I recently started learning C++ and encountered the problem of decoding utf8 byte strings to unicode codepoints. C++ does not have built-in unicode support. The codecvt_utf8 in the standard library, used for utf8 encoding and decoding, has also been marked as deprecated in C++17. The community still has many open-source solutions, such as the famous simutf, utfcpp, etc. Among them, two short and interesting ones are worth a look:
- A DFA state machine based utf8 decoder: bjoern dfa utf8 decoder
- A branchless utf8 decoder: A Branchless UTF-8 Decoder
This made me feel that utf8 encoding and decoding are not that complicated, so I tried to make one myself:
https://github.com/hit9/simple-utf8-cpp
This article will introduce utf8’s encoding format, encoding method and this state machine based decoding method that I implemented.
Encoding Format ¶
From the rfc3629 document, the rules for utf8 encoding are as follows:
Char. number range | UTF-8 octet sequence
(hexadecimal) | (binary)
--------------------+---------------------------------------------
0000 0000-0000 007F | 0xxxxxxx
0000 0080-0000 07FF | 110xxxxx 10xxxxxx
0000 0800-0000 FFFF | 1110xxxx 10xxxxxx 10xxxxxx
0001 0000-0010 FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
It can be seen that:
- utf8 is a variable-length encoding format, one unicode codepoint can be encoded into 1~4 utf8 bytes.
- The highest two bits of a continuation byte are both
10, which is in the form of10xxxxxx. - If the first highest bit is
0, which is in the format of0xxxxxxx, the entire codepoint is 1 byte. - If the highest three bits are
110, which is in the format of110xxxxx, the entire codepoint is 2 bytes, and continuation bytes need to be further examined. - And so on for the cases of 3 bytes and 4 bytes.
A more detailed format is as follows, where the red part represents the high-bit identifier, and the blue part represents the data itself. It can be seen from this the mapping relationship between the codepoint number and each bit in the utf8 byte:
bytes | utf8 sequence | codepoint number
-------+----------------+-------------------------------
1 | 1st. 0xxxxxxx | 0xxxxxxx
-------+----------------+-------------------------------
2 | 1st. 110xxxxx | 0xxx xxyyyyyy
| 2nd. 10yyyyyy |
-------+----------------+-------------------------------
3 | 1st. 1110xxxx | xxxxyyyy yyzzzzzz
| 2nd. 10yyyyyy |
| 3rd. 10zzzzzz |
-------+----------------+-------------------------------
4 | 1st. 11110xxx | 000xxxyy yyyyzzzz zzwwwwww
| 2nd. 10yyyyyy |
| 3rd. 10zzzzzz |
| 4th. 10wwwwww |
Codepoint Counting ¶
First, given a utf8 byte string, how to calculate how many codepoints are in it?
Since it is a variable-length format, the encoding length is implied in the data. Therefore, it is not possible to directly infer how many codepoints correspond to the length of the utf8 byte string. You can only iterate through the entire byte string to calculate.
Observing the encoding format, a clever way is to just ignore continuation bytes when counting.
The characteristic of a continuation byte is that the high-order bits are 10, and the high-order bits of a non-continuation byte are definitely not 10.
In the following code, c & 0xc0 is checking whether it is a continuation byte:
size_t CountCodes(std::string_view s) {
size_t k = 0;
for (auto c : s) {
// 0xc0 = 11000000, 0x80 = 10000000
if ((c & 0xc0) != 0x80) k++;
}
return k;
}
Encoding Method ¶
Consider how to encode a single codepoint into 1~4 utf8 bytes. Pay attention to the table above:
When
code <= 0x7f, the codepoint is in the form of0xxxxxxx, and the encoding result is itself.if (code <= 0x7f) { // 0xxxxxxx s[0] = code & 0xff; return 1; }When
code <= 0x7ff, the codepoint is in the form of0xxx xxyyyyyy, when encoding:- The first 5 bits
xxx xxare given to the lower 5 bits of the first byte, and then ORed with110, indicating that there are a total of 2 bytes. - The last 6 bits
yyyyyyare given to the lower 6 bits of the second byte, and then ORed with10, which belongs to a continuation byte.
if (code <= 0x7ff) { // 0xxx xxyyyyyy s[0] = 0xc0 | (code >> 6); // 110xxxxx s[1] = 0x80 | (code & 0x3f); // 10yyyyyy return 2; }- The first 5 bits
The remaining cases of 3 bytes and 4 bytes are the same as the above analysis, and will not be repeated.
In C++, u32string can be used to represent a unicode codepoint sequence, and the type of each unit is char32_t. Finally, the overall encoding method:
codepoint encoding to utf8 method - C++
static size_t inline code_to_utf8(char32_t code, unsigned char* s) {
if (code <= 0x7f) { // 0xxxxxxx
s[0] = code & 0xff;
return 1;
}
if (code <= 0x7ff) { // 0xxx xxyyyyyy
s[0] = 0xc0 | (code >> 6); // 110xxxxx
s[1] = 0x80 | (code & 0x3f); // 10yyyyyy
return 2;
}
if (code <= 0xffff) { // xxxxyyyy yyzzzzzz
s[0] = 0xe0 | (code >> 12); // 1110xxxx
s[1] = 0x80 | ((code >> 6) & 0x3f); // 10yyyyyy
s[2] = 0x80 | (code & 0x3f); // 10zzzzzz
return 3;
}
if (code <= 0x10ffff) { // 000xxxyy yyyyzzzz zzwwwwww
s[0] = 0xf0 | (code >> 18); // 11110xxx
s[1] = 0x80 | ((code >> 12) & 0x3f); // 10yyyyyy
s[2] = 0x80 | ((code >> 6) & 0x3f); // 10zzzzzz
s[3] = 0x80 | (code & 0x3f); // 10wwwwww
return 4;
}
return 0;
}
size_t Encode(std::u32string_view p, std::string& s) {
size_t j = 0;
for (auto code : p) {
auto d = code_to_utf8(code, reinterpret_cast<unsigned char*>(&s.at(j)));
if (!d) return 0;
j += d;
}
return j;
}
Decoding Method ¶
Is the decoding logic just as simple? Not really.
Not all byte strings can be decoded into a valid codepoint sequence. There are two reasons:
- The given byte string may have format errors.
- For some security reasons, even if it conforms to the utf8 encoding format, it must also follow the shortest encoding principle.
Encoding a codepoint to utf8 has a unique result. But conversely, when decoding a utf8 byte string to a codepoint, we want to prohibit some overlong situations.
For example, U+007F can be encoded as follows, where red is the utf8 high-bit identifier and blue is the data part:
0x7f = 011111110xc1 0xbf = 11000001 101111110xe0 0x81 0xbf = 11100000 10000001 101111110xf0 0x80 0x81 0xbf = 11110000 10000000 10000001 10111111
Although these byte strings all conform to the encoding rules, only the shortest 0x7f is a valid encoding.
In this example, looking at the two-byte case, in fact, 0xc1=11000001 can never be the first byte in utf8 because it will definitely lead to an overlong encoding problem: Any 2-byte encoding result 11000001 10xxxxxx must correspond to an equivalent, shorter one-byte encoding result 01xxxxxx.
For a 2-byte length encoding result, the first byte must be at least 0xc2=11000010, because the encoding result at this time is in the form of 11000010 10xxxxxx, the data part occupies 8 bits and cannot be encoded as a utf8 byte string of length 1.
Therefore, the first byte of the encoding result can be 00..7f, but not 80..c1 (hexadecimal format, both ends inclusive). There are more than just this “hole” of this kind. unicode.org has a table that organizes all legal encoding situations:
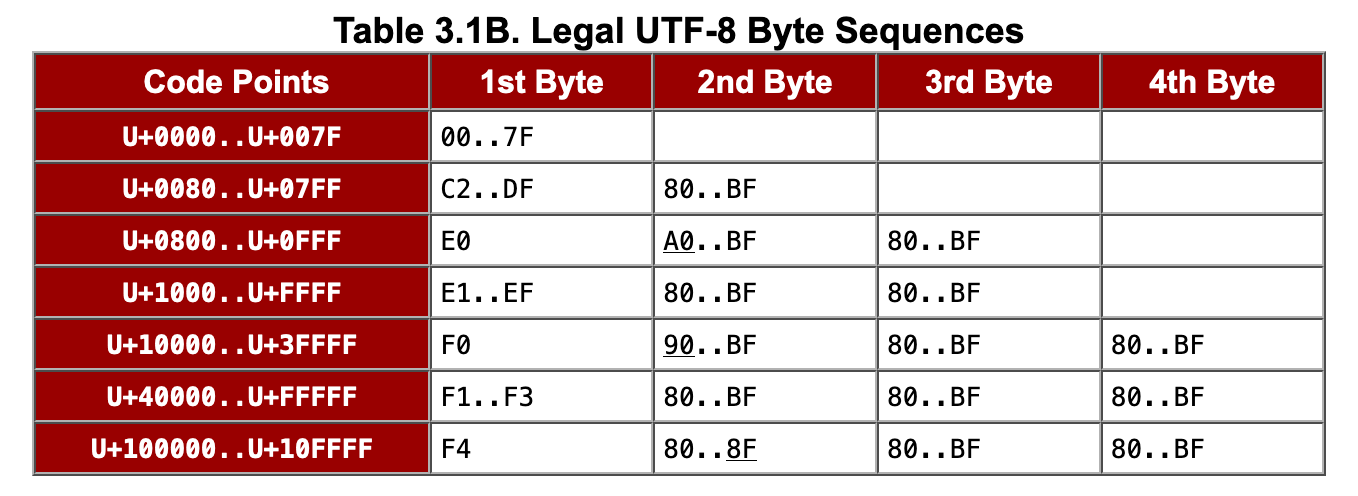
Next, according to this table, design a utf8 decoding function, which will adopt the idea of a state machine.
Define a status code state during the parsing process:
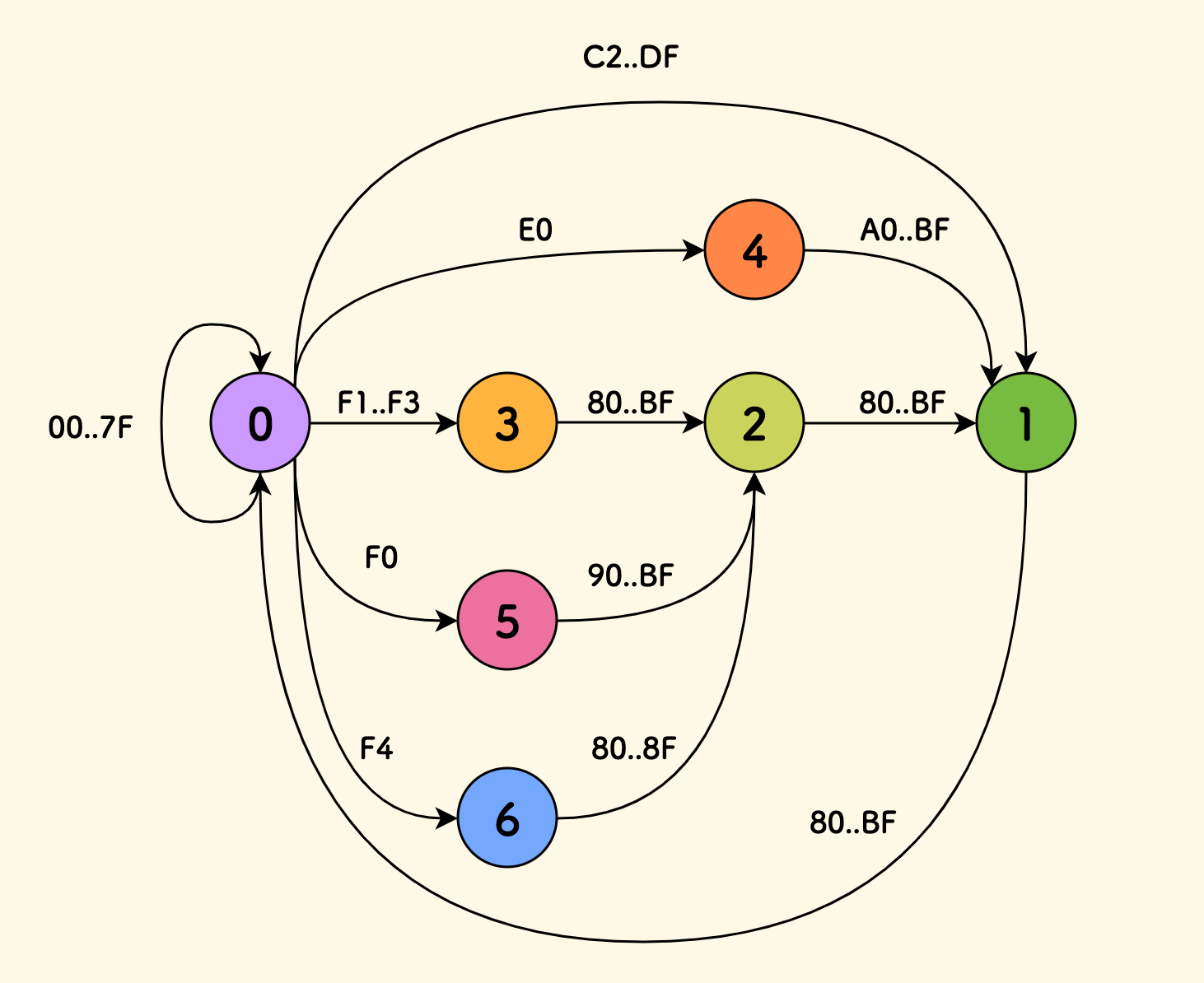
state 0indicates successful parsing, and also serves as the initial state (for parsing the next codepoint)state 8indicates a parsing error (overlong encoding, format error)state 1indicates that it is still waiting for 180..BFcontinuation byte input before parsing can be successfulstate 2indicates that it is still waiting for 280..BFcontinuation byte inputs before parsing can be successfulstate 3indicates that it is still waiting for 380..BFcontinuation byte inputs before parsing can be successfulstate 4indicates that the head byte isE0, waiting forA0..BFcontinuation byte input, and will enterstate 1next timestate 5indicates that the head byte isF0, waiting for90..BFcontinuation byte input, and will enterstate 2next timestate 6indicates that the head byte isF4, waiting for80..8Fcontinuation byte input, and will enterstate 2next time
You can combine the state markers in the following figure to understand the design of these states. Among them, tables with the same state have the same background color.

The state transition diagram is as follows (where error state 8 is not drawn, all unexpected inputs will jump to state 8):
In this way, the decode function becomes very easy. You can use switch-case to write the jump function.
utf8 decoder state transition function - C++
static uint32_t inline
decode_next_naive(uint32_t* state, char32_t* code, unsigned char byte) {
switch (*state) {
case 0:
if (byte <= 0x7f) { *code = byte; }
else if (byte < 0xc2) { *state = 8; }
else if (byte <= 0xdf) { *state = 1; *code = byte & 0x1f; }
else if (byte == 0xe0) { *state = 4; *code = 0xe0 & 0xf; }
else if (byte <= 0xef) { *state = 2; *code = byte & 0xf; }
else if (byte == 0xf0) { *state = 5; *code = 0xf0 & 0x7; }
else if (byte <= 0xf3) { *state = 3; *code = byte & 0x7; }
else if (byte == 0xf4) { *state = 6; *code = 0xf4 & 0x7; }
else { *state = 8; }
break;
case 1:
case 2:
case 3:
if (byte >= 0x80 && byte <= 0xbf)
{ *state -= 1; *code = (*code << 6) | (byte & 0x3f); }
else { *state = 8; }
break;
case 4:
if (byte >= 0xa0 && byte <= 0xbf)
{ *state = 1; *code = (*code << 6) | (byte & 0x3f); }
else { *state = 8; }
break;
case 5:
if (byte >= 0x90 && byte <= 0xbf)
{ *state = 2; *code = (*code << 6) | (byte & 0x3f); }
else { *state = 8; }
break;
case 6:
if (byte >= 0x80 && byte <= 0x8f)
{ *state = 2; *code = (*code << 6) | (byte & 0x3f); }
else { *state = 8; }
break;
}
return *state;
}
Implementation of the decoding function:
utf8 decoder implementation - C++
size_t DecodeNaive(std::string_view s, std::u32string& p) {
uint32_t state = 0;
char32_t code = 0;
size_t k = 0;
for (auto c : s) {
decode_next_naive(&state, &code, c);
if (state == 8) return 0; // early fail.
if (state == 0) p[k++] = code;
}
if (state != 0) return 0;
return k;
}
All complete code implementations can be found at: https://github.com/hit9/simple-utf8-cpp.
Finally, let’s quote 《The Pattern on the Stone》 again to sigh:
One reason finite state machines are so useful is that they recognize sequences.
(End)
Please note that this post is an AI-automatically chinese-to-english translated version of my original blog post: http://writings.sh/post/utf8.
Related Readings:
- Implementing a Simple Regular Expression Engine
- Automaton for Validating Floating Point Strings (DFA & NFA)
Original Link: https://writings.sh/post/en/utf8