问题描述 ¶
前两天 leetcode 的每日一题:
一个整数矩阵 $g$ 中,从左上角 $(0,0)$ 出发,每次可以 向右 或者 向下 移动。
如果当前在格子 $(i,j)$ 上,那么下次移动可以到达的格子是:
- 向右移动 到 $(i,k)$ 处,其中 $j < k \leq g[i][j] + j$ 。
- 向下移动 到 $(k,j)$ 处,其中 $i < k \leq g[i][j] + i$ 。
求最少经过几次移动可以到达右下角。
-- leetcode 2617. 网格图中最少访问的格子数
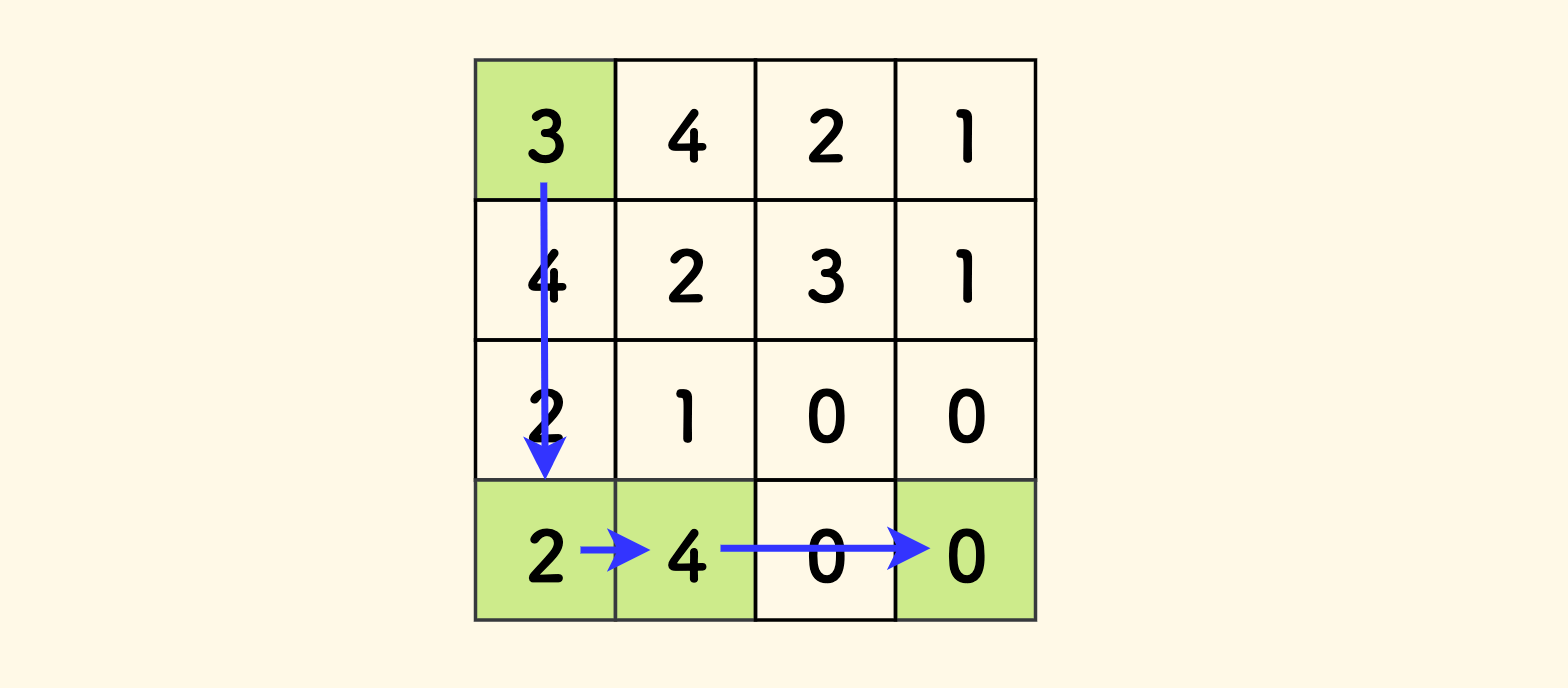
例如,下面的矩阵的最少移动次数是 $4$,其路径是沿着绿色的格子移动。
题意分析 ¶
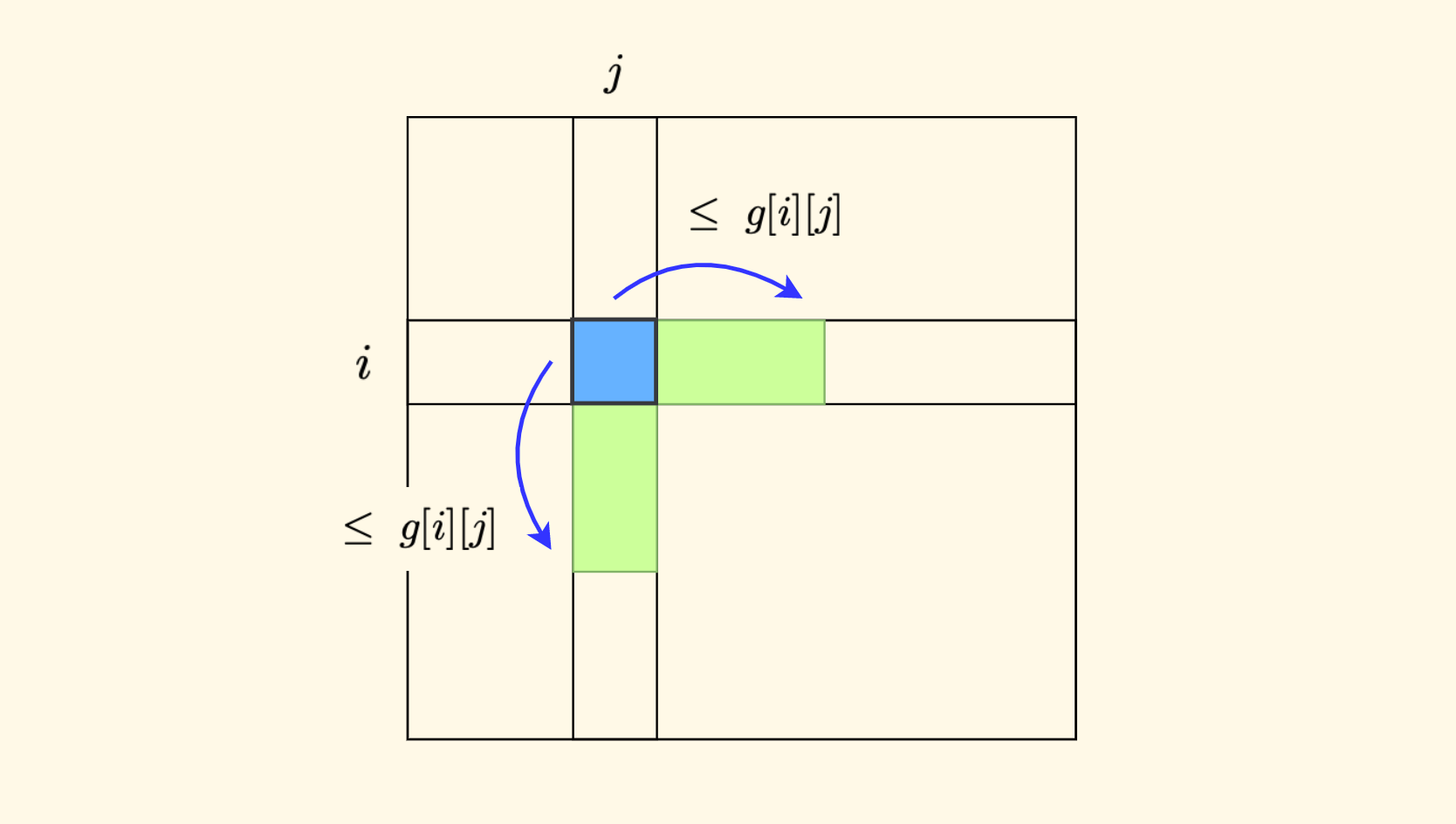
题目中对于每次移动时可跳达的范围有约束,和当前方格的值有关,简单来说:
- 可以向右跳一定距离。
- 可以向下跳一定距离。
- 这个距离上界限制为当前方格的值 $g[i][j]$。
下图是一个形象的展示,当前的位置是 $(i,j)$,绿色的部分是可以跳到的区域:
初版实现 ¶
看上去是一个动态规划问题,所以尝试把问题拆解为子问题。
子问题是,求解从矩阵中的一个方格 $(i,j)$ 走到右下角的最少移动次数 $f(i,j)$。
原问题的答案就是 $f(0,0)$。
下图中,当前所在位置是 $C$,从这里可以跳入同一列的位置 $A$ 和 同一行的位置 $B$。
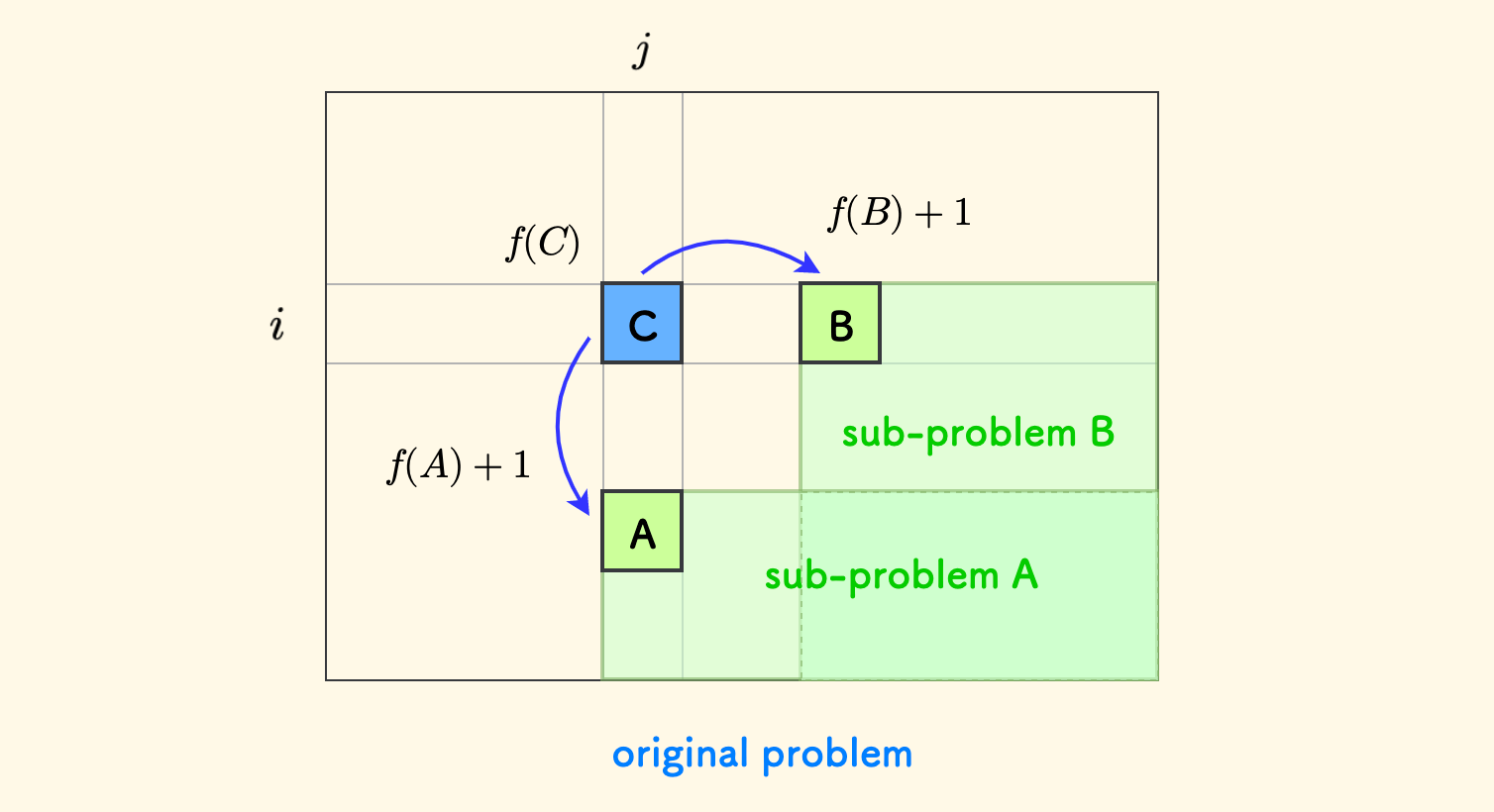
假设已经求解出来子问题 $A$ 和 $B$ 的答案,那么 $C$ 处的答案肯定是所有 $f(A)+1$ 和 $f(B)+1$ 的最小值。 因为要想到达右下角,必须经过所有的 $A$ 和 $B$ 这样的区域中的至少一个来到达,当然是挑一个移动次数最小的了。
也就是说,先解决右下方的子问题,就可以推导出来左上方的更大的问题 $C$ 的答案。
那么,动态规划的转移方向就确定了,即从右下方倒序地向左上方进行,直到最终解决原问题 $f(0,0)$。 究其本质是,我们定义的子问题结构,包含着更小的子问题,而它又可以从这些更小的子问题推导出来,也就满足了动态规划的场景。
这样,容易得到转移方程如下:
\[f(i,j)\ =\ \min_{0<k\leq g[i][j]} \left\{ f\left( i,j+k\right) ,\ f(i+k,j)\right\} + 1\]因为是按最小值转移,所以最开始 $f(i,j)$ 都初始化为无穷大,注意右下角的 $f$ 值要初始化为 $1$。
那么,如何求解可跳达区域的最小 dp 值呢?最简单的办法是遍历,得到三层循环的初版代码:
网格图中最少访问的格子数 - 初版 - C++ 实现
const int inf = 0x3f3f3f3f;
class Solution {
public:
int minimumVisitedCells(vector<vector<int>>& g) {
int m = g.size(), n = g[0].size();
// f[i][j] 是到达终点的最少步数
int f[m][n];
memset(f, 0x3f, sizeof f);
f[m - 1][n - 1] = 1;
for (int i = m - 1; i >= 0; i--) {
for (int j = n - 1; j >= 0; j--) {
if (i == m - 1 && j == n - 1) continue;
int v = inf;
for (int k = i + 1; k <= min(i + g[i][j], m - 1); k++)
v = min(v, f[k][j]);
for (int k = j + 1; k <= min(j + g[i][j], n - 1); k++)
v = min(v, f[i][k]);
f[i][j] = min(f[i][j], v + 1);
}
}
if (f[0][0] >= inf) return -1;
return f[0][0];
}
};
这样做的正确性是没问题的,但是提交后会显示超时。
转移优化 ¶
你可能会注意到,每次都要 for 循环跑一次最小值,是很浪费的。
所以这里,可以尝试在 dp 转移上进行优化。
目前转移的方向如下图所示,转移的来源区间是两个绿色的长条:
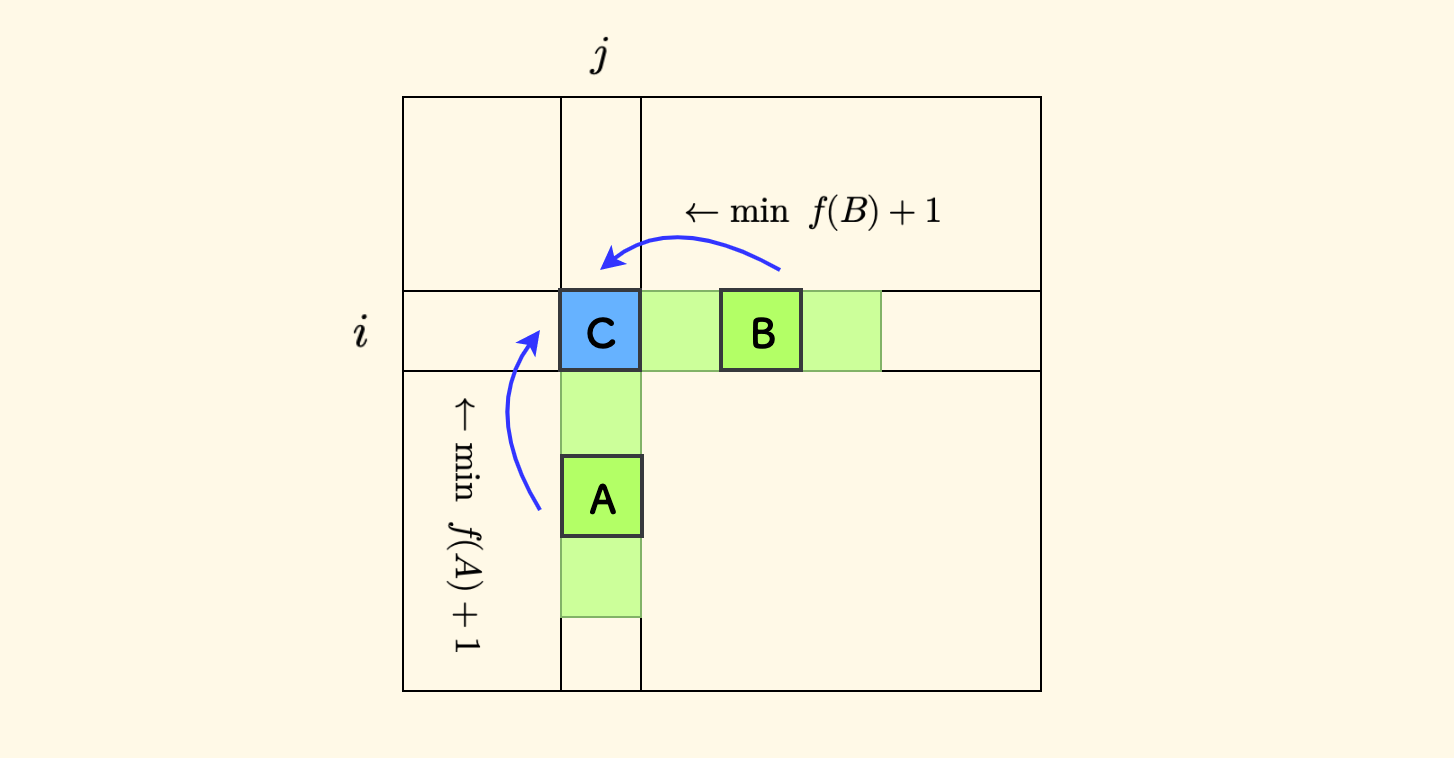
目前的做法是,从两个来源区间上遍历找最小值,需要 $O(n)$ 的时间复杂度,可以优化吗?
另一方面,当 $f(i,j)$ 计算完毕后,又会被利用来推导其左上方的答案。
也就是说,这实际上是一种 带修区间求最值的问题。
你可以把上图中的矩阵,想象成每个方格填入答案 $f(i,j)$ 的过程,填表过程自 右下 到 左上 进行。 这里「带修」的意思是,一边查询最小值、一边修改区间内容。更确切地,这里的修改是一种「单点修改」,即只修改区间中仅一项的值。
擅长这个工作的数据结构,就是 树状数组 了,它进行「单点修改」和「区间最值查询」的时间复杂度都是 $O(log^2{n})$ [1]。
原来的转移方式下,求解最小值是 $O(n)$,单点修改是 $O(1)$,而树状数组可以把二者都做到 $\log^2{n}$,相当于降低了时间复杂度的瓶颈。
用于维护区间最值的树状数组并不流行,大部分情况下线段树要更常见。
代码如下:
网格图中最少访问的格子数 - 维护区间最小值的树状数组 - C++ 实现
const int inf = 0x3f3f3f3f;
// 单点修改、查询区间最小值的树状数组
class BIT {
private:
int n;
vector<int> c; // c[x] 维护区间 [x-lowbit(x)+1,x] 上的最小值
vector<int> a; // 原数组
public:
explicit BIT(int n)
: n(n), c(vector<int>(n + 1, inf)), a(vector<int>(n + 1, inf)) {}
int lowbit(int x) { return x & -x; }
int ask(int l, int r) {
int ans = inf;
while (r >= l) {
for (; r - lowbit(r) + 1 > l; r -= lowbit(r))
ans = min(c[r], ans);
ans = min(a[r--], ans);
}
return ans;
}
void update(int x, int v) {
a[x] = v;
for (; x <= n; x += lowbit(x)) c[x] = min(c[x], v);
}
};
还有一个问题是,目前的 $f$ 是一个二维数组,但是树状数组维护的是一维数组。
我们目前的填表方式是,先倒着填写最后一行、然后向上开始填倒数第二行、如此进行。可以回忆一下代码的最外两层循环:
for (int i = m - 1; i >= 0; i--) {
for (int j = n - 1; j >= 0; j--) {
// f[i][j] = ...
}
}
下图描述了填入 $f$ 值的过程,是 自右向左、自下而上 进行的:
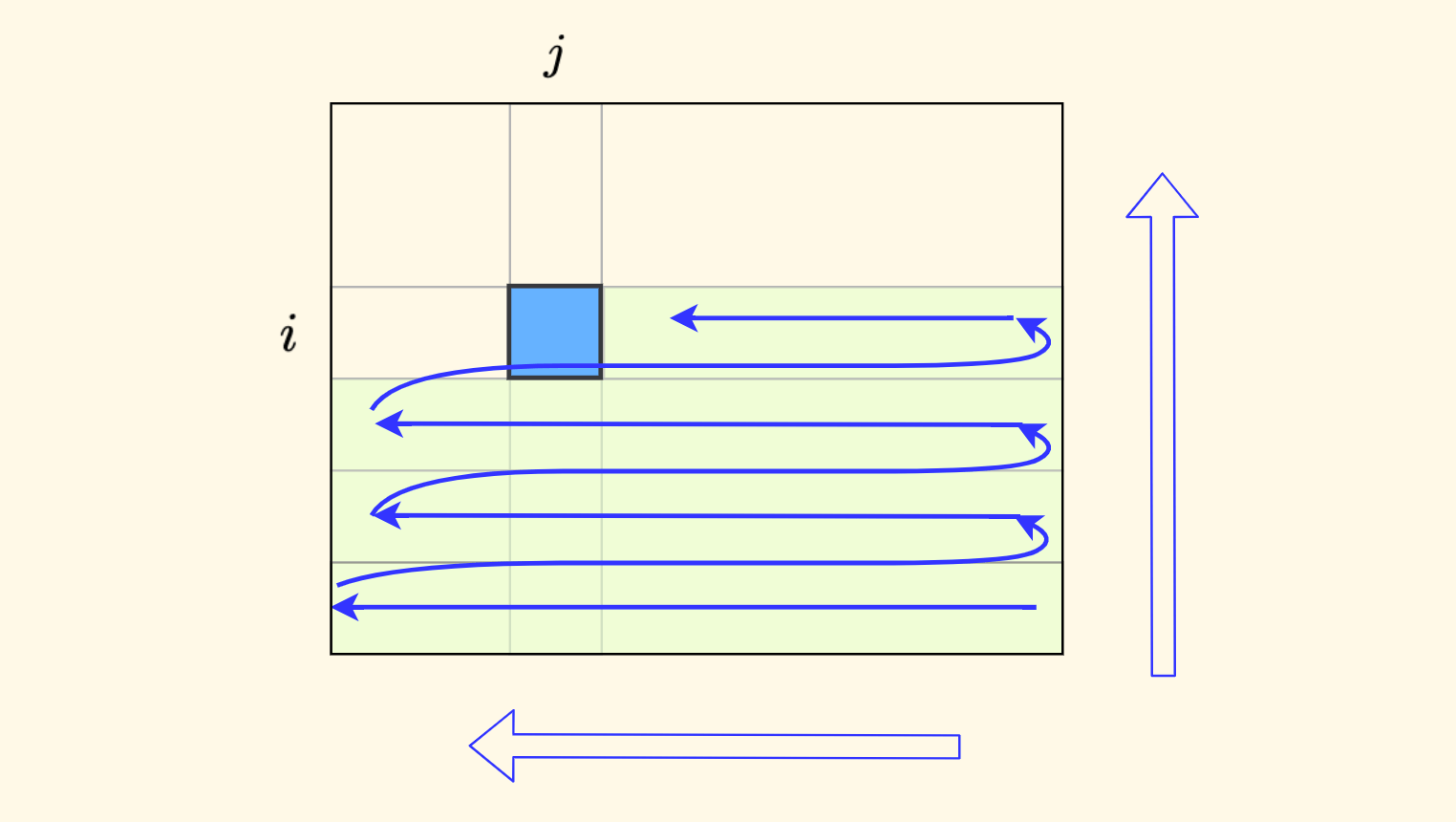
使用树状数组的时候,一定要明确其维护的原数组的含义。那么,现在这个原数组(一维数组)该如何设计呢?
如果沿着填表的方向(实际是逆方向),设置一个连续内存的原数组 a 的话(存储的就是 $f$ 的值),然后用树状数组来维护这个数组 a。那么右方的绿色条会是 a 上面的一段连续的区间。
但是,问题在于,下方的绿色条就不是 a 的一个区间了,因为它在内存上不连续。
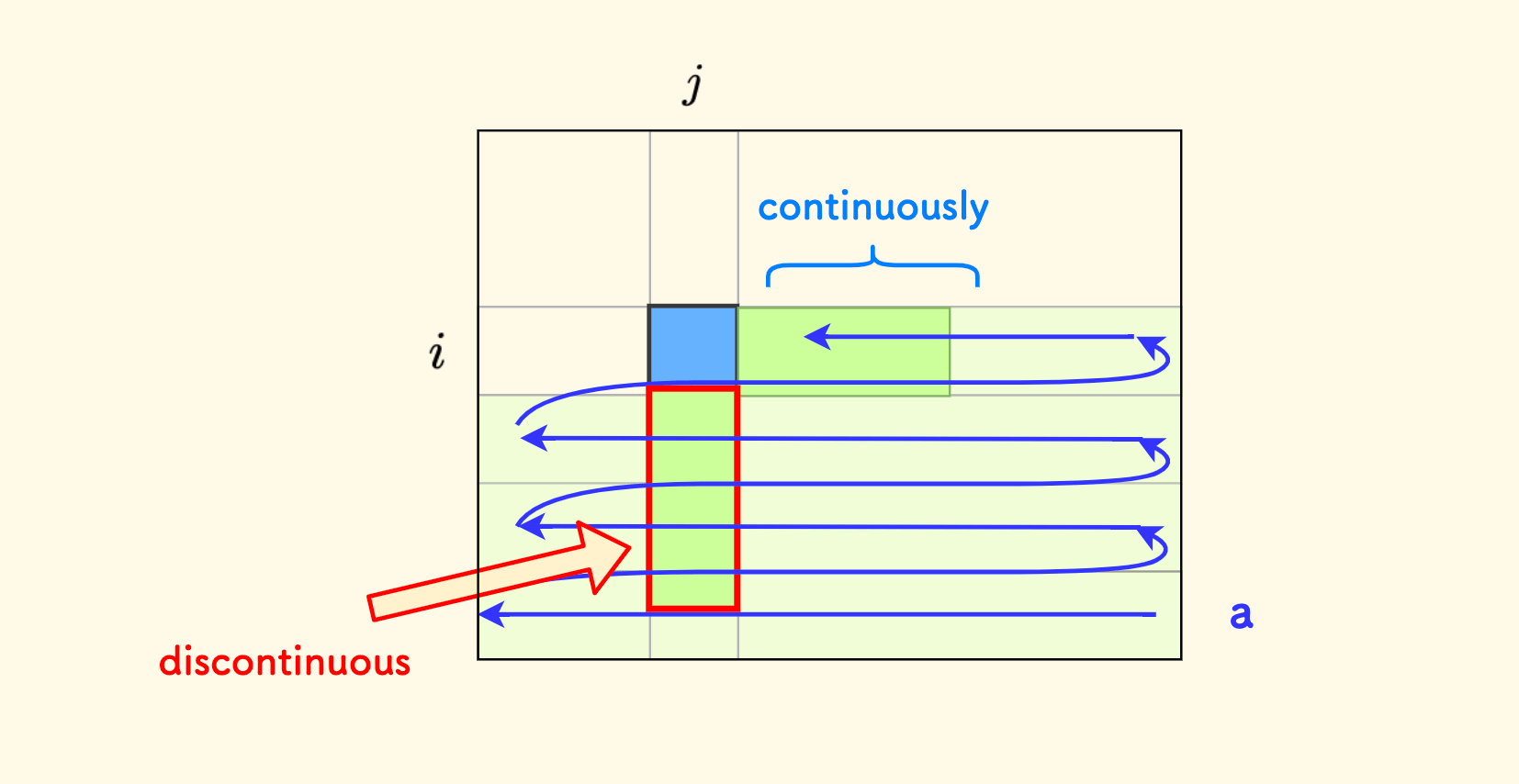
同样的道理,如果我们的沿着「列连续」的思路建立原数组 a 的话,那么也会导致右方的绿色条无法形成一个连续的区间。
所以,干脆使用两个原数组,也就是采用两个树状数组 b1 和 b2。
b1维护的原数组,按 先向左、再向上 的方向形成。按列形成连续区间。b2维护的原数组,按 先向上、再向左 的方向形成。按行形成连续区间。
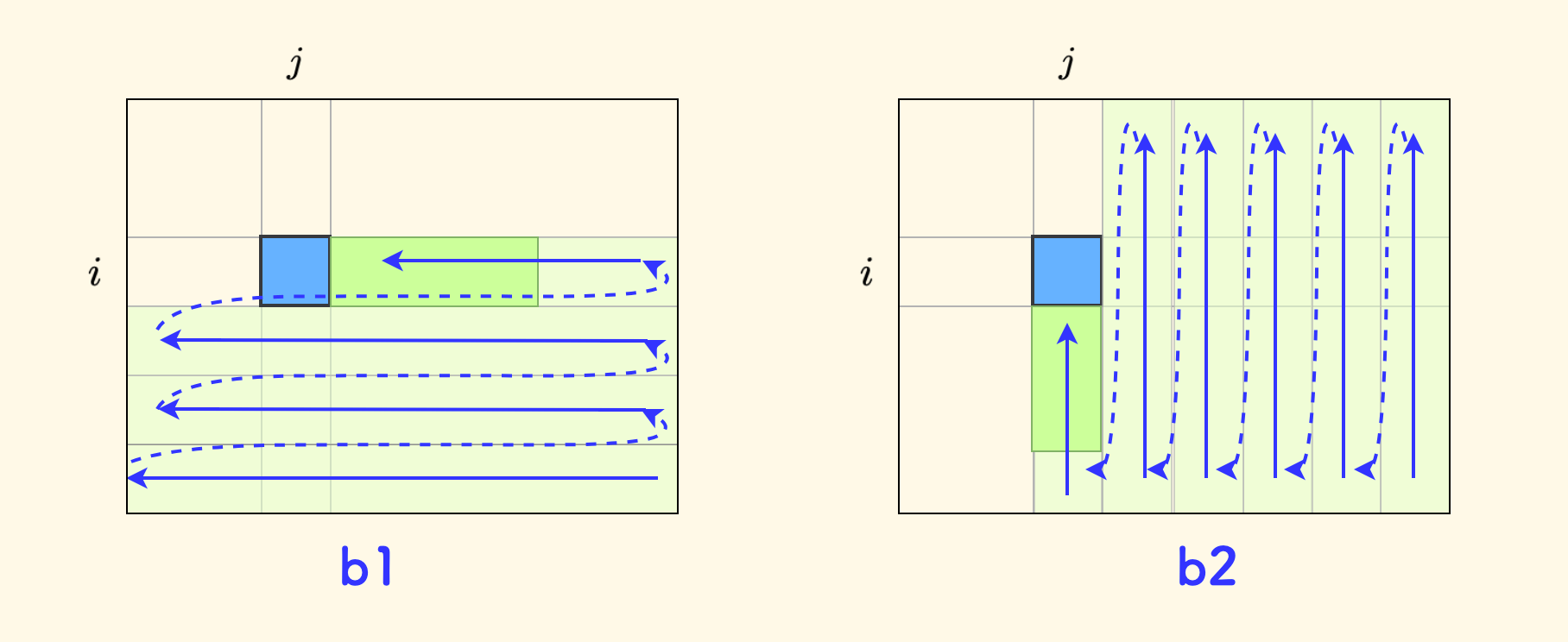
这样,转移只要这样进行:
- 来自右方的转移,利用
b1 - 来自下方的转移,利用
b2
但是,还剩最后一个问题要解决:因为树状数组维护的是一维数组,所以需要把 $(i,j)$ 这种二维坐标转换到一维下标上去。
在两种形式下,映射的方式是不同的。但大体都是一个思路。
比如说,我们要把 $(i,j)$ 映射一下,假设棋盘大小是 $m \times n$ 的,一维下标可以按「进制」的思维设计映射:
// 方式1, 按把 i,j 看成 n 进制下的 「 ij 」
i * n + j
// 方式2, 按把 i,j 看成 m 进制下的 「 ji 」
j * m + i
第一种方式适合 b1,第二种方式适合 b2。 另外,必须注意树状数组的下标不可为 0,所以映射的时候再加一。
代码实现上,先做两个下标映射函数:
// 按列连续映射, 适合 b1
auto q1 = [&](int i, int j) { return i * n + j + 1; };
// 按行连续映射, 适合 b2
auto q2 = [&](int i, int j) { return j * m + i + 1; };
然后定义两个树状数组:
// 树状数组维护 f 的区间最小值, 区间下标 [1..m*n]
// 初始化原数组每一项是 inf
BIT b1(m * n), b2(m * n);
// 初始化右下角 dp 值是 1
b1.update(q1(m - 1, n - 1), 1);
b2.update(q2(m - 1, n - 1), 1);
优化转移部分:
for (int i = m - 1; i >= 0; i--) {
for (int j = n - 1; j >= 0; j--) {
if (i == m - 1 && j == n - 1) continue;
int v = inf;
// 向右走, 转移来源的区间:[i,j+1] ~ [i, j+g[i][j]]
if (j != n - 1 && g[i][j] > 0)
// 转换到一维下标,构造来源区间,查询最小值
v = min(v, b1.ask( q1(i, j + 1),
q1(i, min(j + g[i][j], n - 1)) ));
// 向下走, 转移来源的区间:[i+1,j] ~ [i+g[i][j], j]
if (i != m - 1 && g[i][j] > 0)
// 转换到一维下标,构造来源区间,查询最小值
v = min(v, b2.ask( q2(i + 1, j),
q2(min(i + g[i][j], m - 1), j) ));
// 更新树状数组
if (v != inf) {
b1.update(q1(i, j), v + 1);
b2.update(q2(i, j), v + 1);
}
}
}
DP 的整体逻辑没有变化,只是用树状数组优化了转移时间。
在新版的实现中,虽然仍然是动态规划,但是 dp 数组 $f$ 都没有存在的必要了,只要 b1 和 b2 两个树状数组就可以了。
最终的答案,即原数组区间 [1,1] 上的最小值:
int ans = b1.ask(1, 1); // b2 也可
if (ans >= inf) return -1;
return ans;
总的来说,这是一种数据结构优化 DP 转移的解法,有趣之处在于这个「双树状数组」和 「下标映射」。
(完)
本文原始链接地址: https://writings.sh/post/minimum-number-of-visited-cells-in-a-grid
