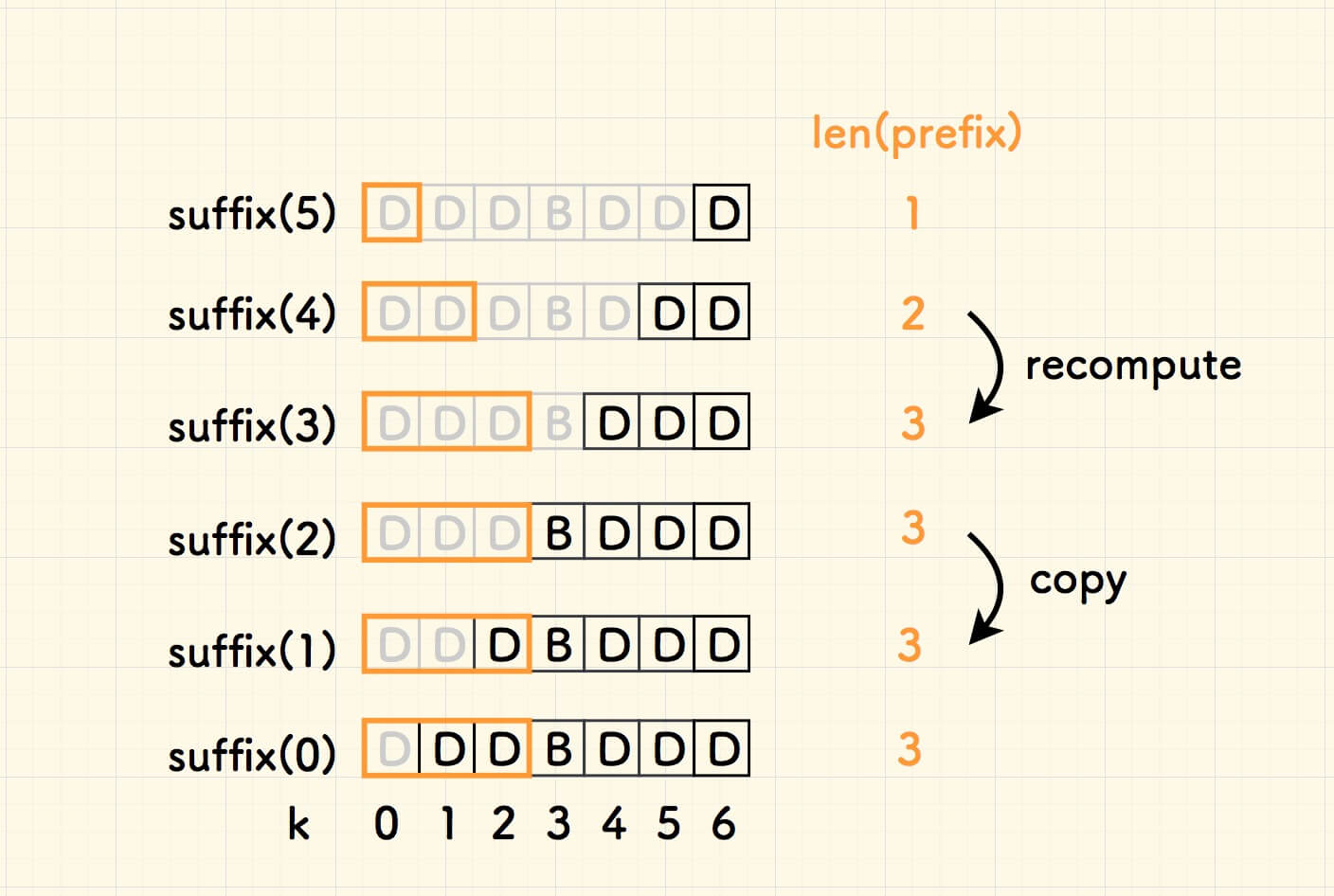
前缀长度的变化是有规律的,从上而下填写:
- 如果后缀是一个前缀,计算
len(prefix) = len(suffix),并记录为last_prefix_length。 - 否则,沿用上一次的计算结果:
len(prefix) = last_prefix_length。
是否和 KMP 算法的 next 数组计算方式 类似呢。
len(prefix) 的计算清楚之后,此情况的填表过程即得到解决。
C 语言实现 - 填写好后缀表 - 好后缀不在搜索串的左边的情况
// ComputeGoodSuffixTableCaseNotInLeft
// 填写好后缀表,处理情况:好后缀不在搜索串的左边的情况
void ComputeGoodSuffixTableCaseNotInLeft(char *p, int m, int table[]) {
int last_prefix_length = 0;
// 失配位置在 m - 1 时,好后缀无意义,设为跳动最少 1
table[m - 1] = 1;
// i 表示后缀的起始位置
for (int i = m - 1; i > 0; i--) {
// k 表示失配的位置
int k = i - 1;
int suffix_length = m - i;
char *suffix = p + i;
int prefix_length = 0;
if (strncmp(p, suffix, suffix_length) == 0) {
// 如果后缀是一个前缀
prefix_length = suffix_length;
last_prefix_length = prefix_length;
} else {
// 否则,沿用上次结果
prefix_length = last_prefix_length;
}
// 计算 d
table[k] = m + suffix_length - prefix_length;
}
}
好后缀在左边的情况
为方便说明,本部分的搜索串的示例调整为 DCDBCDACD 。
参考 前面的分析 ,此情况下的 d = m - t , 如何计算 t 取决于如何找到左边最右的重复串。
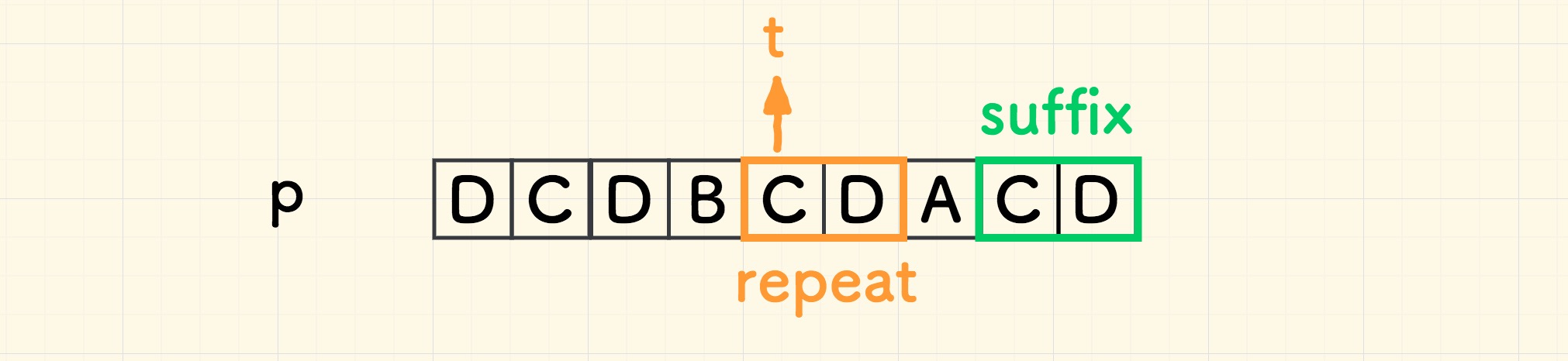
引入一个概念:最长公共后缀 ,如图所示:

C 语言实现 - 最长公共后缀长度
// GetLongestCommonSuffixLength 返回字符串 a 和 b 的最长公共后缀长度。
// 比如 'simple' 和 'example' 的最长公共后缀是 'mple' ,长度是 4.
int GetLongestCommonSuffixLength(char *a, int a_length, char *b, int b_length) {
int i = 0;
for (i = 0; i < a_length && i < b_length; i++) {
if (a[a_length - 1 - i] != b[b_length - 1 - i]) {
break;
}
}
return i;
}
如果左边存在重复串,那么它是一个前缀 和 p 的最长公共后缀 。
下图中,两个前缀串和 p 的最长公共后缀相同,取长的那个。 这样才能找到 最右的 重复串。
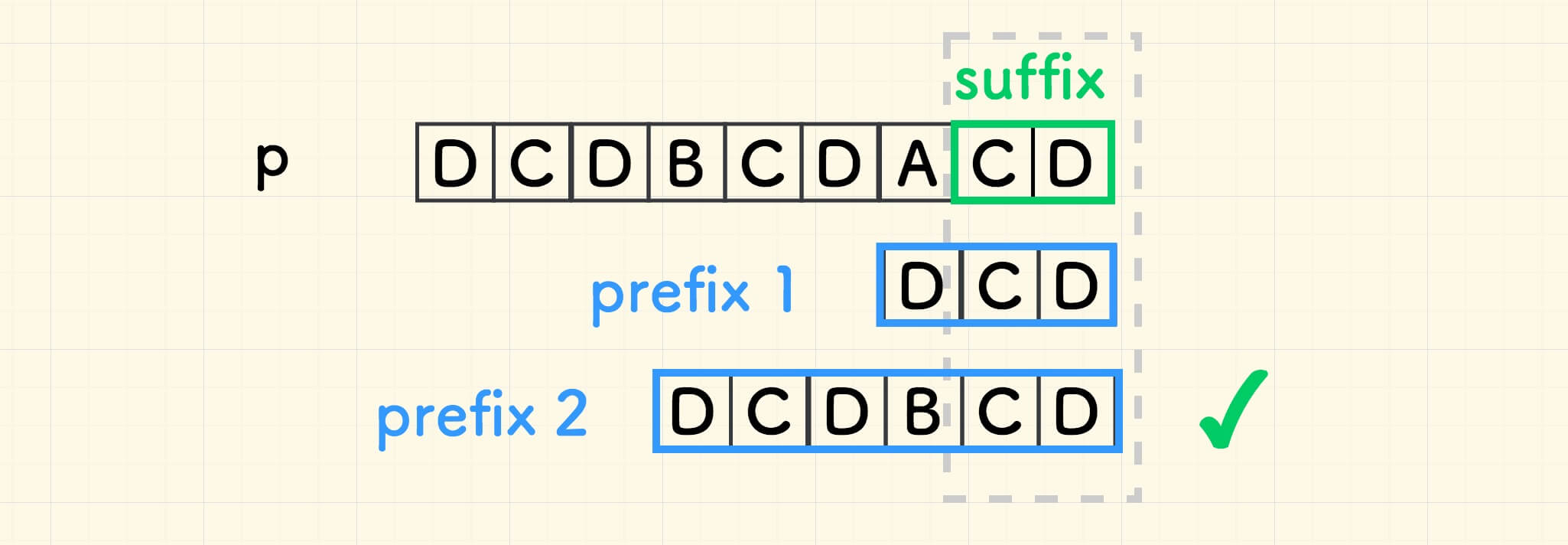
也就是,前缀要从短往长去找,用长的去覆盖短的计算结果 。
如果前缀以 e 下标结尾, 显然 t = e + 1 - len(suffix) 。
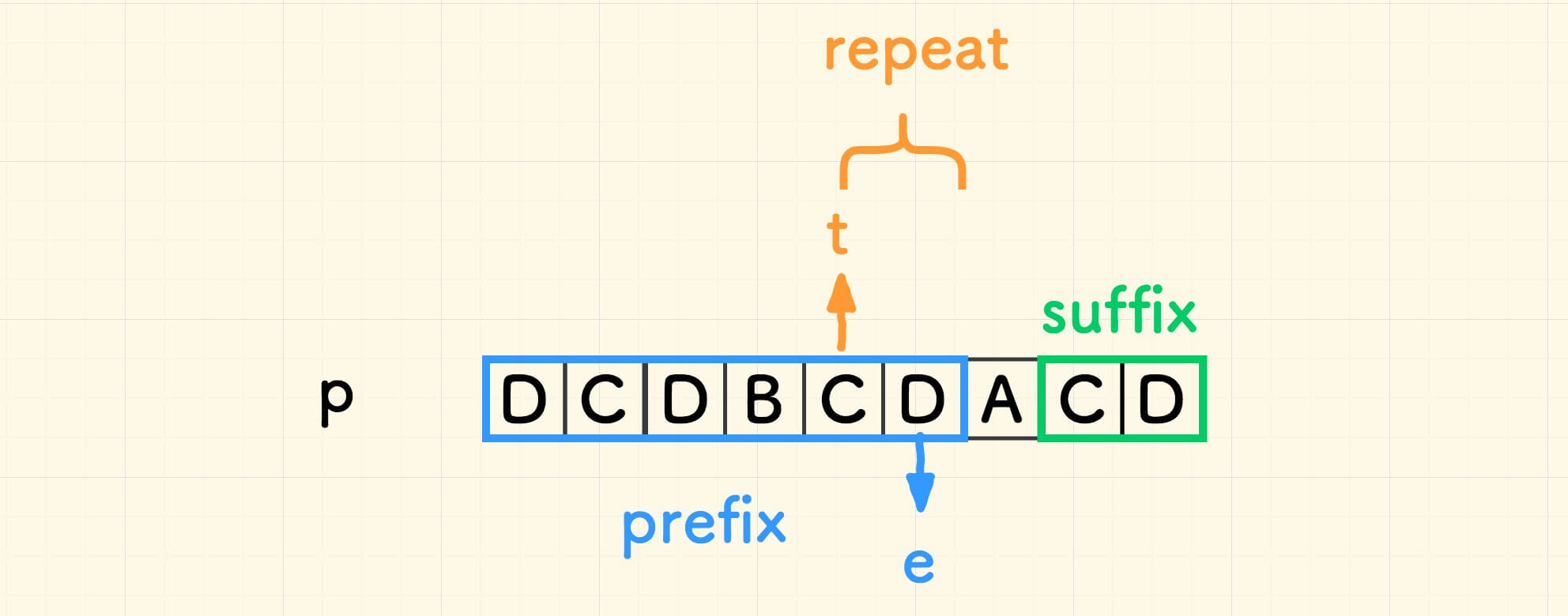
至此,思路如下:
- 对
p的每个前缀,计算它和p的最长公共后缀,设其长度len - 即确定了长度为
len的后缀,相应的t亦可得出。 - 长的前缀的计算结果覆盖短的。
进一步的说明
为方便说明,将搜索串 p 的例子调整为 ACDBCDABCD 。
后缀 CD 对应的前缀则是:
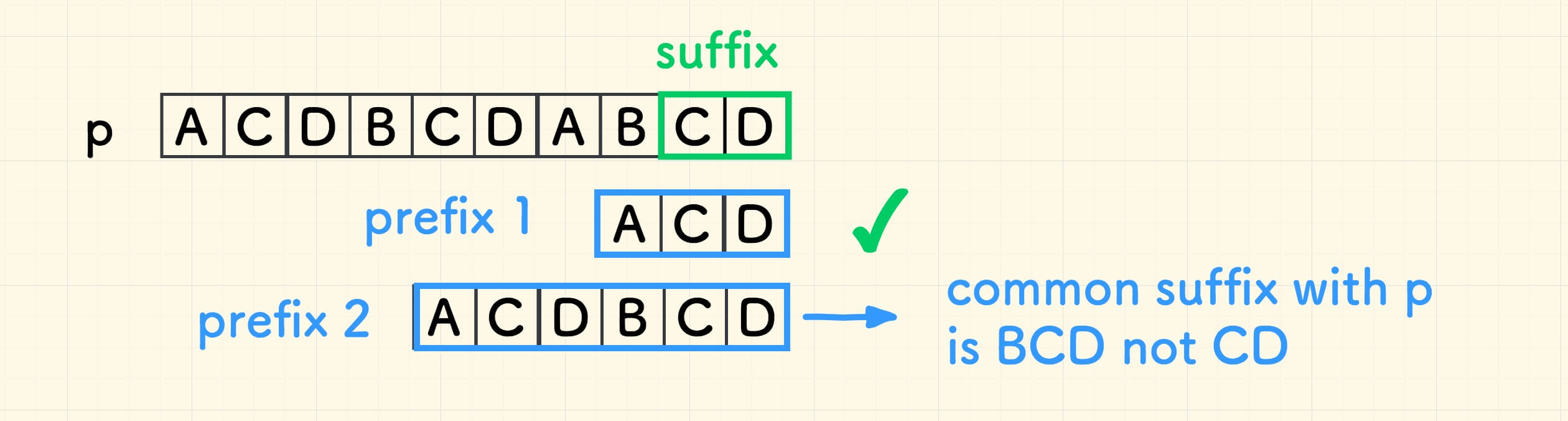
注意的是,此情况下重复串的位置,在 prefix1 结尾。
并非巧合,重复串和好后缀左边的字符必然不同, 否则右移后坏字符仍然失配。
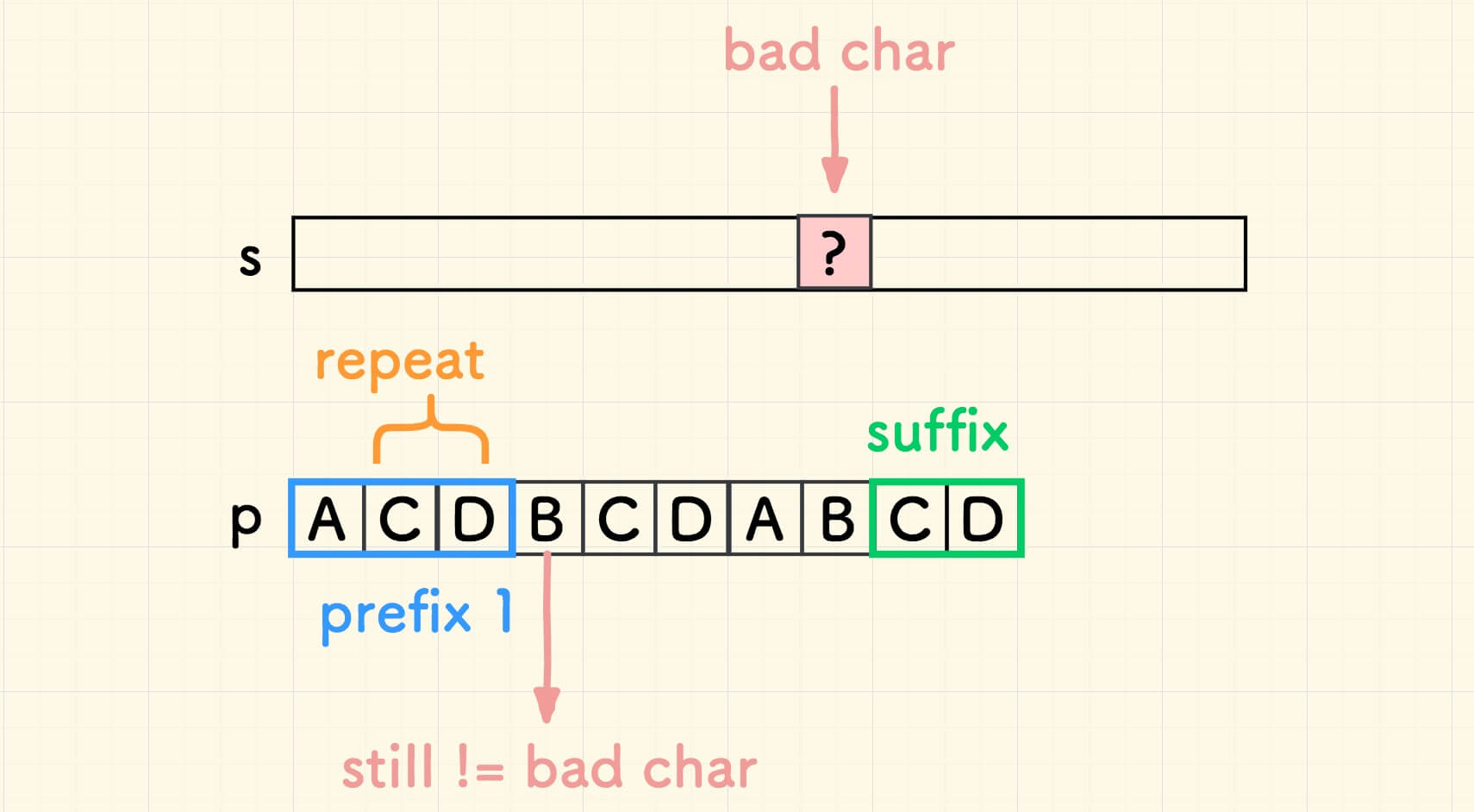
C 语言实现 - 填写好后缀表 - 好后缀在搜索串的左边的情况
// ComputeGoodSuffixTableCaseInLeft
// 填写好后缀表,处理情况:好后缀在搜索串的左边的情况
void ComputeGoodSuffixTableCaseInLeft(char *p, int m, int table[]) {
// e 表示对应的前缀的结尾位置
for (int e = 0; e < m - 1; e++) {
// 前缀字符串
char *prefix = p + e;
// 前缀的长度
int prefix_length = e + 1;
// 最长公共后缀的长度,即好后缀的长度
int suffix_length =
GetLongestCommonSuffixLength(p, m, p, prefix_length);
if (suffix_length > 0) {
// 好后缀长度 > 0 才有意义
// t 是重复串的起始位置
int t = e + 1 - suffix_length;
// 失配字符的位置
int k = m - 1 - suffix_length;
// 填表,覆盖
table[k] = m - t;
}
}
}
C 语言实现 - 填写好后缀表 - 综合两种情况
// ComputeGoodSuffixTable 计算好后缀表的方法
void ComputeGoodSuffixTable(char *p, int m, int table[]) {
// 先处理第二种情况:好后缀在搜索串左边不存在的情况
// 即好后缀和搜索串部分匹配或者完全不匹配的情况
ComputeGoodSuffixTableCaseNotInLeft(p, m, table);
// 再处理第一种情况:好后缀在搜索串左边存在的情况
ComputeGoodSuffixTableCaseInLeft(p, m, table);
}
查找过程 ¶
可以看到,坏字符表和好后缀表只和搜索串有关,可以提前生成 。
至此,已可以完成整个 Boyer-Moore 算法:
- 对搜索串,填写坏字符表和好后缀表
- 先对齐主串和搜索串。
- 自右向左匹配。
- 失配时,挑选两张表中最大的跳转量,作为主串的迭代量。
C 语言实现 - BoyerMoore 查找
#define max(a, b) ((a < b) ? b : a)
// BoyerMoore 从长度为 n 的字符串 s 中查找长度为 m 的字符串 p , 返回其位置.
// 找不到则返回 -1
int BoyerMoore(char *s, int n, char *p, int m) {
int bad_char_table[ALPHABET_SIZE];
int good_suffix_table[m];
ComputeBadCharTable(p, m, bad_char_table);
ComputeGoodSuffixTable(p, m, good_suffix_table);
// 初始化,i, j 右对齐
int i = m - 1;
while (i < n) {
int j = m - 1;
// 自右向左匹配
while (j >= 0 && p[j] == s[i]) {
j--;
i--;
}
if (j < 0) {
// 命中, 返回起始位置
return i + 1;
}
// 失配时,跳转的多少,选取坏字符表和好后缀表中最大的跳转量
i += max(bad_char_table[s[i]], good_suffix_table[j]);
}
return -1;
}
此外,Go 语言的实现可以参考官方的 search.go 。
复杂度分析 ¶
一维坏字符表构建的时间复杂度是常数的 O(S + m) ,其中 S 是所考虑的字符集的大小。 二维坏字符表构建的时间复杂度则是 O(S * m) ,均是 m 相关的线性时间复杂度。
好后缀表在两种情况下的构建的时间复杂度均为 O(m^2) ,不过一般情况下搜索串的长度相对主串会很小, Golang 的官方实现 对好后缀表的构建方法亦和本文的一致。
事实上, Boyer-Moore 算法 - 维基百科 告诉我们,好后缀表可以在线性时间内构建,可以参考其给出的 Python 实现 , 其中采用的是 Z-算法。
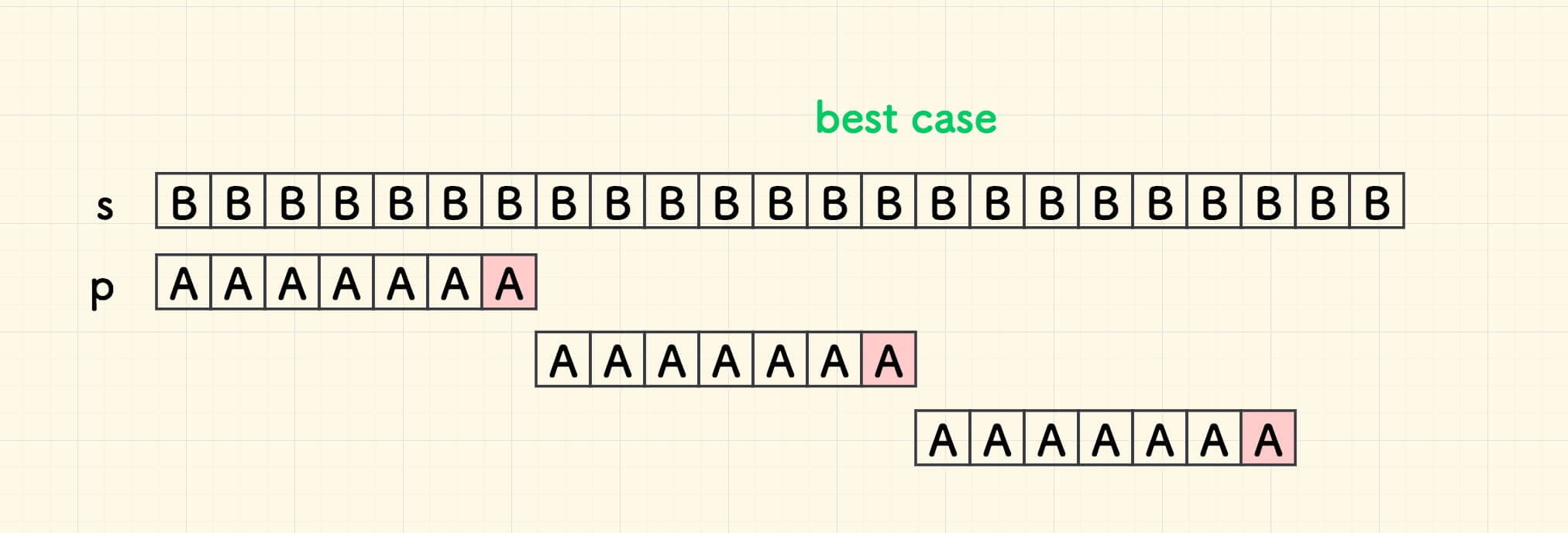
查找过程的时间复杂度是 O(m * n) ,其中最好情形如下图所示,时间复杂度是 O(n / m) :
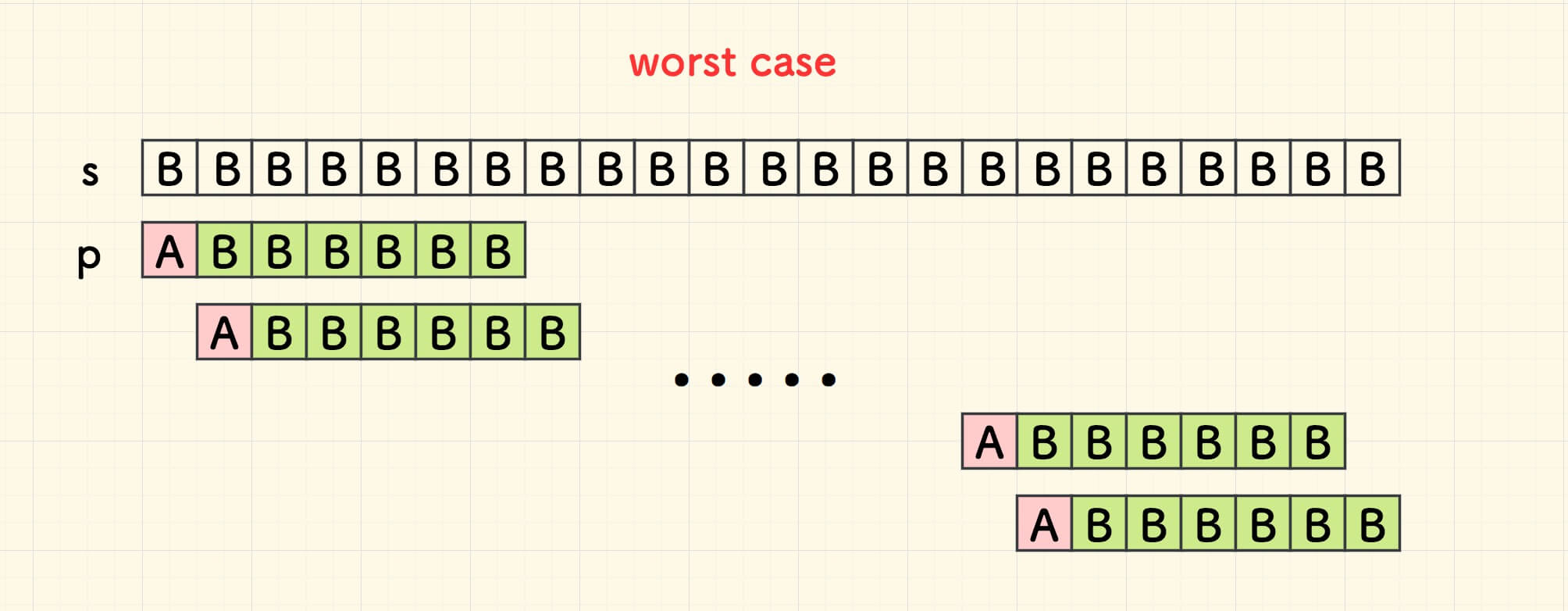
最坏情形的时间复杂度是 O(m * n) ,退化成为简易的二次循环匹配:
结语 ¶
Boyer-Moore 的坏字符办法和好后缀办法,可以综合使用,也可以单独使用一种,其中坏字符的办法实现更简单一些。
事实上,我认为 Boyer-Moore 算法远不如 KMP 算法 干练精巧,其主体查找过程虽然更容易理解,但是两种表格的计算,尤其是好后缀表的构建, 确是相对复杂的。
相关阅读:
(完)
本文原始链接地址: https://writings.sh/post/algorithm-string-searching-boyer-moore
