Skip list is a randomized data structure that stores ordered elements. For a skip list with n elements, the average time complexity for search and insertion is $O(logn)$. It has the advantages of fast search, convenient addition and deletion, and easy implementation.
Table of Contents:
Construction Idea ¶
The simplest containers for storing n elements are arrays and singly linked lists .
For a sorted array, using binary search to find an element has a time complexity of $O(logn)$. However, because arrays are stored in contiguous memory, inserting an element requires moving a batch of elements.

For a sorted singly linked list, searching for an element can only be done one by one, with a time complexity of $O(n)$. However, inserting an element does not require moving elements like in an array.

So, is it possible to design an ordered data structure that has a search time of $O(logn)$ and does not require moving elements when inserting elements?
Next, we will accelerate the search process based on the linked list and construct a skip list.
For a singly linked list, add some redundancy. Every other node, build a line, pointing to the node after the next. In addition, add a virtual head node to the singly linked list. It does not store specific data, but only serves as the head of the list.
In this way, searching for a value, in the worst case, requires examining a total of $ (n/2) + 1$ nodes.
The specific search method is: Starting from the top-left node, examine each node to the right. If the node to the right is smaller than the target value, continue to the right; otherwise, go to the next level and continue, until the bottom level.
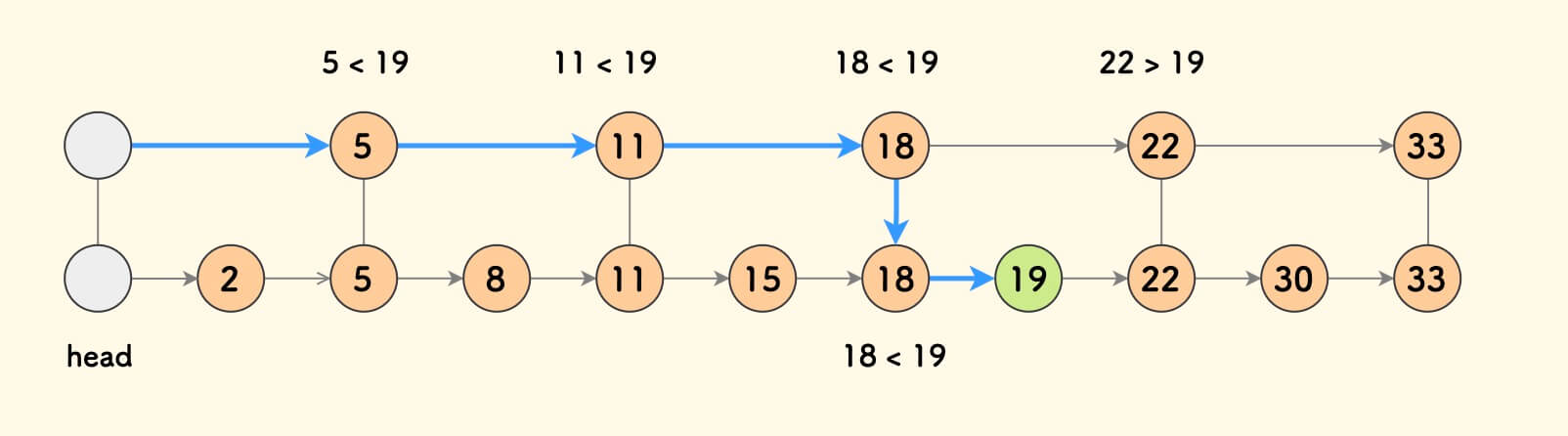
Following this idea, build another line every other node. At this point, searching for an element requires examining at most $(n/4) + 2$ nodes.
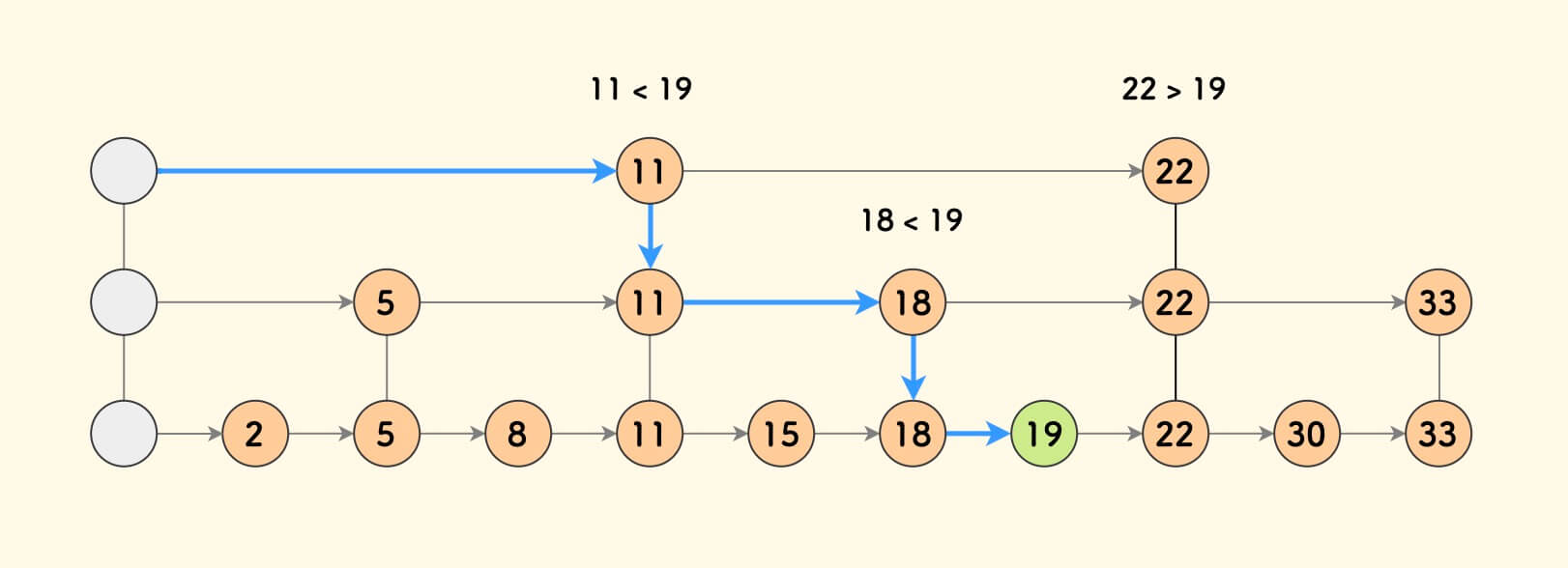
It can be inferred that when building k levels, searching for a target requires examining $2^{-k} + k$ nodes.
Until there are no more nodes to continue building levels.
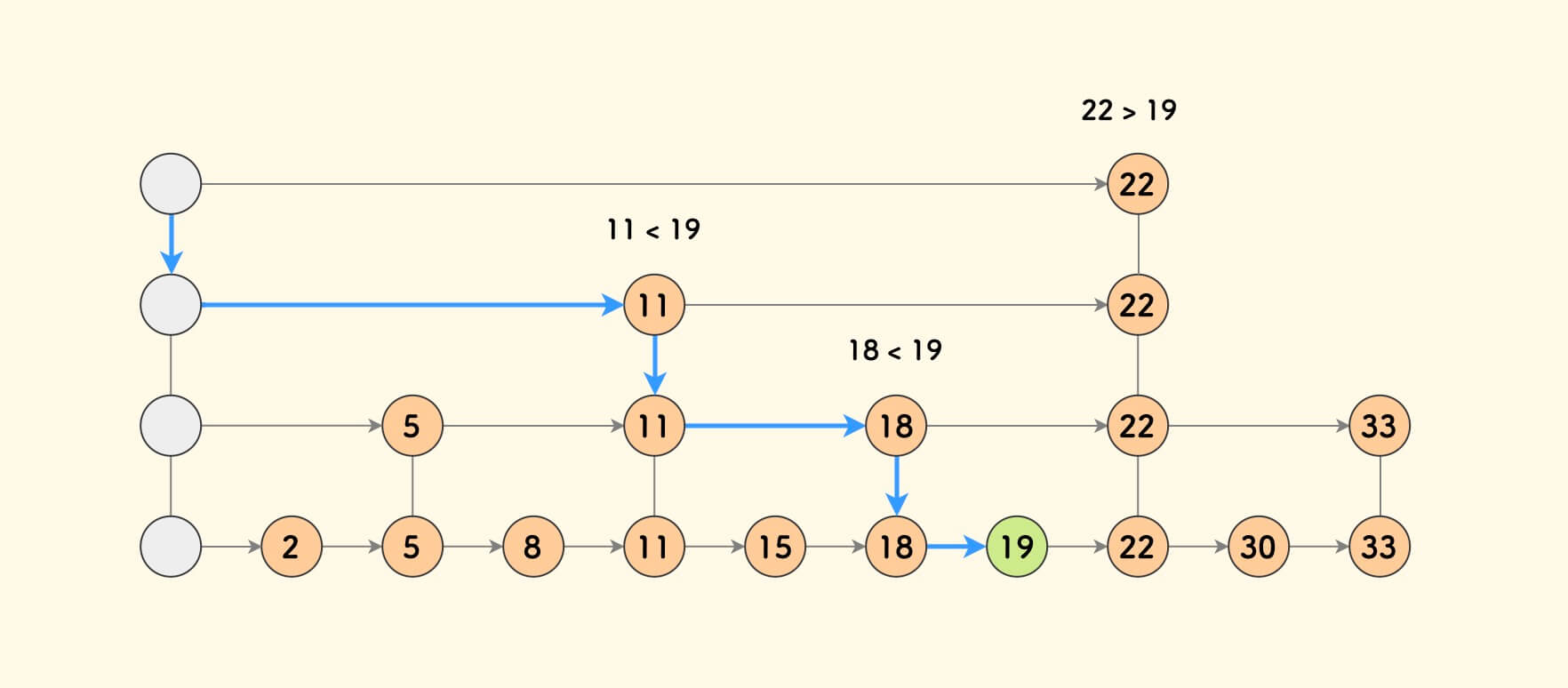
So, in the case of n elements, how many levels can be built?
Similar to the binary search process, each time a level is built, the number of elements is reduced to half of the original. Finally, the number of elements must be reduced to 1. Thus, we have $n / (2^k) = 1$, which means at most $k = logn$ levels can be built.
When $n$ is large enough, the number of examinations $2^{-k} + k$ is approximately $k$, i.e., $logn$. Therefore, with this approach, the search time complexity is reduced from $O(n)$ to $O(logn)$.
Randomization ¶
However, the data structure constructed above is too rigid because it strictly requires building a line every other node when constructing new levels. Once a new node is inserted, the rule of building lines is broken. Moreover, it is easy to realize that maintaining this rule is also quite cumbersome.
The solution is to slightly relax the structural conditions.
Let’s say a node with k+1 lines is called a k-th order node, starting from 0. That is the level field in the figure below, which is also the height of “building levels”:
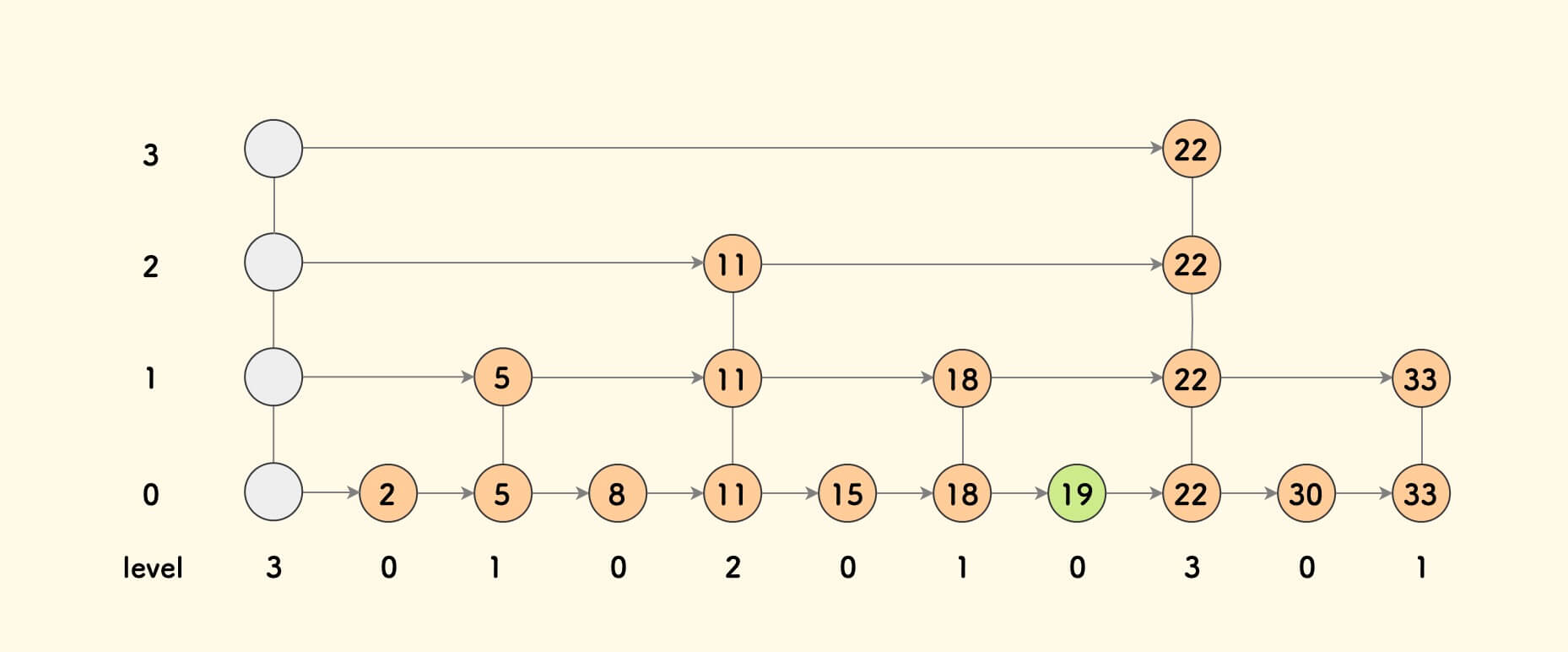
Initially, all nodes are 0-th order. After the first level is built, half of the nodes become 1-st order. After building another level, one-quarter of the nodes become 2-nd order… After building the k-th level, there will be $1/(2^k)$ k-th order nodes.
The way to relax the structural conditions is to make the k-th level appear approximately $1/(2^k)$ k-th order nodes according to this probability distribution. That is, when inserting an element, the probability that the new node becomes k-th order is $1/(2^k)$ .
Function RandLevel to calculate the order - C Language
// Generates a random level between 1 and MAX_LEVEL
int RandLevel() {
int level = 1;
// Increment level with probability P
// 1/2 probability level → 1
// 1/4 probability level → 2
// 1/8 probability level → 3
while ((rand() & 65535) * 1.0 / 65535 < 0.5) level++;
return level < MAX_LEVEL ? level : MAX_LEVEL;
}
Here MAX_LEVEL is used to limit the maximum order because after the order is relatively large, building higher levels has less and less optimization effect on search time. Considering memory usage factors, a maximum order is often limited in practice.
The following is an example. It does not strictly conform to the “interval line building” rule. As before, the upper level still provides a fast lane for the lower level, accelerating the search process.
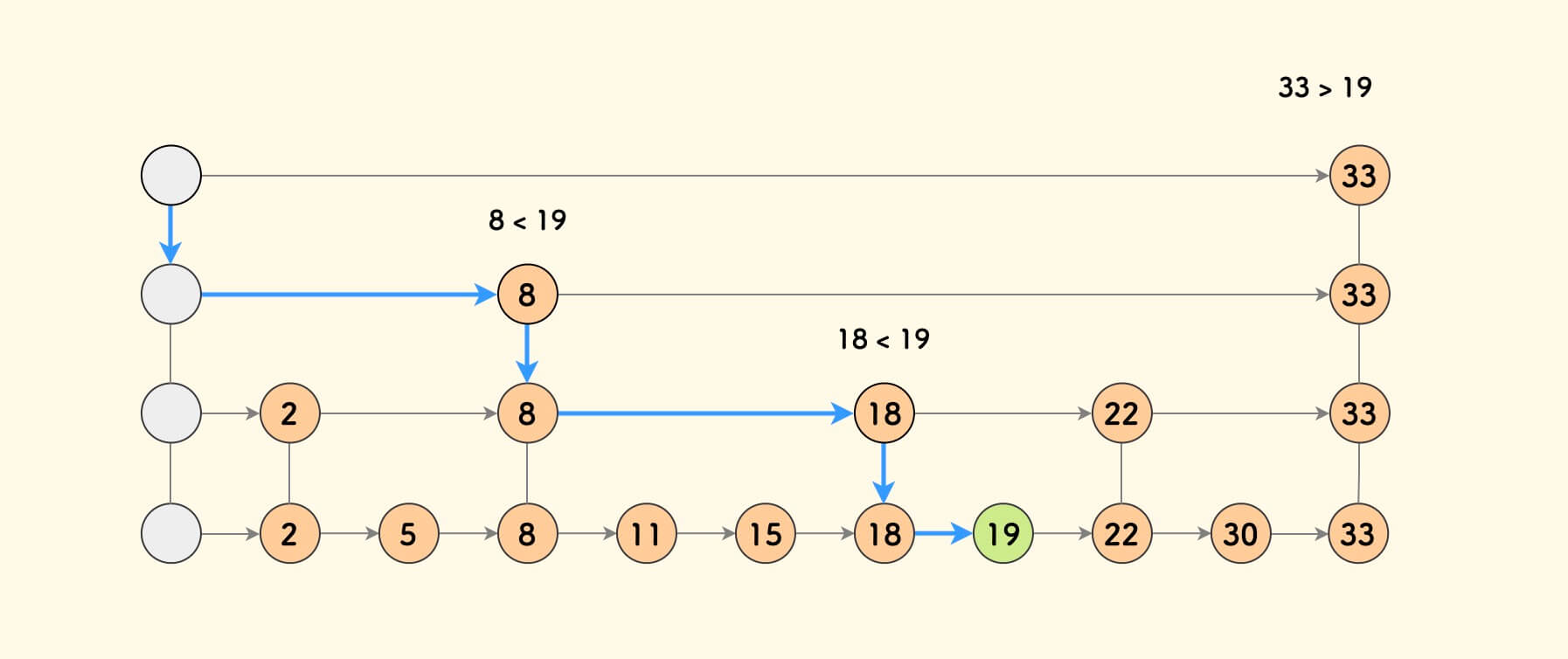
On average, there are approximately $n / (2^k)$ nodes at the k-th level, and the nodes at each level are expected to be roughly evenly distributed. Compared with the original non-randomized situation, the average time complexity for searching for a target has not changed, still $O(logn)$. Inserting a new element becomes simpler, without the cumbersome maintenance of strict “interval line building” rules.
However, skip lists do not provide performance guarantees for the worst-case scenario because it cannot be ruled out that a very unbalanced skip list will be generated with a very small probability. At that time, the time to search for an element will degenerate to $O(n)$ .
So far, the construction idea of the skip list is finished.
Interface Implementation ¶
The implementation of all the following interfaces will be based on the following data structure:
Skip List Structure - C Language
typedef struct _Node {
int v; // Node data
int level; // Total levels of the node
struct _Node *nexts[MAX_LEVEL]; // Forward array, element index: 0~level
} Node;
typedef struct {
int n; // Number of nodes
int level; // Maximum level
Node *head; // Head node, non-data node, and highest level
} Skiplist;
Where:
- The head node
headis a virtual head node and does not store data; and its order is always aligned with the highest order node. - Each node has a forward array
nextsto store the addresses of successor nodes at each level.
Search Element
The search process has been mentioned many times earlier:
Starting from the top-left node of the skip list, examine to the right until a node is encountered that is not smaller than the target value, then continue to the next level, until the bottom level. Judge whether the next node of the current node at the bottom level is the target value.
Check if a value is in the skip list - C Language
bool Has(Skiplist *sl, int v) {
Node *n = sl->head;
// From top level to bottom
for (int i = sl->level; i >= 0; i--) {
// Compare size to the right
while (n->nexts[i] != NULL && n->nexts[i]->v < v)
n = n->nexts[i];
}
n = n->nexts[0];
return n != NULL && n->v == v;
}
Insert Element
Inserting an element into a skip list can be divided into three steps:
Find the insertion position at each level .
Like a singly linked list, to insert an element, you need to find the predecessor node. A skip list is a multi-level linked list, so you need to find the predecessor node at each level.
In the figure below, to insert a new element
20, where the arraylast[k]represents the predecessor node found at thek-th level.The method to find it is the same as the search process, just remember the last node that can be examined to the right at each level.

Figure 3.1 - Find the insertion position at each level last[k] Determine the order of the new node .
Use the random function RandLevel mentioned above to determine its order. If an order higher than the entire skip list is obtained, the order of the head node needs to be increased to align with it. So that any node can be found starting from the top-left head node.
Since the meaning of the
lastarray is the insertion position at each level, and next, the head node will point to the new node at these newly increased levels, the head nodeheadis recorded as the value of thelastarray at these levels.In the figure below, if a large order
4is generated, then the order of the skip list will increase to4, and setlast[4] = head.
Figure 3.2 - If the order of the new element is larger than the entire skip list, the order of the head node needs to be increased Perform insertion actions at each level .
Still similar to a singly linked list, the process of inserting a new node is to connect the new node with the predecessor and successor nodes respectively. It’s just that the skip list is performed on multiple levels.
At each level, the predecessor node
last[k]points to the new node, and the new node points to the original successor node oflast[k].
Figure 3.3 - Insert new nodes at each level



The code implementation is as follows:
Insert a node into the skip list - C Language
void Put(Skiplist *sl, int v) {
// Step 1: Find the insertion position at each level
// last[i] represents the predecessor node of the insertion position at level i
Node *last[MAX_LEVEL];
Node *n = sl->head;
for (int i = sl->level - 1; i >= 0; i--) {
while (n->nexts[i] != NULL && n->nexts[i]->v < v)
n = n->nexts[i];
last[i] = n;
}
// Step 2: Determine the order of the new node
int level = RandLevel(); // Number of levels of the new node
if (level > sl->level) {
// The number of levels of the new node is greater than the original
// Need to supplement the high bits of the last array, head will point to this node
for (int i = sl->level; i < level; i++) last[i] = sl->head;
sl->level = level;
}
// Step 3: Perform insertion at each level
Node *node = NewNode(v, level);
for (int i = 0; i < level; i++) {
node->nexts[i] = last[i]->nexts[i];
last[i]->nexts[i] = node;
}
sl->n++;
}
Delete Element
Similarly, deleting an element from a skip list can also be divided into three steps:
Find the predecessor nodes and the node to be deleted at each level .
To delete an element from a singly linked list, you need to find the predecessor node. A skip list is a multi-level linked list, and you also need to find the predecessor node at each level.
As before, the
lastarray is used to store the predecessor nodes at each level. The process of searching for an element can record thelastarray.At the same time, after the search is completed, it can also be judged whether the element to be deleted exists in the list.
The following figure takes deleting element
22as an example:
Figure 3.4 - Find the predecessor nodes last[k] at each level Perform deletion at each level .
Still similar to a singly linked list. At each level, the predecessor node directly points to the successor node of the node to be deleted. Finally, release the memory of the node to be deleted.
However, not every item in the
lastarray is the predecessor node of the node to be deleted. You need to pay attention to filtering when deleting.Taking deleting
22as an example, the specific deletion action is: if the successor oflast[k]is22, then set the successor oflast[k]to point to the successor of22.
Figure 3.5 - Perform deletion at each level Erase the possibly remaining isolated high orders after deleting the node .
If the deleted element is a high-order node, it may leave isolated high orders remaining in the head node of the skip list.
This step is optional, and it is okay even if it is not cleaned up.
Taking deleting the high-order node
33as an example, after deleting33, the order of the head node can be reduced from4to3.
Figure 3.6 - Deleting a high-order node may reduce the order of the entire skip list



The code implementation is as follows:
Delete a node from a skip list - C Language
bool Pop(Skiplist *sl, int v) {
// Step 1: Find the predecessor nodes of the deletion position at each level
Node *last[MAX_LEVEL];
Node *n = sl->head;
for (int i = sl->level - 1; i >= 0; i--) {
while (n->nexts[i] != NULL && n->nexts[i]->v < v) n = n->nexts[i];
last[i] = n;
}
// Node to be deleted
n = n->nexts[0];
if (n == NULL || n->v != v) return false;
// Step 2: Perform deletion at each level
for (int i = sl->level - 1; i >= 0; i--) {
if (last[i]->nexts[i] == n) last[i]->nexts[i] = n->nexts[i];
}
// Step 3: Remove invalid levels possibly caused by deleting the node
while (sl->level > 1 && sl->head->nexts[sl->level - 1] == NULL) {
sl->level--;
}
sl->n--;
FreeNode(n);
return true;
}
It can be seen that the search, insertion, and deletion of skip lists maintain an ordered linked list, and the average time complexity of the three actions is $O(logn)$ .
Complete Code Implementation
Properties and Scenarios ¶
Skip lists are very suitable for “ordered dictionary” scenarios, and in this regard, they are easier to understand and simpler to implement compared to red-black trees, binary search trees, etc. In addition, a great thing about skip lists is that their bottom-level linked list itself is ordered, which is also very suitable for range queries.
Concluding Remarks ¶
A skip list is a multi-level ordered linked list structure. The upper level provides a fast lane for the lower level, and the bottom level is an ordered linked list. The average time complexity for element search, insertion, and deletion is $O(logn)$ , but as a randomized data structure, there is a very small probability that performance will degrade to $O(n)$ in the worst case. At the same time, as a linked list structure, insertion and deletion of elements are more convenient, and there is no need for batch memory copying like arrays.
(End)
Please note that this post is an AI-automatically chinese-to-english translated version of my original blog post: http://writings.sh/post/data-structure-skiplist.
Original Link: https://writings.sh/post/en/data-structure-skiplist