This article documents my development notes on implementing a C++ library for quadtrees.
Project repo address: https://github.com/hit9/quadtree-hpp
A quadtree is a data structure for partitioning space in a 2D plane. It can quickly answer the question “what objects are near a position on the plane?”, and is commonly used to optimize collision detection.
It looks something like this. In the figure below, the black squares are objects managed by the quadtree. The entire region is continuously subdivided into quadrants based on certain conditions. Then, we can select a rectangular region and quickly query which objects are hit within this tree.

Quadtrees can work not only on square regions but also on rectangular regions:
The following are some notes on the implementation ideas of quadtrees.
Splitting ¶
First, the root node governs the entire map. Then, under certain conditions, the map is divided into four equal parts. If the conditions are still met, the subdivision continues to the next level until the region governed by the leaf node is no longer divisible.
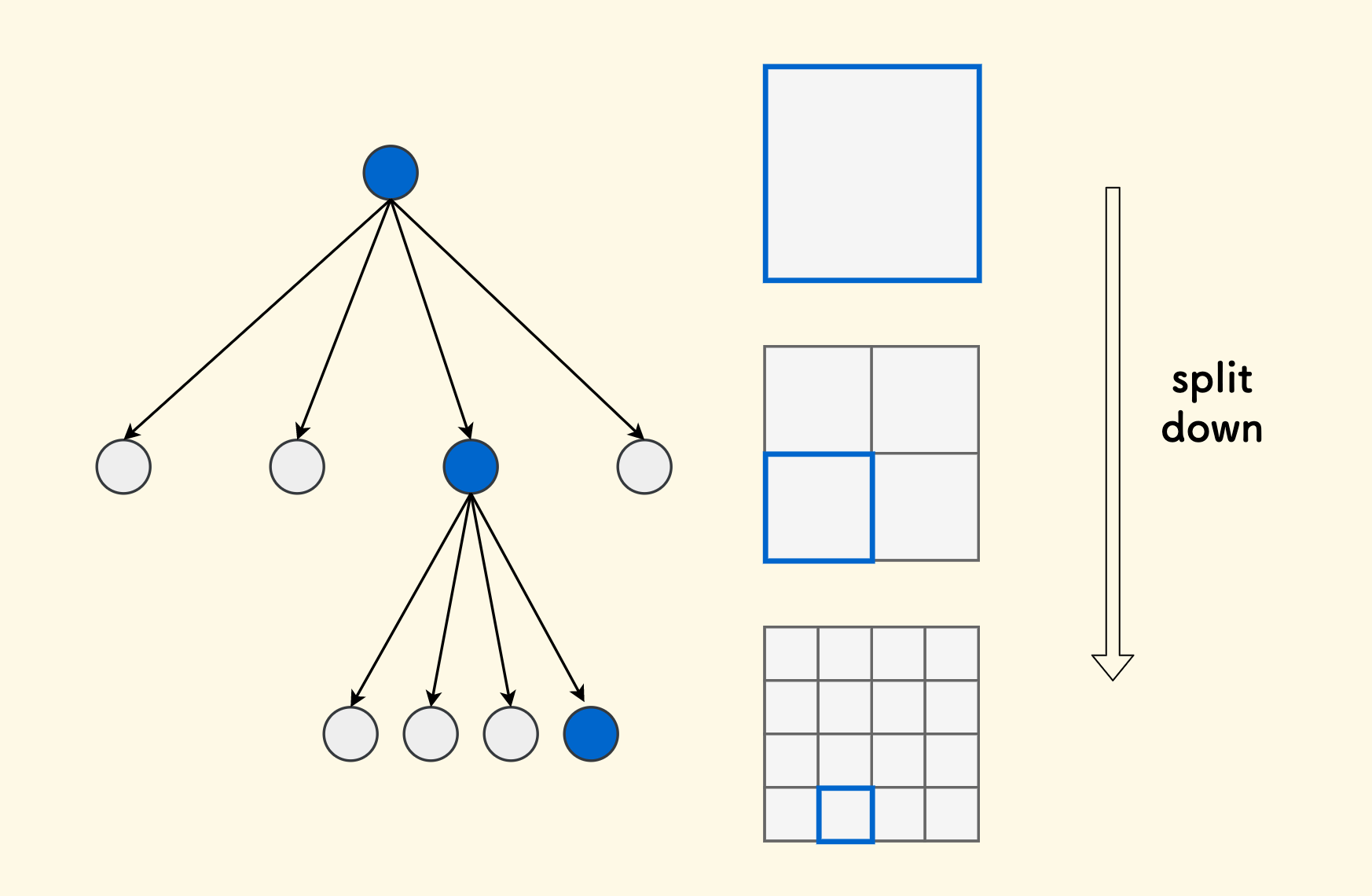
The conditions for stopping splitting can be that the number of objects within a rectangle does not exceed a certain value, or that a rectangle is not too large, etc., depending on specific needs. There is a problem on leetcode leetcode 427. Construct Quad Tree, which can be used to practice the splitting process of quadtrees. Its division condition is to continuously divide into quadrants until each square contains either all $1$s or all $0$s.
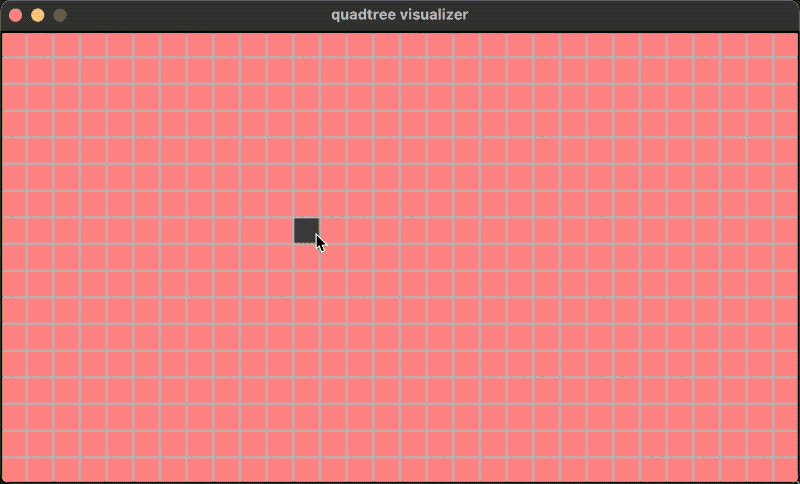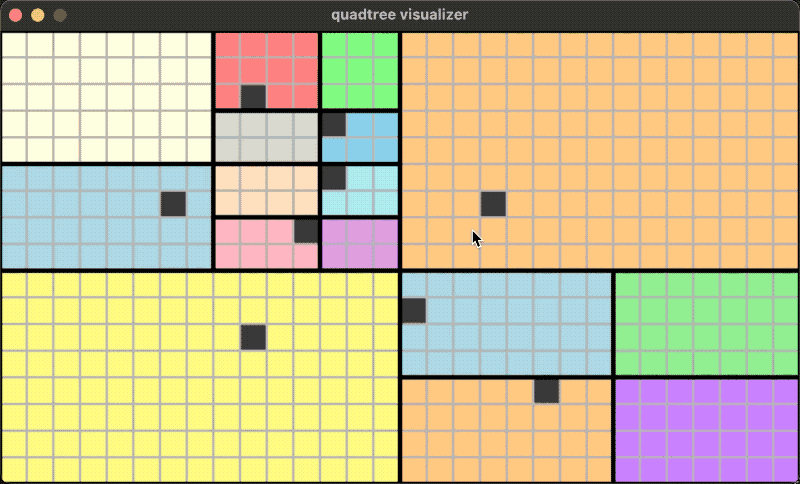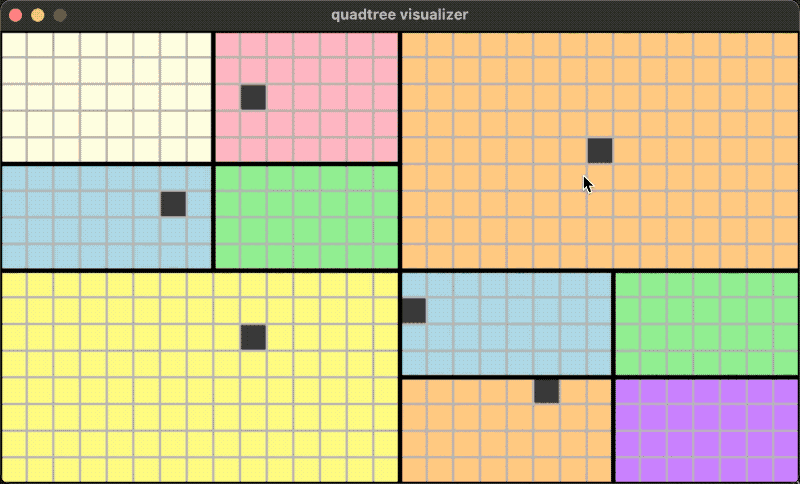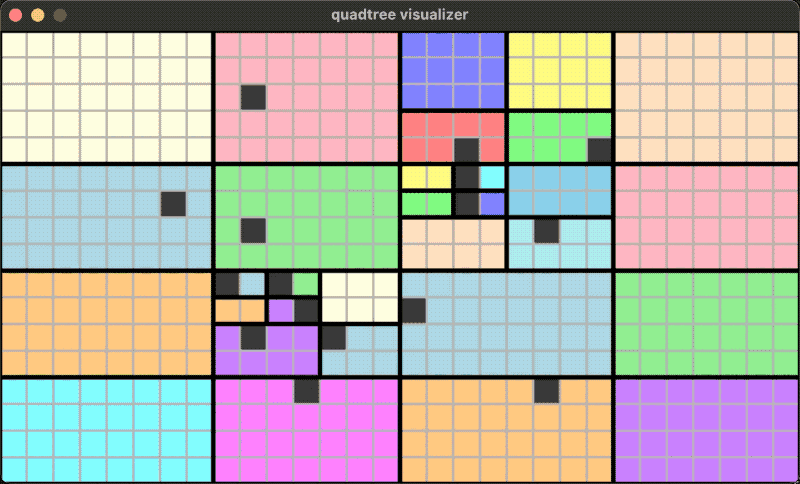
I designed a function to allow customization of this condition. For example, the following quadtree is built on a $100 \times 100$ grid map. Its stopping condition for splitting is either that the rectangle of the leaf node is as small as $2 \times 2$, or that the number of objects in the leaf rectangle does not exceed $3$.
SplitingStopper ssf = [](int w, int h, int n) {
return (w <= 2 && h <= 2) || (n <= 3);
};
Quadtree<int> tree(100, 100, ssf);
When adding an object to a position $(x,y)$, we first need to determine the leaf node to which this position belongs and add the object to the management area of this leaf node. Now it may become “unstable”, so we need to test the splitting condition, trying to recursively split downwards until the splitting condition is no longer met.
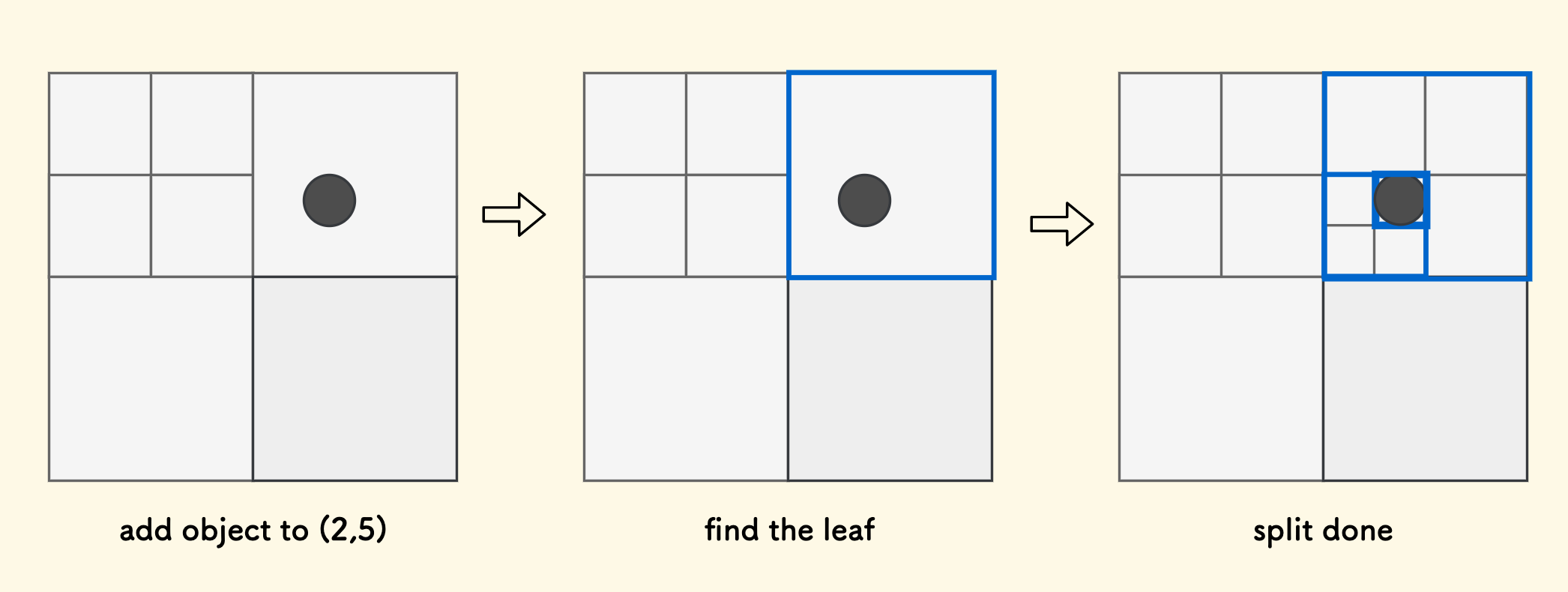
Here’s a hint, how to quickly locate the leaf node to which a position coordinate belongs? It will be discussed later, it is a key optimization.
Merging ¶
Conversely, if a non-leaf node no longer meets the “splittable” condition, that is, its original division has become too fine, then starting from the leaf nodes, it can be merged back upwards.
For example, after removing an object, the leaf node becomes empty. Looking upwards, the parent node of the leaf node also becomes “empty”. Then, we can consider releasing the leaf node and its sibling leaf nodes together, and returning the remaining managed objects to the parent node. This process is called merging.
Specifically, to remove an object at position $(x,y)$ from the tree, we first need to locate the leaf node to which this position belongs, and then remove it from the list of objects managed by the leaf node. After this, observe the parent node of the leaf node. It may become “empty”, that is, it may itself degenerate into a leaf node, and then release its child nodes. Recursively go upwards until no more merging is possible.
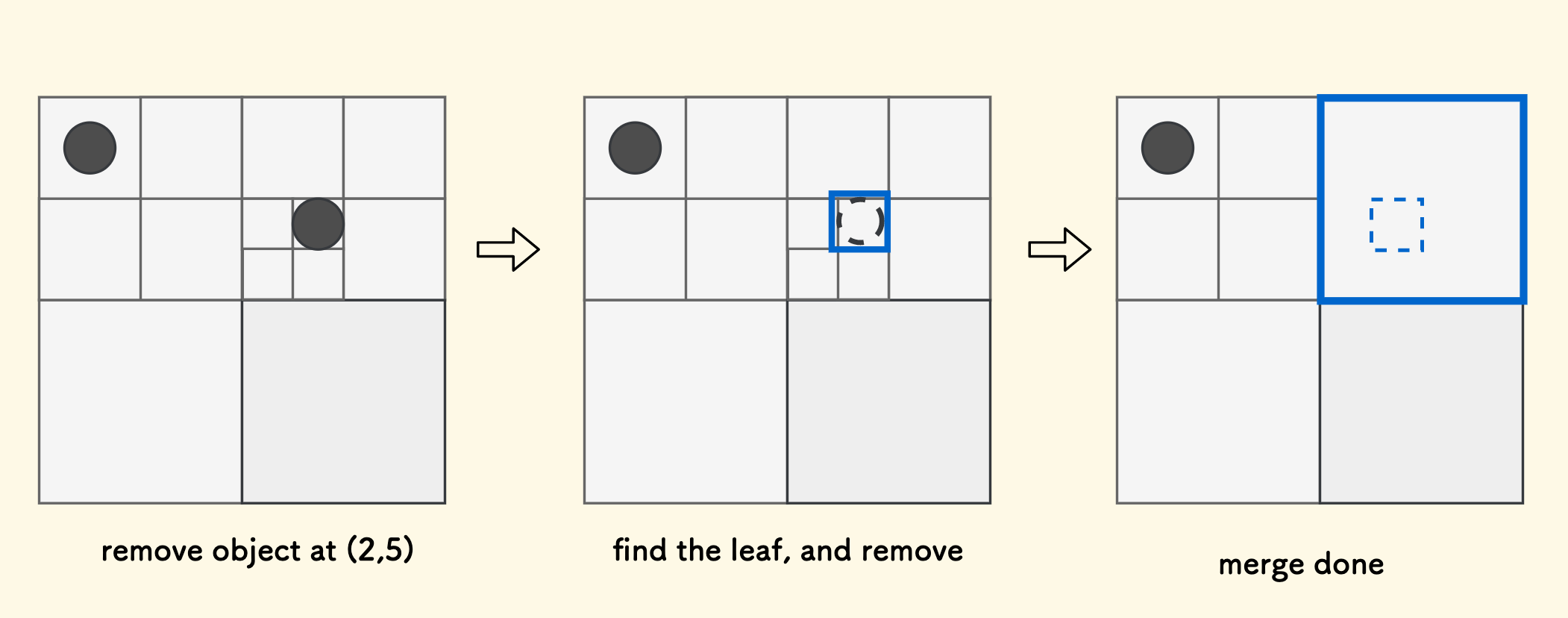
In my implementation, the condition for stopping merging is the opposite of the condition for stopping splitting. A node cannot be merged if it can remain in a “splittable” state. It is still specified by the function ssf.
However, merging also relies on an operation, how to quickly locate the leaf node based on position? It will be discussed later.
After we have implemented the two capabilities of “splitting” and “merging”, this quadtree has the ability to dynamically adjust. Adding and removing objects does not require rebuilding the entire tree, but only needs local adjustments from the leaf nodes downwards or upwards.
Revisiting Termination Conditions ¶
However, we need to confirm one question: is it only when adding objects that splitting is triggered? Or another dual question: is it only when removing objects that merging is triggered?
Actually, this is not the case. The key depends on how the termination splitting condition ssf function is designed.
For example, we want the leaf node to stop splitting when any of the following conditions are met:
- There are no managed objects in the node.
- Every square in the node is an object.
This condition is very suitable for managing fixed obstacles in the map (terrain, buildings, etc.). The quadtree can non-overlappingly place completely empty areas and areas completely filled with obstacles into different leaves.
Use a function to express this strategy:
SplitingStopper ssf = [](int w, int h, int n) {
return (n == 0) || (n == w * h);
};
In this way, it may happen that:
- When adding an object, a large rectangle may be exactly filled, causing merging.
- When removing an object, a full large rectangle may become not full, causing splitting.
A running effect is shown in the following figure:
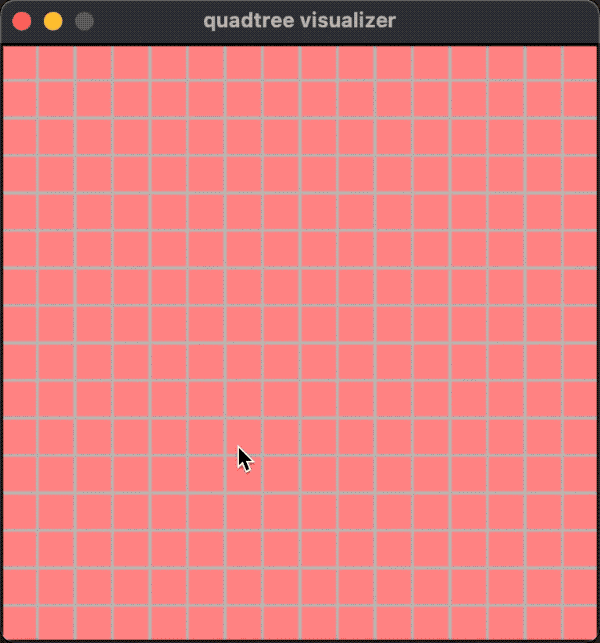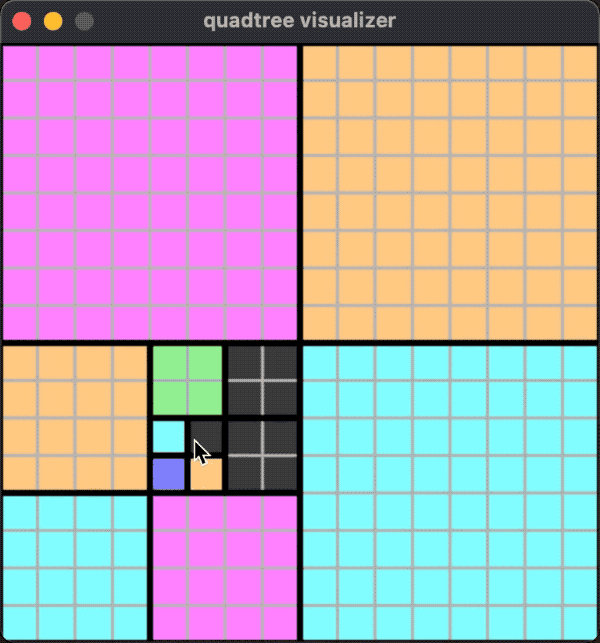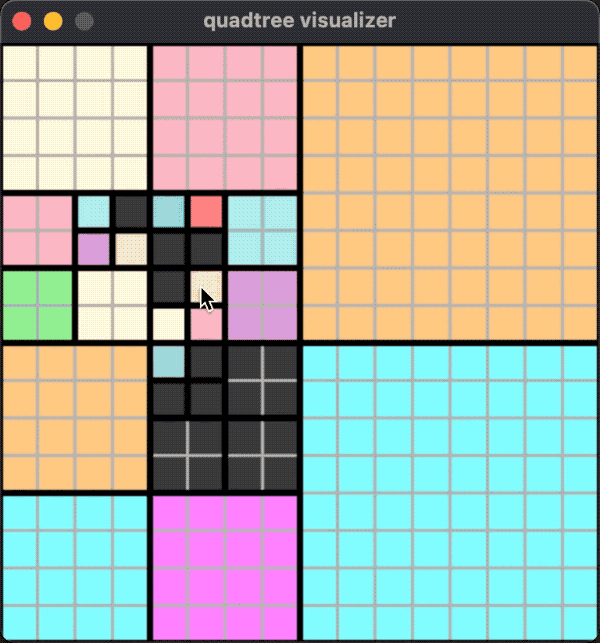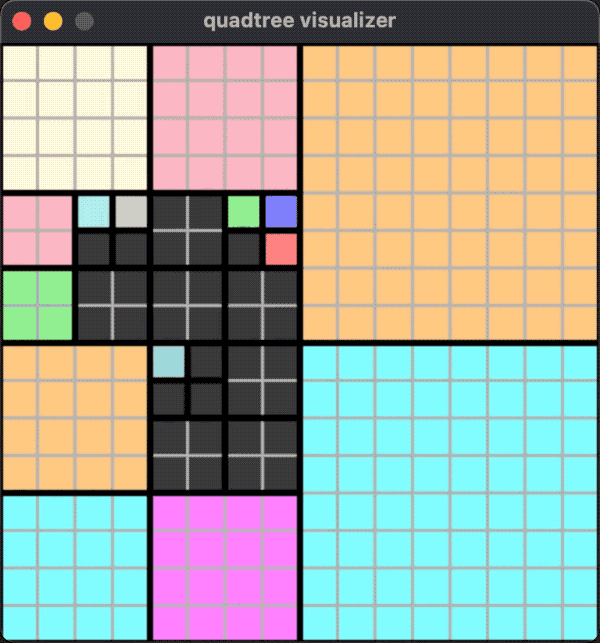
In this case, splitting and merging may occur whether adding or removing objects.
However, in our design, the user-defined condition must be stable, that is, ensure that the conditions for splitting and merging are never satisfied at the same time, and are always opposite.
In my implementation, when adding or removing objects, splitting or merging is attempted, but at most one of the two occurs.
// When adding an object, try splitting first, otherwise try merging
trySplitDown(node) || tryMergeUp(node);
// When removing an object, try merging first, otherwise try splitting
tryMergeUp(node) || trySplitDown(node);
Region Query ¶
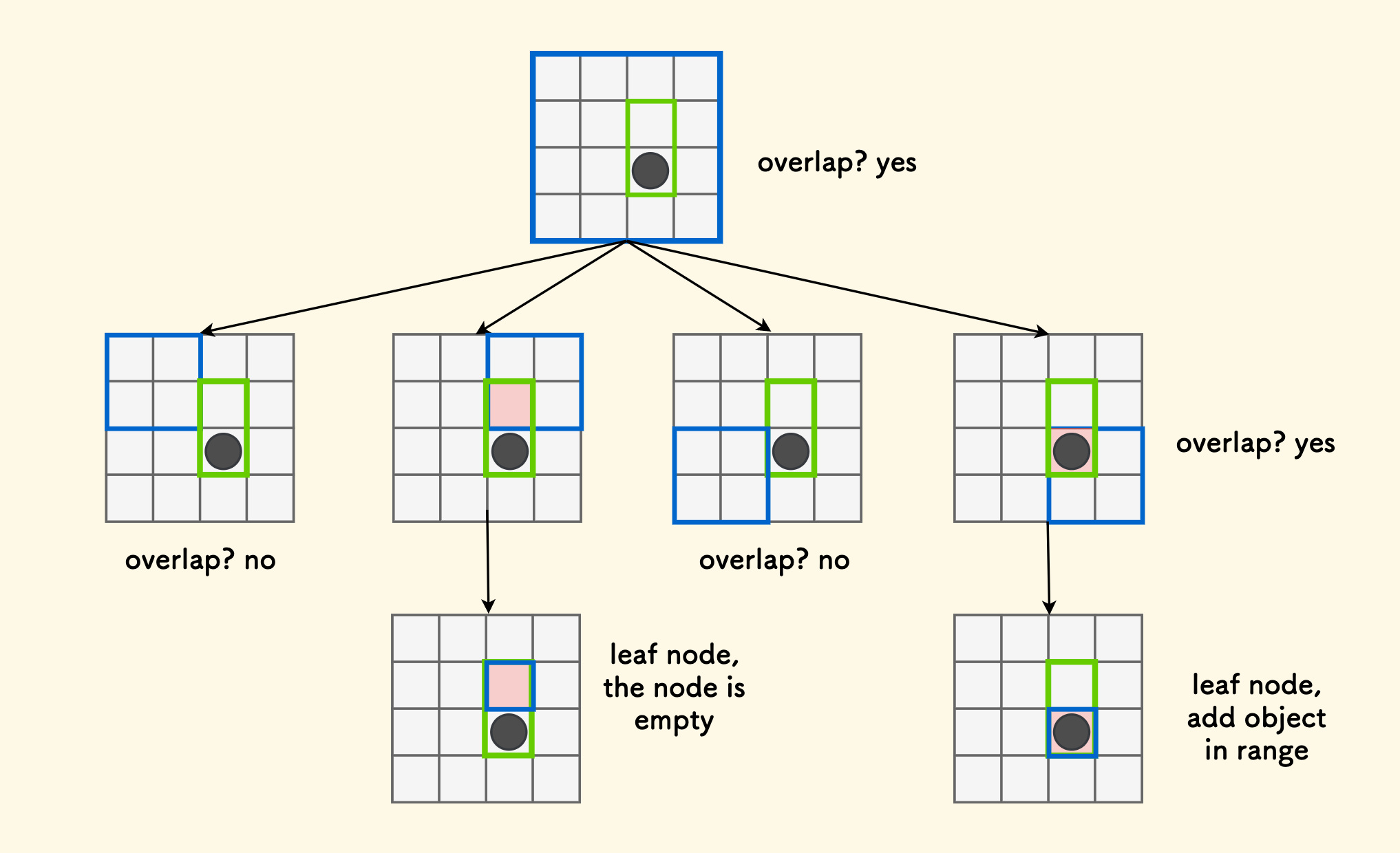
Given a rectangular region, with the top-left corner at $(x1,y1)$ and the bottom-right corner at $(x2,y2)$, how to query all the objects it selects? For example, in the following diagram, the objects hit by the selected green box rectangular region are b and c, but not including a.
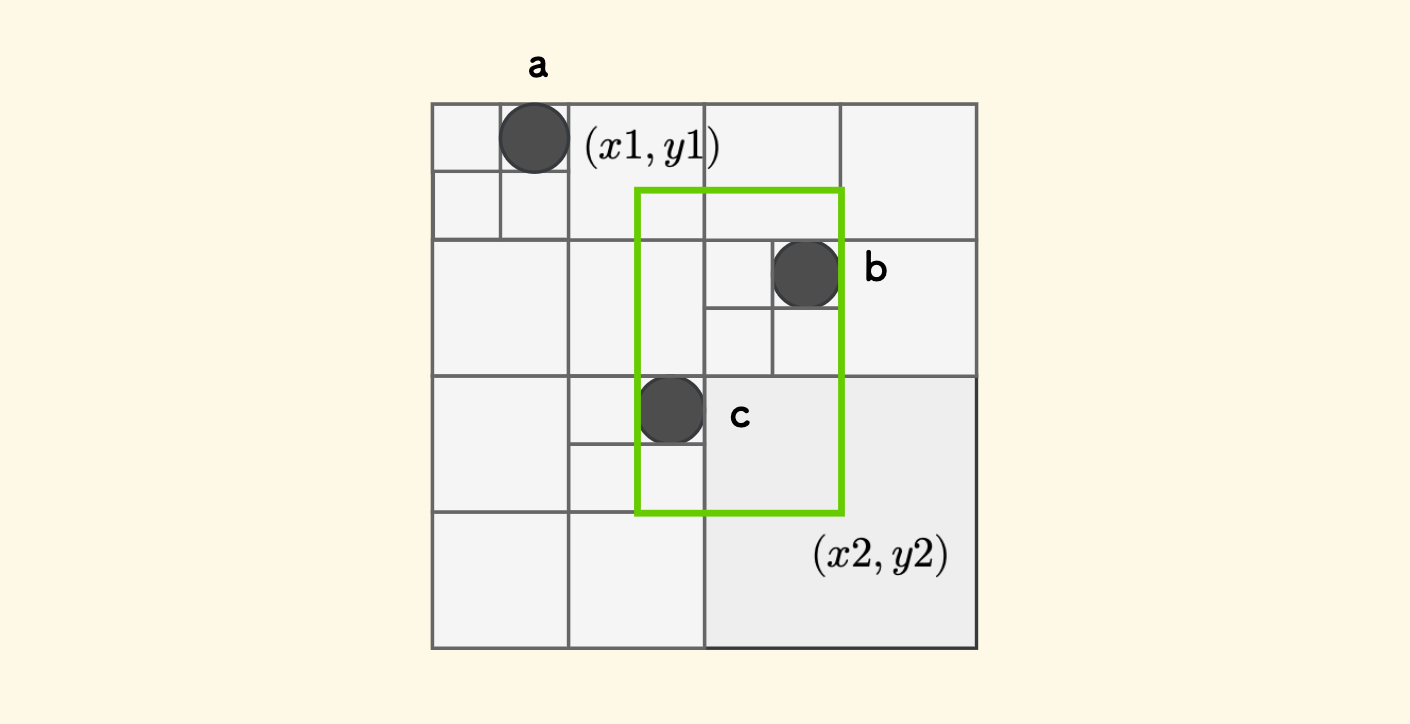
The idea is also very simple, starting from the root node, continuously “judge overlap”. If the rectangle managed by the current node and the rectangle of the query region have intersection overlap, then:
- If the current node is a leaf node, directly collect the objects located within the query region.
- Otherwise, if the current node is a non-leaf node, then continue to judge its child nodes downwards and proceed recursively.
If there is no overlap, there is no need to recurse downwards.
The whole process is shown in the following figure:
So, how to judge whether two rectangles have intersection? Use the simple AABB algorithm, refer to another article AABB Detection of Plane Rectangle Overlap, which only requires one line of code.
Details of Splitting ¶
First, let’s look at the details of the splitting process. Assume that the region governed by the current node has the top-left corner $(x1,y1)$ and the bottom-right corner $(x2,y2)$, then:
- Find the midpoint position of the $x$-axis $x1 + (x2-x1)/2$, defined as $x3$.
- Find the midpoint position of the $y$-axis $y1 + (y2-y1)/2$, defined as $y3$.
Note that the division is rounded down, and the coordinates start from $0$.
That is, both the $x$-axis and $y$-axis are bisected. So, where is the position of this center point? This needs to be viewed by dividing into odd and even parity. The following are schematic diagrams of $4 \times 4$ and $5 \times 5$ specifications:
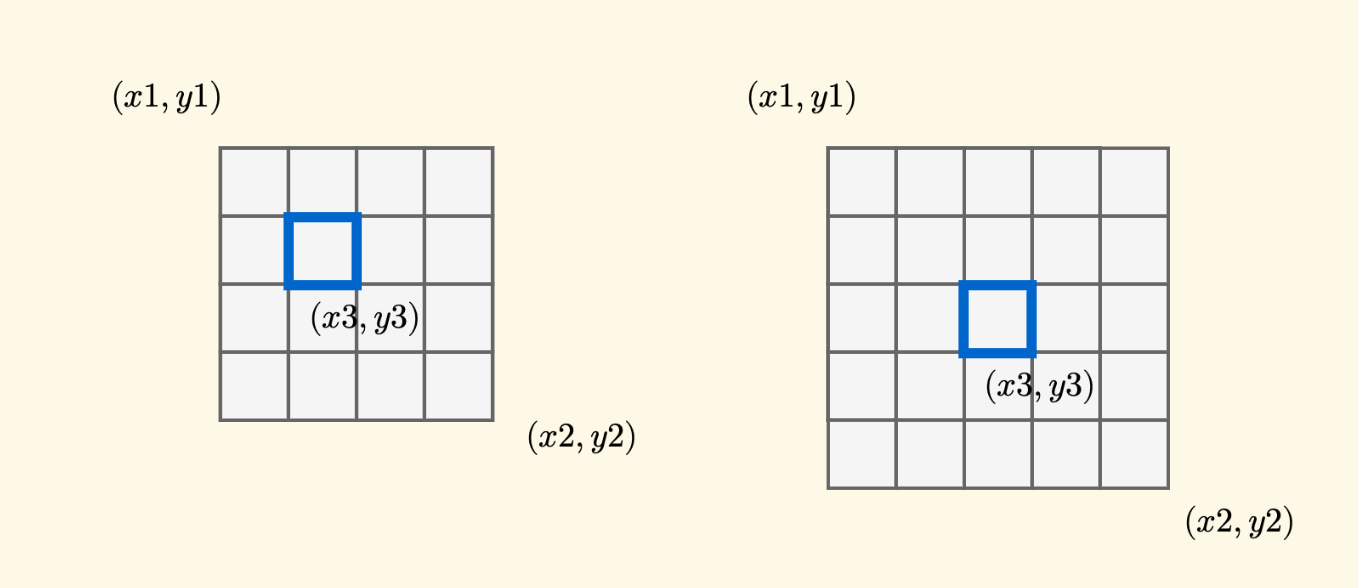
However, regardless of odd or even parity, the rule is unified. The center square $(x3,y3)$ must be located in the most central square. If there is no square in this place, it is the square slightly to its top-left.
Since we are dealing with a gridded region, after splitting, a cell must belong to one sub-rectangle.
Now we can calculate the coordinates of each of the four sub-rectangles after splitting:
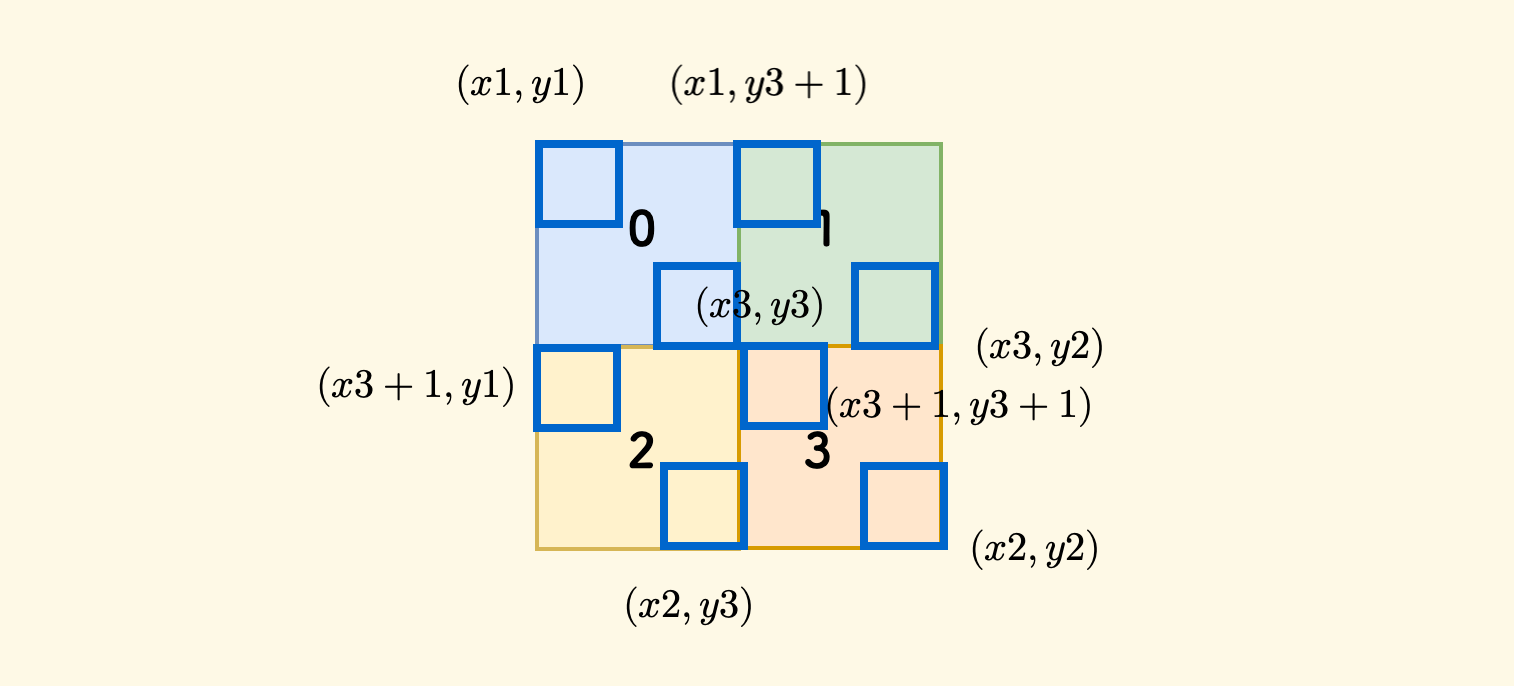
Use code to represent the coordinates and recursive process of these four small rectangles:
// * position is (x3,y3)
// y1 y3 y2
// x1 -+------+------+-
// | 0 | 1 |
// x3 | * | |
// -+------+------+-
// | 2 | 3 |
// | | |
// x2 -+------+------+-
int x3 = x1 + (x2 - x1) / 2, y3 = y1 + (y2 - y1) / 2;
node->children[0] = split(d + 1, x1, y1, x3, y3);
node->children[1] = split(d + 1, x1, y3 + 1, x3);
node->children[2] = split(d + 1, x3 + 1, y1, x2, y3);
node->children[3] = split(d + 1, x3 + 1, y3 + 1, x2, y2);
An Important Conclusion ¶
However, now we want to continue to optimize the details of bisection! The benefits will be seen later.
For the selected midpoints $x3$ and $y3$, assuming the current depth is $d$, and the depth to be split is $d+1$, taking the $x$-axis as an example, we consider whether the values of the formula $2^{d+1}x/h$ at $x1$ and $x3$ are equal. If they are not equal, then $x3$ is decremented by one, and the same for the $y$-axis.
uint64_t k = 1 << (d + 1);
if ((k * x3 / h) != (k * x1 / h)) --x3;
if ((k * y3 / w) != (k * y1 / w)) --y3;
In layman’s terms, it is (taking the horizontal $y$-axis as an example):
By default, the selected midpoint is given to the left, but if the midpoint and the formula value on the left are inconsistent, then let the midpoint be given to the right.
For example, when $w=50$, in the $5$th round, it will choose to be right-biased instead of the default left-biased because of this mechanism.
d
0 [0------------------------------------------------------------50]
1 [0--------------------------------24],[25---------------------50]
2 [0----------------12][13----------24]
3 [0--------6][7----12]
4 [0-3][4---6]
5 [4][56]
Using this bisection method will bring a benefit, which is this conclusion:
For $N$ integers in the $[0,N-1]$ interval, continuously bisect in this way. After the $d$-th round of bisection, the integer $x$ will fall into the $2^{d}x/N$-th small interval.
Here $d$ is counted from $0$, and the interval count is also counted from $0$.
This conclusion can be quickly verified. For example, when $N=5$, test in the $2$nd round, $x=2$ will fall into the $2^{2}\times 2/5$, i.e., the $1$st interval.
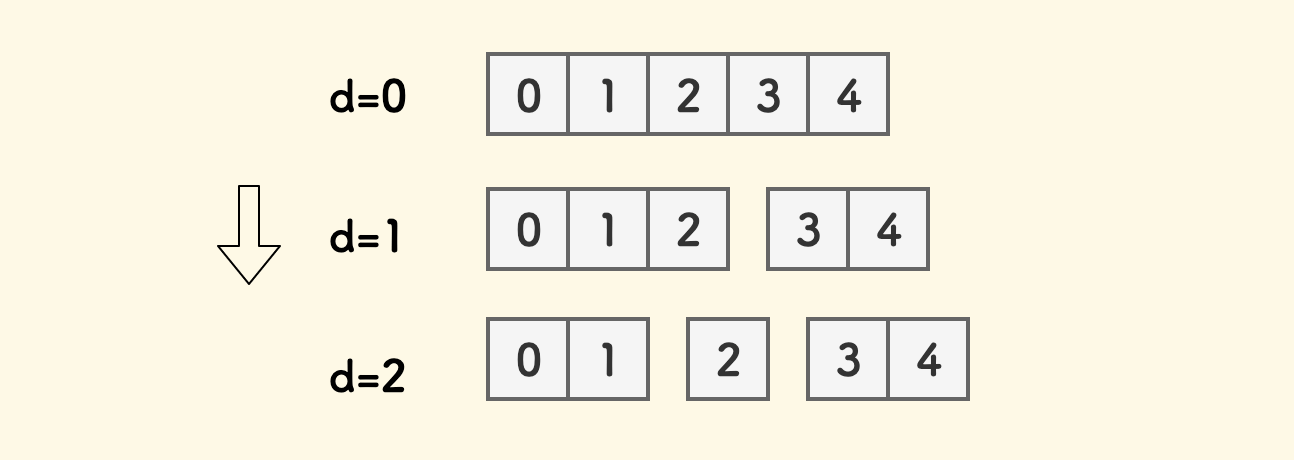
From a mathematical point of view, in the $d$-th round, $2^{d}$ small intervals are equally divided, and the length of each small interval is $k=N/2^{d}$, then the integer $x$ will fall into the $x/k$-th small interval, which is $2^{d}x/N$.
However, for bisection on discrete integer intervals, I currently do not have a rigorous proof (welcome to tell me in the comment area!). But testing shows it is correct.
The midpoint correction technique mentioned above is actually forcibly aligning the splitting method to this conclusion.
Before splitting, the original $y1$ and $y2$ both fall in the $q$-th small interval; after splitting, because the current small rectangle is bisected on the $y$-axis, so, after splitting, assume $y1$ falls in the $q1$-th small interval, then $y2$ must fall in the $q1+1$-th small interval. Then there must be a cell where the formula value growth transition occurs, and the vicinity of this midpoint is the transition point. Then we check this midpoint, and decide which side the midpoint belongs to after splitting according to its actual formula value to ensure the correctness of this conclusion.
Based on this conclusion, we can get a similar two-dimensional conclusion, just need to determine each axis in turn.
For a node located in the $d$-th layer, for any position $(x,y)$ within its governing region, we have:
Position $(x,y)$ must be located in the $(2^{d})x/h$-th small rectangle on the $x$-axis and the $(2^{d})y/w$-th small rectangle on the $y$-axis.
Among these, $w$ and $h$ are the width and height of the entire region respectively, $d$ is counted from $0$, and the count is also counted from $0$.
In addition, it should be noted that our coordinate system has always been $x$-axis vertically downwards, $y$-axis horizontally to the right, and the top-left corner $(0,0)$ is the origin of the coordinate system.
The following figure is a schematic diagram on a $4 \times 5$ grid. The green position is $(2,2)$, and the red box indicates the small rectangle it is located in each layer of nodes:
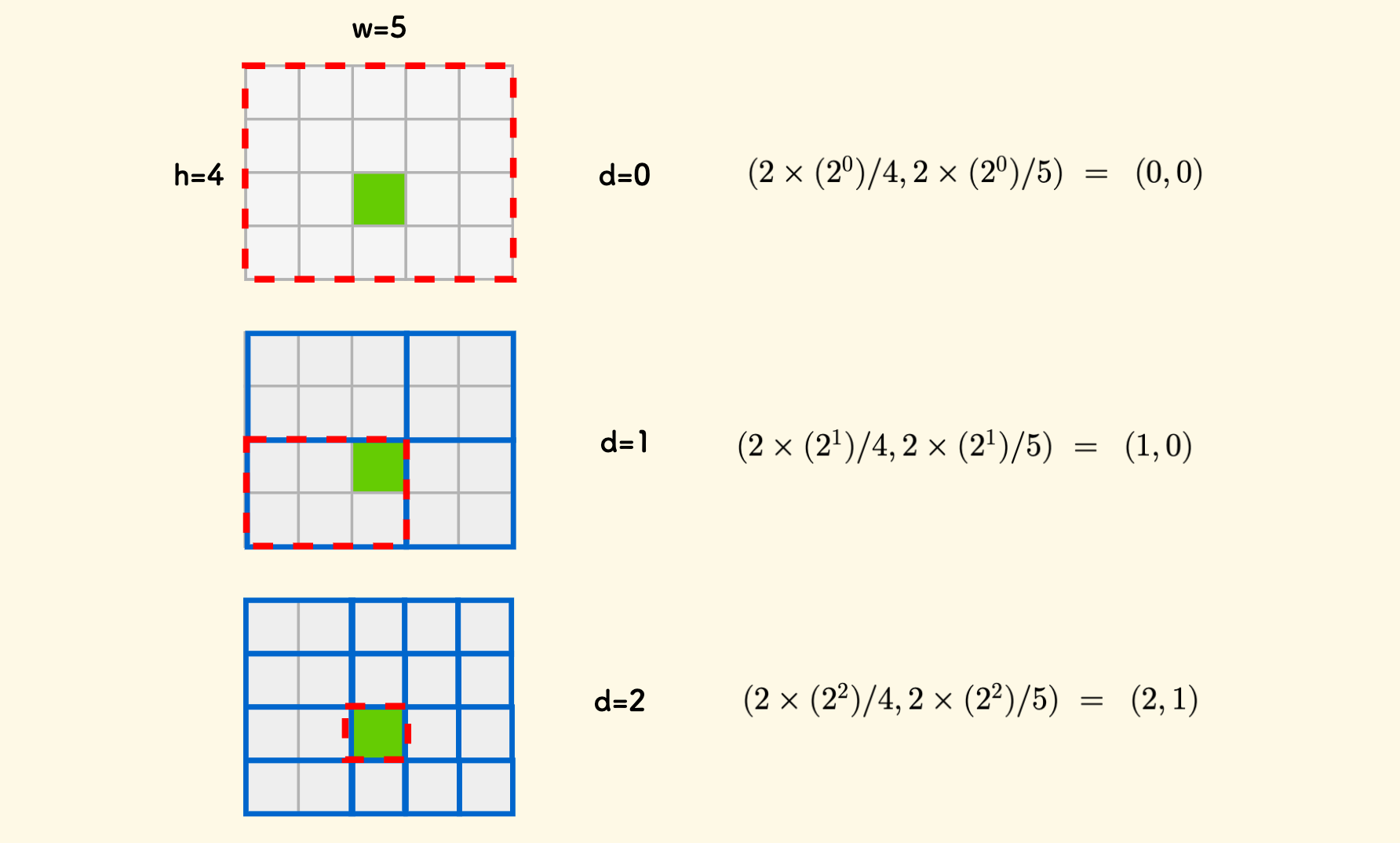
In simpler terms, for each axis, consider the level of subdivision at the current depth. Then, count how many small intervals of that subdivision level fit within the coordinate from the origin.
Speaking of this, how to quickly locate the leaf node to which a position belongs is ready to emerge.
Quickly Locating Leaf Nodes ¶
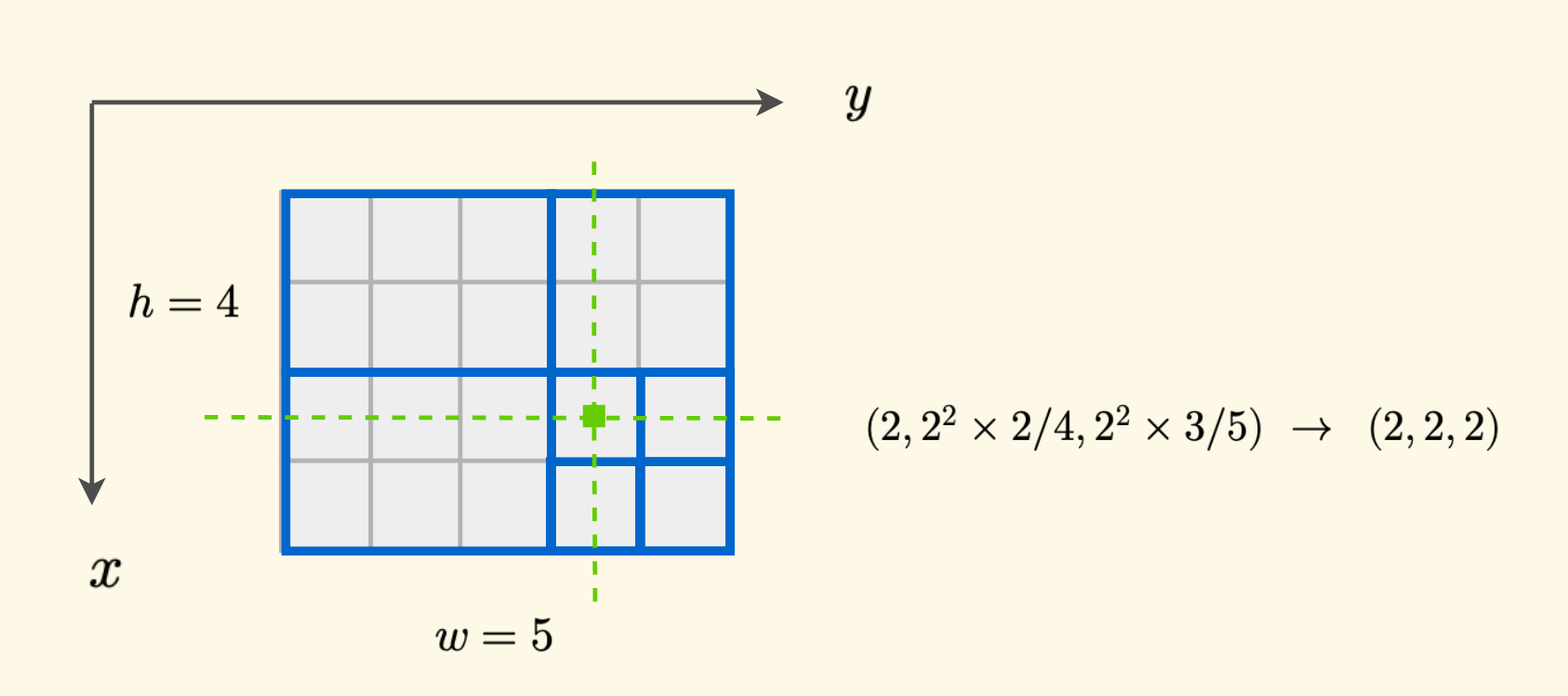
Now design an ID number for each node, which is composed of a triplet $(d, 2^{d}x/h, 2^{d}y/w)$, where $d$ is the depth of this node (layer number). A hash function can be made to map this triplet to an integer.
Then, it can be known that:
For any position $(x,y)$ within the governing region of the node, the calculated ID is consistent.
For example, in the figure below, the ID of the node where the target position is located is $(2,2,2)$.
In the specific implementation, I used a uint64 type to represent the node number:
- The highest 6 bits are used to store the depth of the node $d$.
- The middle 29 bits and the lower 29 bits are used to store the second and third terms respectively.
In this way, the width and height of the entire region cannot be greater than $2^{29}-1$, which is already sufficient, and the depth cannot be greater than $29$.
The C++ implementation for calculating ID is mainly to find the bitmask:
uint64_t pack(
uint64_t d, uint64_t x, uint64_t y, uint64_t w, uint64_t h) {
// 0xfc00000000000000 : The highest 6 bits are all 1, and the rest are 0
// 0x3ffffffe0000000 : The highest 6 bits are all 0, the next 29 bits are all 1, and the rest are all 0
// 0x1fffffff : The lowest 29 bits are all 1, and the rest are all 0
return ((d << 58) & 0xfc00000000000000ULL) |
((((1 << d) * x / h) << 29) & 0x3ffffffe0000000ULL) |
(((1 << d) * y / w) & 0x1fffffffULL);
}
In this way, we can build a hash table to store the mapping from ID to node pointer.
When searching for the leaf node where a position $(x,y)$ is located, the key is to determine the depth $d$. Because $d$ is very limited, of course, traversing it is not impossible. It can be faster, that is, binary search for the answer:
- We pre-maintain the height $maxd$ of the entire tree, and then the initial feasible domain is $[0, maxd]$, set $l=0$ and $r=maxd$.
- Then binary search $m = (l+r)/2$, use the
packfunction to calculate the ID. If no node can be found in the hash table, it means the guess is too large, and the upper bound should be shrunk $r=m-1$. - Otherwise, if it exists in the hash table, then see if it is a leaf node. If it is a leaf node, it has already hit. If not, it means it is an intermediate non-leaf node, and the guess is too small, and the lower bound should be shrunk $l=m+1$.
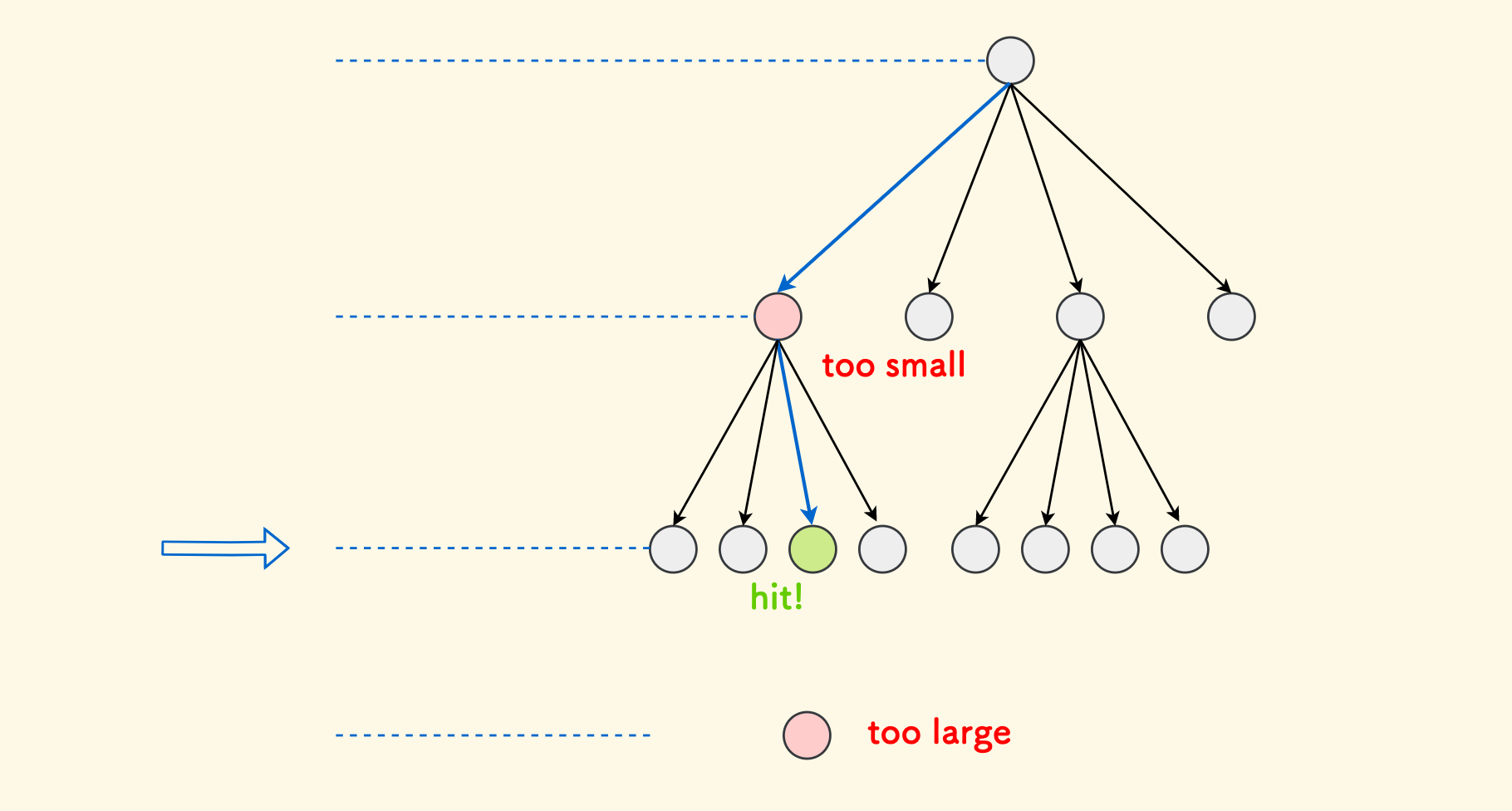
In this way, the time complexity of locating a leaf node is only $O(\log {maxd})$.
One might wonder if this optimization is significant, considering that the maximum depth maxd is only $29$. But if we search downwards layer by layer from the root node, it is much slower to find the node where $(x,y)$ is located layer by layer.
Using such an ID numbering and hash table design, there is another benefit. To find the parent node of a node node, you only need to substitute the previous depth and calculate pack(d-1, node->x1, node->y1) to find the parent node number.
Another detail is that because the maximum depth $maxd$ is maintained and dynamic merging is supported, the maintenance of $maxd$ becomes slightly complicated when leaf nodes are destroyed. The trick is to maintain the number of nodes at each depth value at the same time. In this way, $maxd$ will only shrink when the last node with depth $maxd$ is destroyed.
--numDepthTable[node->d];
if (node->d == maxd) {
// Only when the last leaf node at the maximum depth is destroyed, it is necessary to reduce maxd
// The number of iterations does not exceed maxd (<29)
while (numDepthTable[maxd] == 0) --maxd;
}
delete node;
Optimizing Region Queries ¶
This part is an added update on 2024/08/06.
It is possible that the region range we query each time is not large. For example, if we only want to query some game objects near the current position, is it necessary to start searching downwards from the root node every time?
For example, for the blue query region below, the queried objects are highlighted in green. At this time, we only need to find the node outlined by the red box, and search downwards from this red node, instead of starting from the root node.
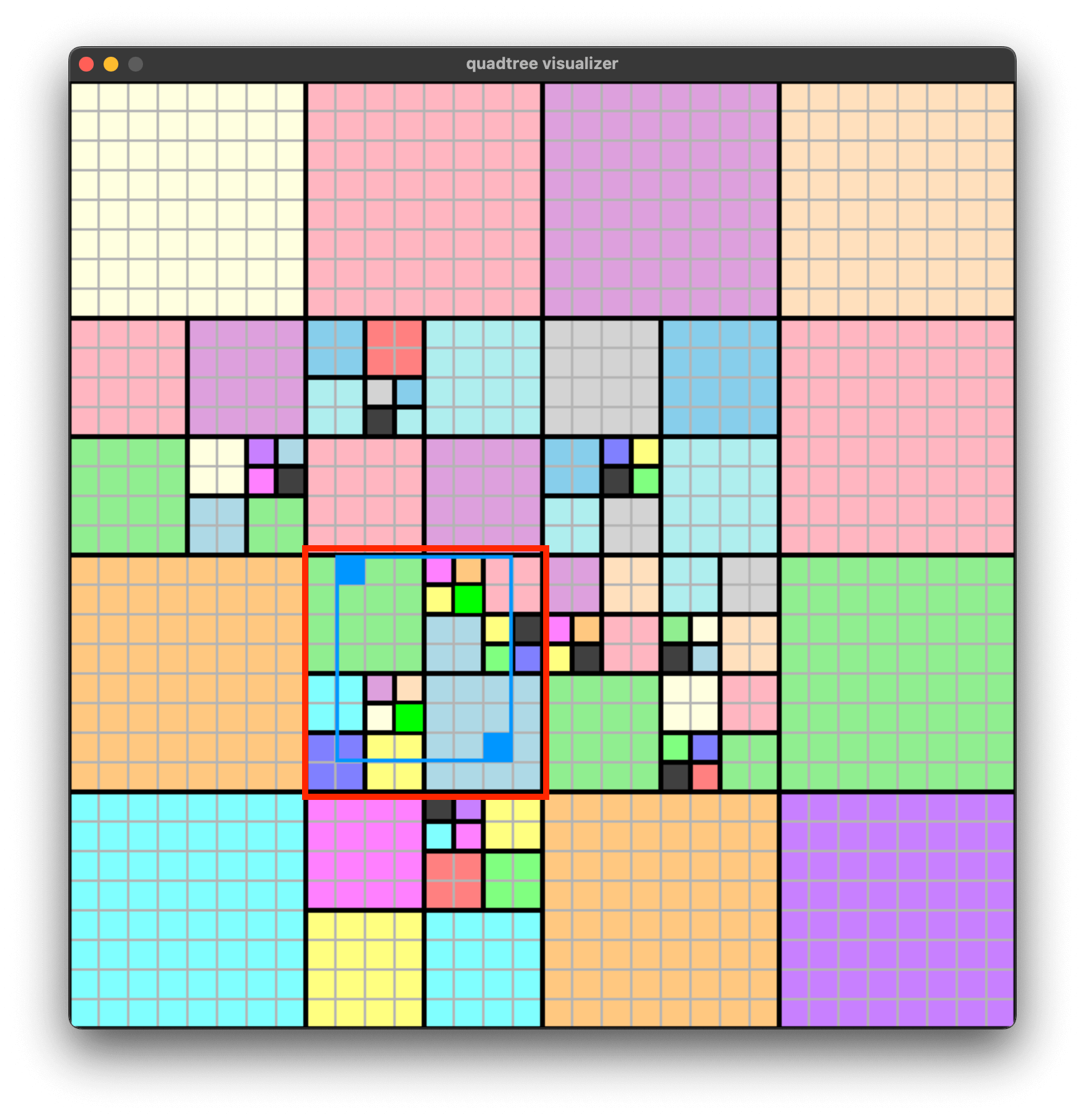
So, how to find such a node first? Actually, it is to find the smallest node that simultaneously contains the top-left and bottom-right corners of the query region.
Let’s continue to abstract this problem. Assume that the top-left corner of the input query region is point $a$ and the bottom-right corner is point $b$. The smallest node that simultaneously contains these two squares is $Q$. Then:
- For $Q$, and all its ancestor nodes, they must also simultaneously contain the two squares $a$ and $b$.
- For all descendant nodes of $Q$, they must not simultaneously contain the two squares $a$ and $b$.
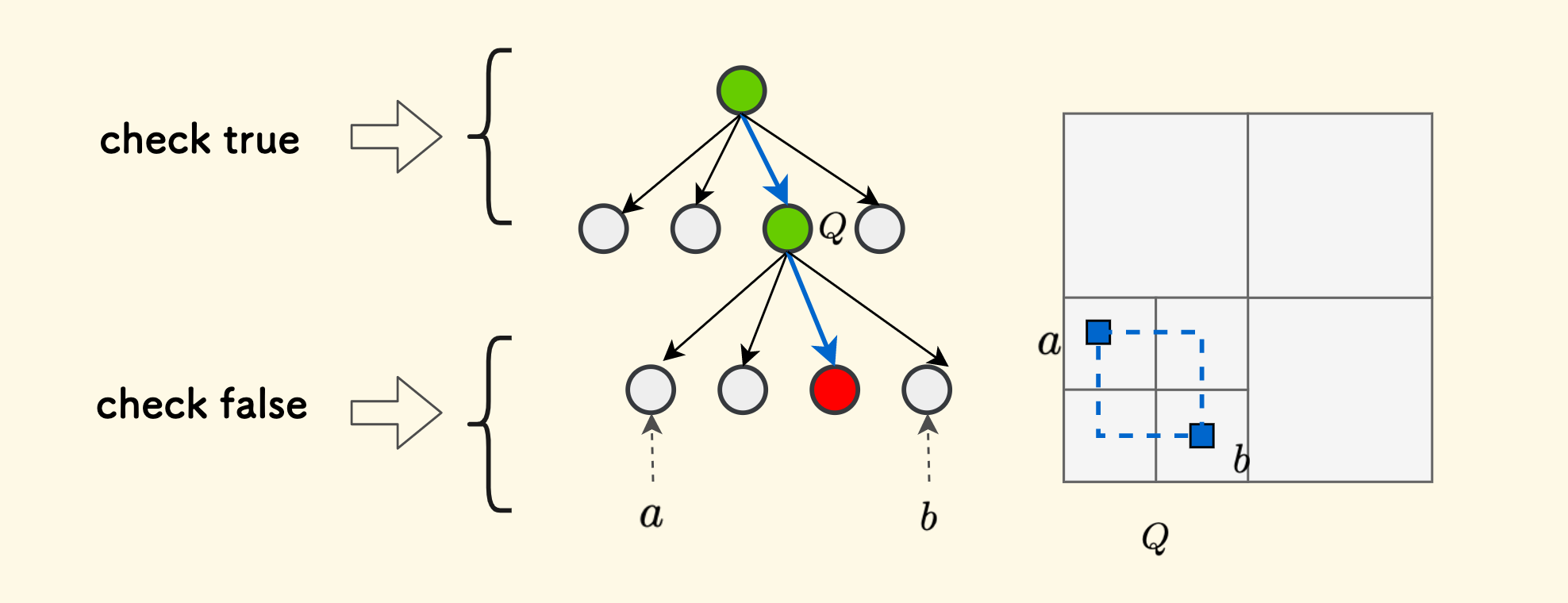
This has a two-stage property, implying that we can perform binary search. The key is to guess a depth $d$. Binary search for the upper bound that satisfies the following condition:
The nodes to which $a$ and $b$ belong at depth $d$ both exist, and the numbers are consistent, that is, the same node.
The code implementation is roughly:
C++ implementation of finding the smallest node covering two points
Node* findSmallestNodeCoveringRange(int x1, int y1, int x2, int y2) const {
int l = 0, r = maxd;
Node* node = root;
while (l < r) {
int d = (l + r + 1) >> 1;
auto id1 = pack(d, x1, y1, w, h);
auto id2 = pack(d, x2, y2, w, h);
if (id1 == id2) {
auto it = m.find(id1);
if (it != m.end()) {
// At depth d, the two points are in the same node
l = d;
node = it->second;
continue;
}
}
// Otherwise, the guess is too large, shrink the upper bound
r = d - 1;
}
return node;
}
In this way, for small region range queries, the number of AABB overlap detection judgments is reduced.
Querying Neighbor Nodes ¶
This part is an added update on 2024/08/06.
My original purpose for learning quadtrees was not to optimize collision detection, but to do a test of hierarchical A* pathfinding based on quadtrees. This requires a function, namely:
How to find the neighbor leaf nodes of a quadtree leaf node?
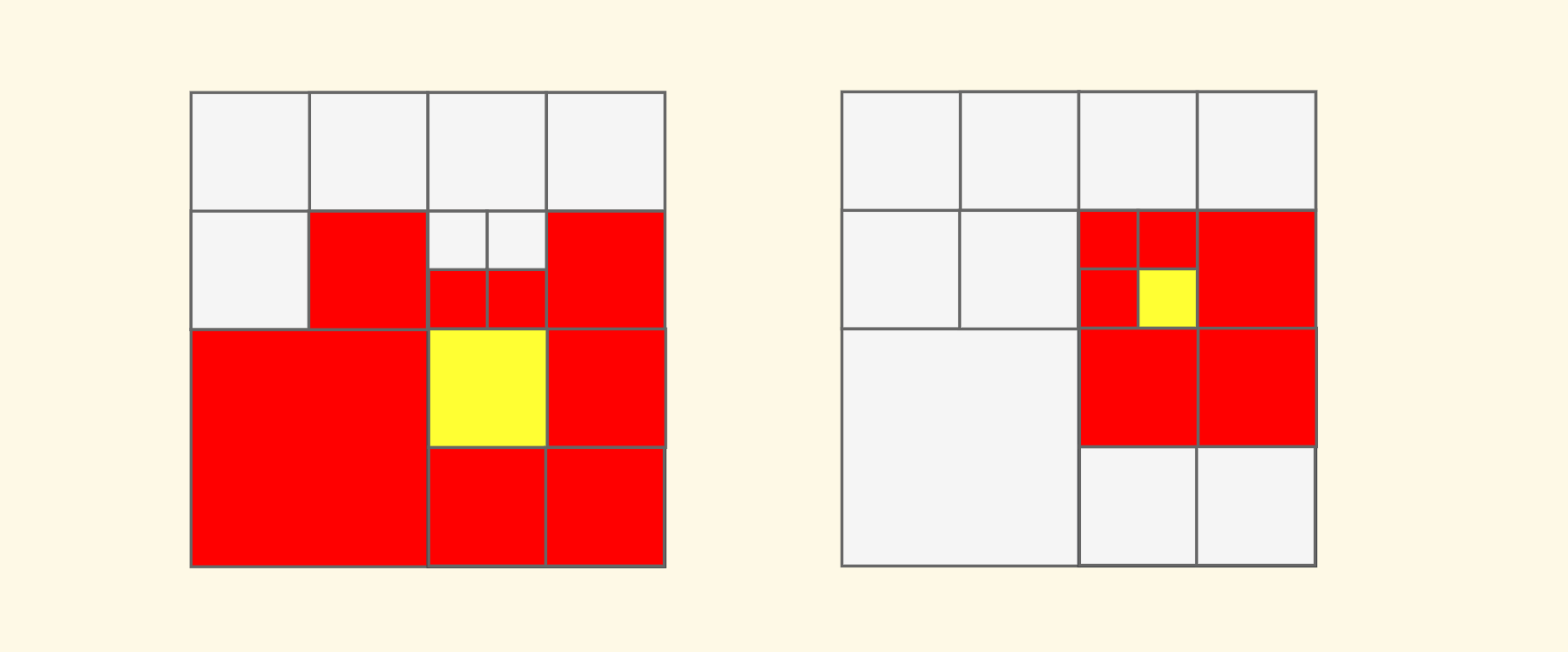
For example, in the following two schematic diagrams, the red nodes are the neighbors of the yellow node we are looking for. Note that we support neighbors in eight directions (including diagonal):
Let’s define the problem first. The input is a node and a direction (optional 8 enumeration values), and then output the neighbor node in this direction.
We should note that a neighbor in one direction is not necessarily only one leaf node, nor is it necessarily its sibling node.
First of all, the diagonal direction is the easiest to handle, because there is definitely only one neighbor node in a diagonal direction.
The idea is relatively simple, find the nearest diagonal position $p$, and then reuse the ability mentioned earlier to directly locate the leaf node where it is located. The time complexity is $O(\log{Depth})$.
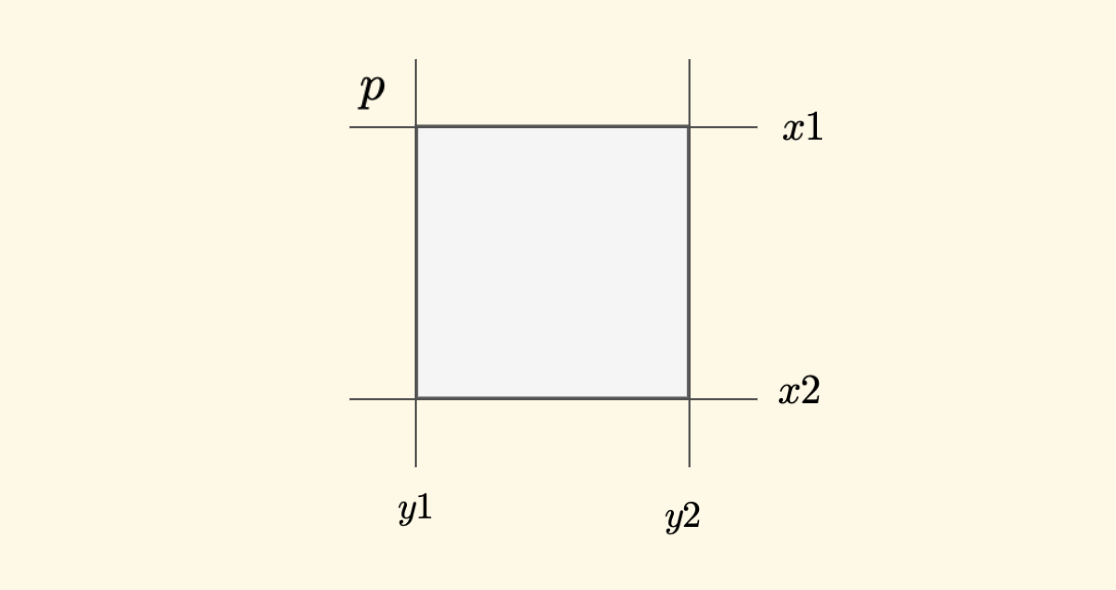
Taking the top-left direction as an example, the region of the small rectangle governed by the current node is $(x1,y1)$ and $(x2,y2)$. Then, the top-left adjacent point $p$ is $(x1-1,y1-1)$, and then locate the leaf node to which this position belongs. The other three diagonal directions can be done in the same way.
For non-diagonal directions, it is slightly more complicated. There are two situations here. Taking the north direction (above) as an example, it is possible that the side length of the neighbor above is greater than or equal to the current node, and it is also possible that the above is multiple small side length neighbors. The following figure is a schematic diagram of these two situations. Still, yellow represents the current node, and red represents the neighbor node:
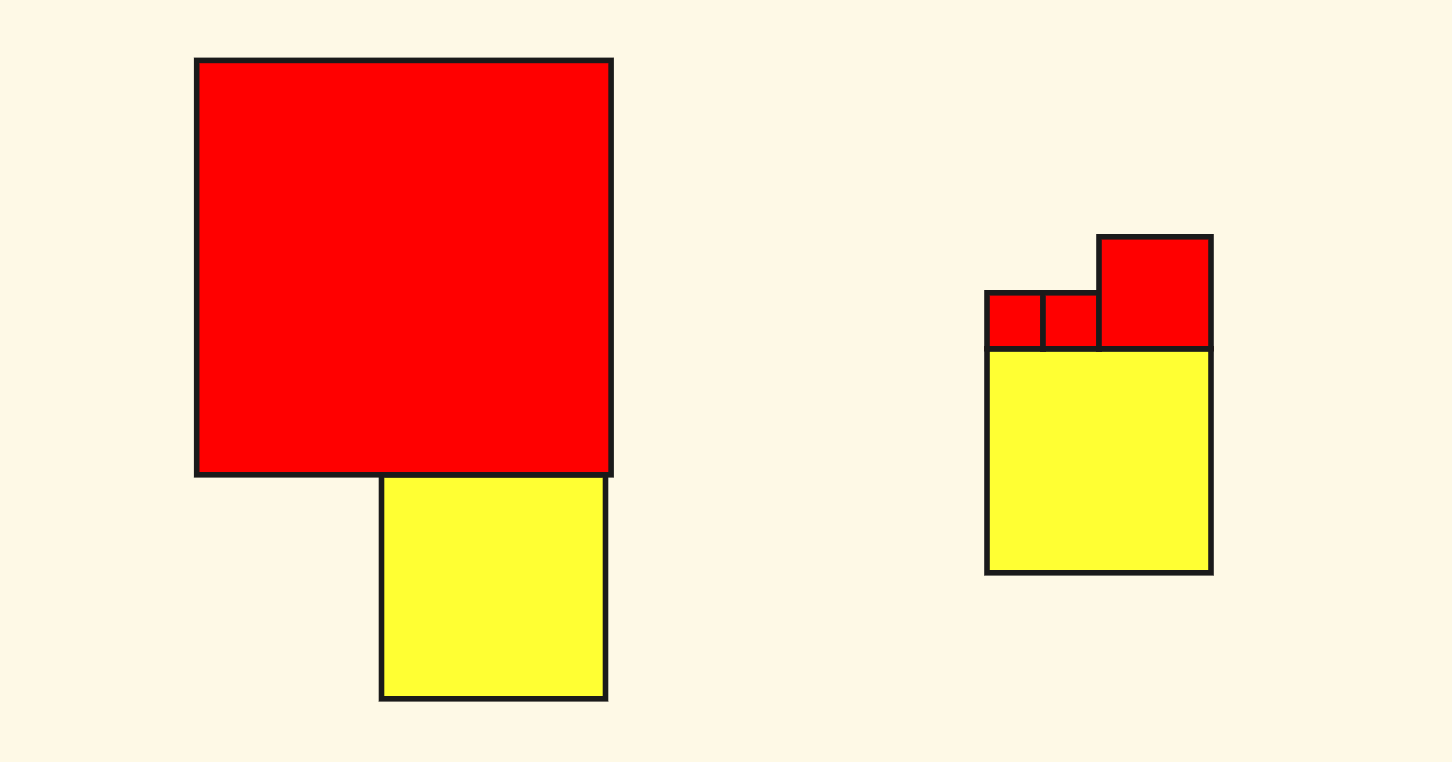
However, in any case, we can first find the neighbor node above whose side length is not less than the current node (it may not be a leaf node), and then recursively search downwards for leaf nodes that are closely adjacent to the current node as the answer.
Still taking the north direction as an example, in any case, the neighbor node of the current node in the north direction must be in a neighbor node whose side length is not less than the current node. That is to say, we assume that the neighbor node to be found is in a large node containing the blue box below. The side length of this box is not less than the current node.
- If this blue box exists in a large leaf node, then this leaf node is the only answer.
- If this blue box is an intermediate node, then recursively search downwards from this node for child nodes in the “south” direction until the leaf node, which are all the answers.
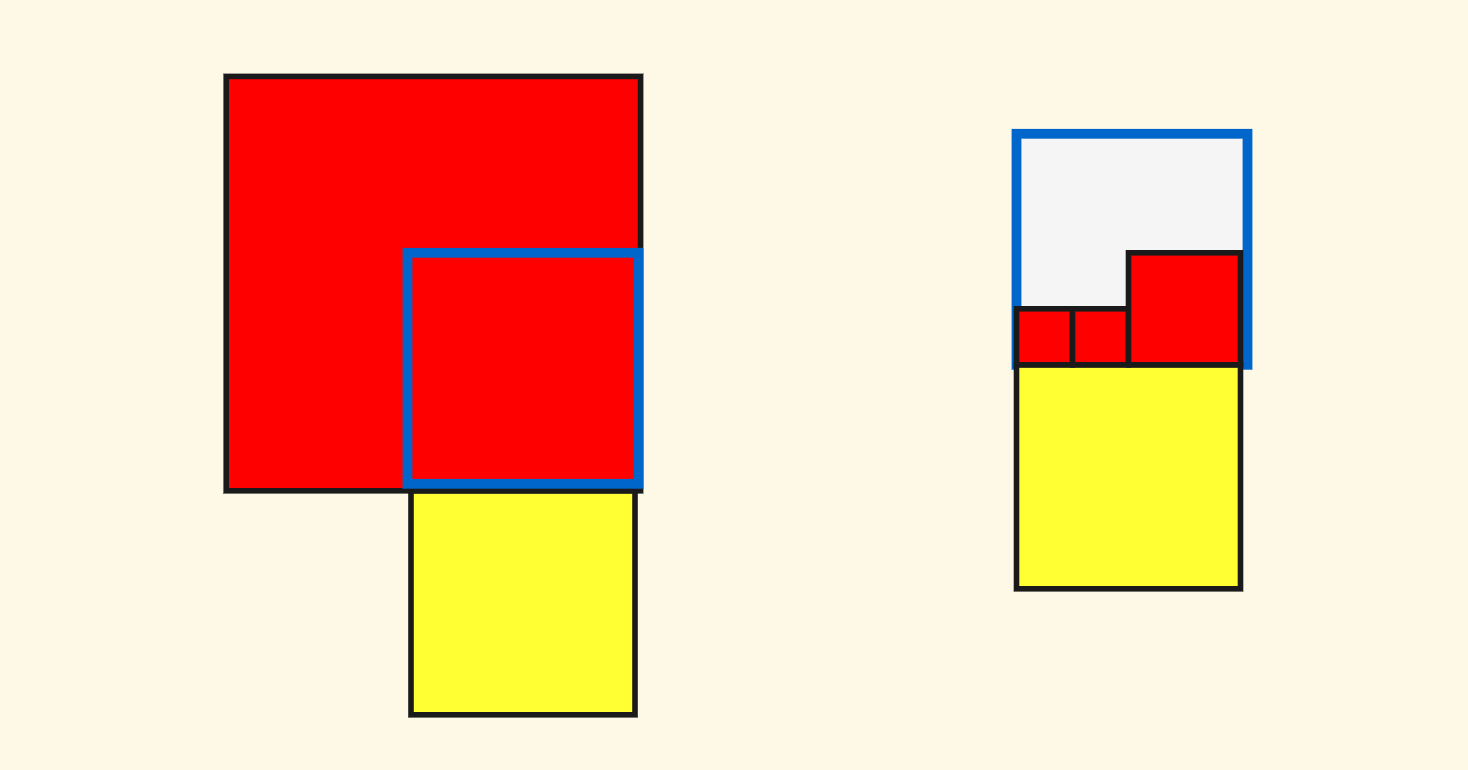
Now we can further clarify the problem. What is the node that contains the “blue box”? Still select two neighbor position points $a$ and $b$. The node that simultaneously contains these two positions is the node where the blue box is located!
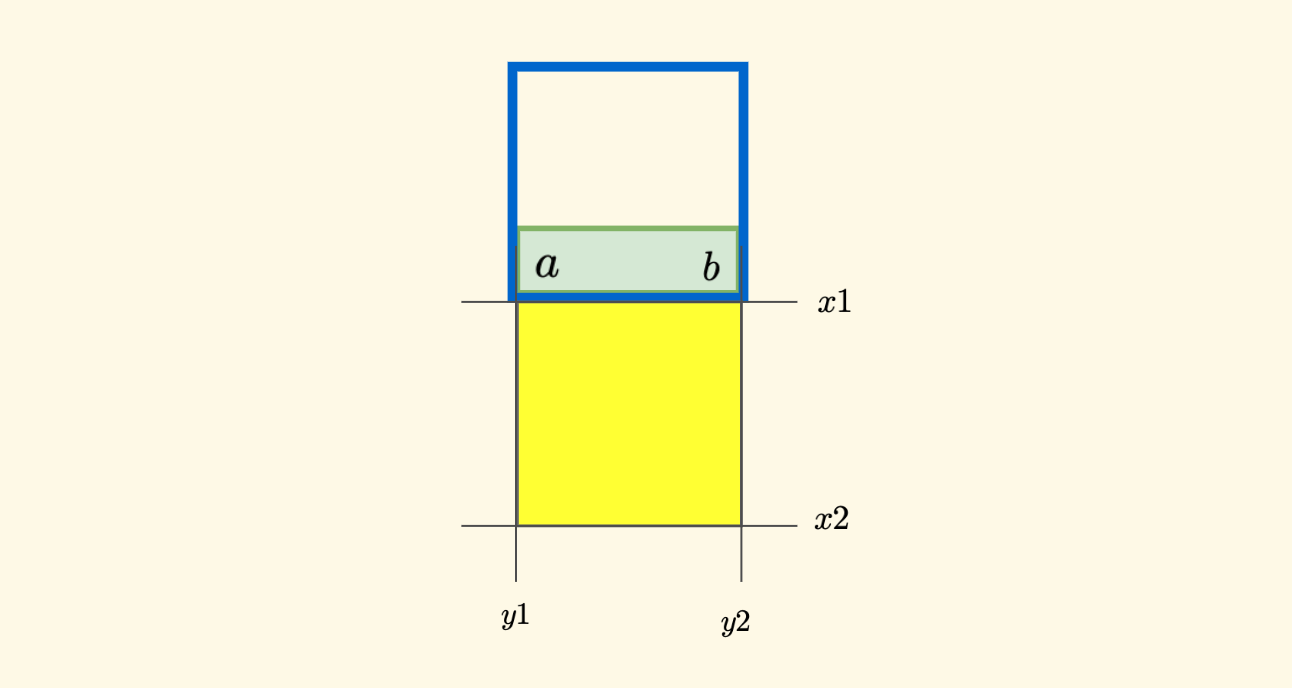
The selection of these $a$ and $b$ points is similar to the $p$ point mentioned earlier. In the north direction, it is: $(x1-1,y1)$ and $(x1-1,y2)$. After such selection, the node that simultaneously contains these two positions must have a side length not less than the current node. And how to find such a node? You can reuse the findSmallestNodeCoveringRange function in the Optimizing Region Queries section mentioned earlier. The time complexity is $O(\log{Depth})$.
After determining this node, if it is a leaf node, then the search ends, and there is only one answer. But if it is not a leaf node, then continue to recurse downwards to find the “south”-side descendant nodes.
There is a detail here, that is, because my quadtree supports rectangles (not necessarily squares), that is, it should be noted that the child nodes in a node are not always $4$. The possible child node layout situations are:
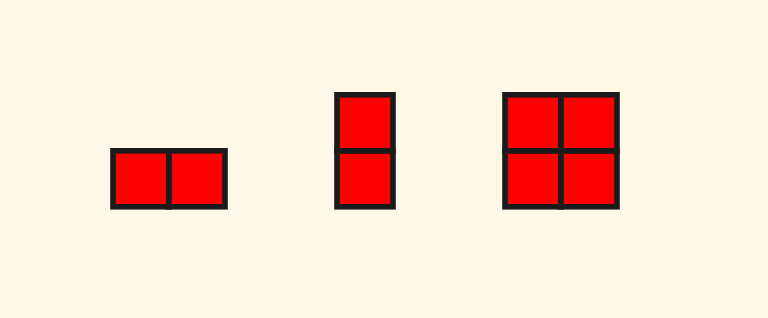
Among these, for the case of two nodes, special treatment is needed. For example, in the first case of horizontal two child nodes, when querying north-south neighbors, all of them should be selected for recursion, while when querying east-west neighbors, only one can be selected.
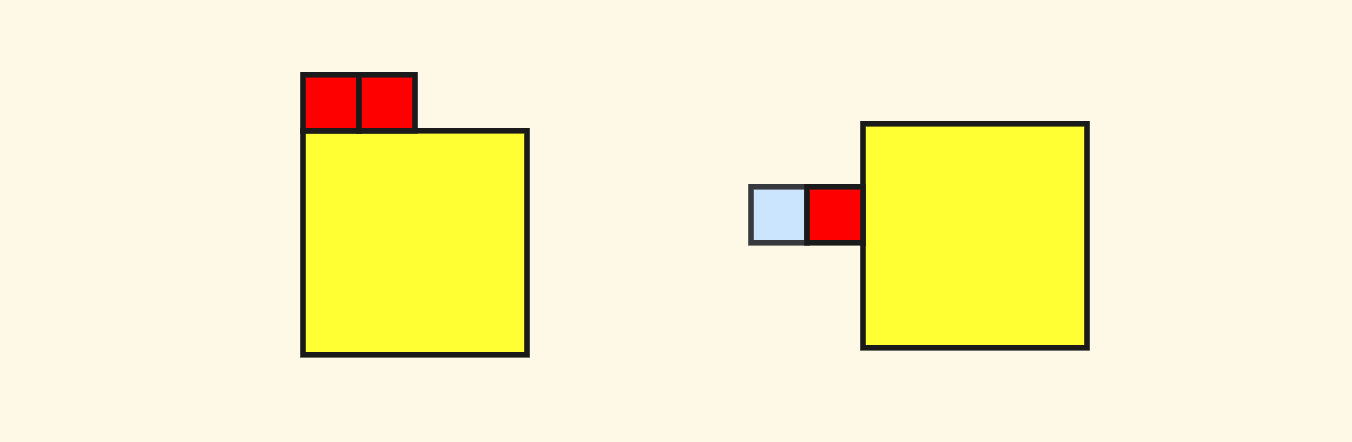
For the case of the standard child node layout of $4$ nodes, it will be relatively simple. For example, when querying north neighbors, only the two child nodes in the south should be selected for recursion:
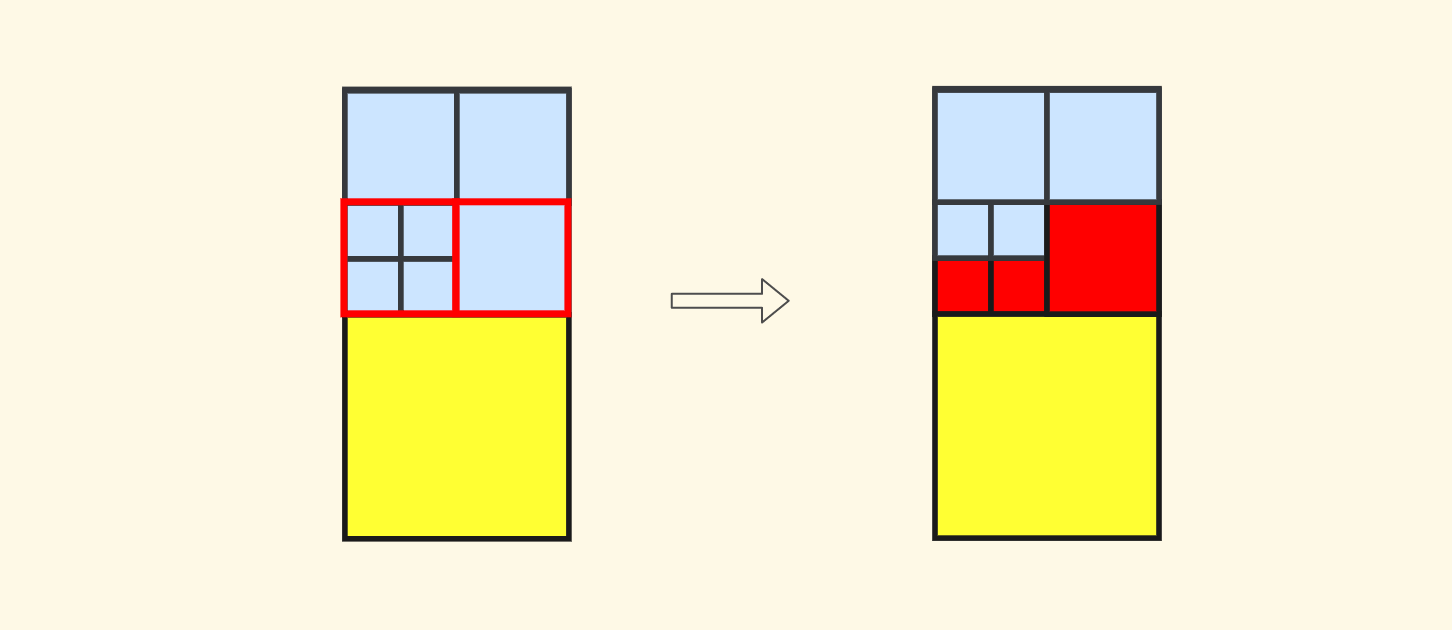
The code is not directly reflected in the article, you can directly look at the implementation in the repo, there are some additional details.
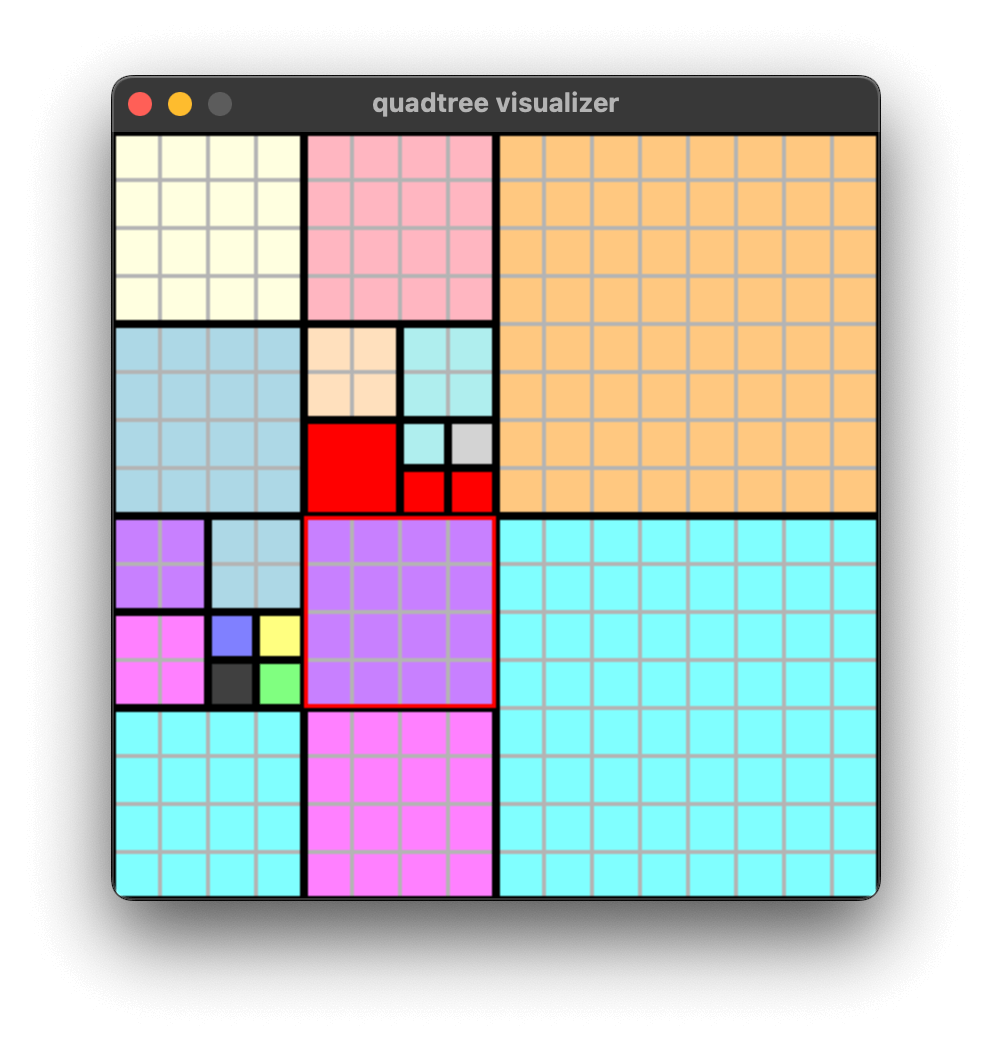
The implementation effect is shown in the following figure, querying the northern neighbor leaf nodes of the red box node:
Conclusion ¶
Finally, welcome to give a small star! https://github.com/hit9/quadtree-hpp
Also, also, also, there is a fun Quadtree Art thing, you can check it out: https://www.michaelfogleman.com/static/quads/.

(End)
Please note that this post is an AI-automatically chinese-to-english translated version of my original blog post: http://writings.sh/post/quadtree.
Original Link: https://writings.sh/post/en/quadtree