本文是 树上背包(也叫树形背包)的学习笔记。
前置知识:基础的几种背包模型。
模板问题 ¶
树上背包是背包问题 和 树形 DP 的结合,描述如下:
有 $n$ 个物品和一个容量为 $m$ 的背包。第 $i$ 个物品的体积是 $v_i$、价值是 $w_i$,依赖的父节点物品是 $p_i$。 物品之间具有依赖关系,且依赖关系组成一棵树。如果选择一个物品,则必须选择它的父节点。 选择一些物品放入背包,每个物品只可以使用一次,求可以获得的最大价值。
-- acwing 10.有依赖的背包问题
划分阶段
和传统的 01 背包一样,以物品(也就是节点)来划分阶段。
我们 把原问题按树的结构拆分成子问题,一开始只考虑仅有一个物品的子问题、然后加入新的物品和依赖关系形成一个新的子问题。 随着所考虑的物品的加入,逐步扩大问题规模,直到解决原问题。
定义 $f_x(j)$ 为以节点 $x$ 为根的子树中选取总体积为 $j$ 的物品获取到的最大价值。这里第一个维度 $x$ 就是 DP 的阶段,第二个维度是状态。
转移方向
但注意的是,要先解决更下层的子树、从下向上转移。
比如说,现在考虑放入物品 $x$,它有一个子节点 $y$ 依赖它,那么:
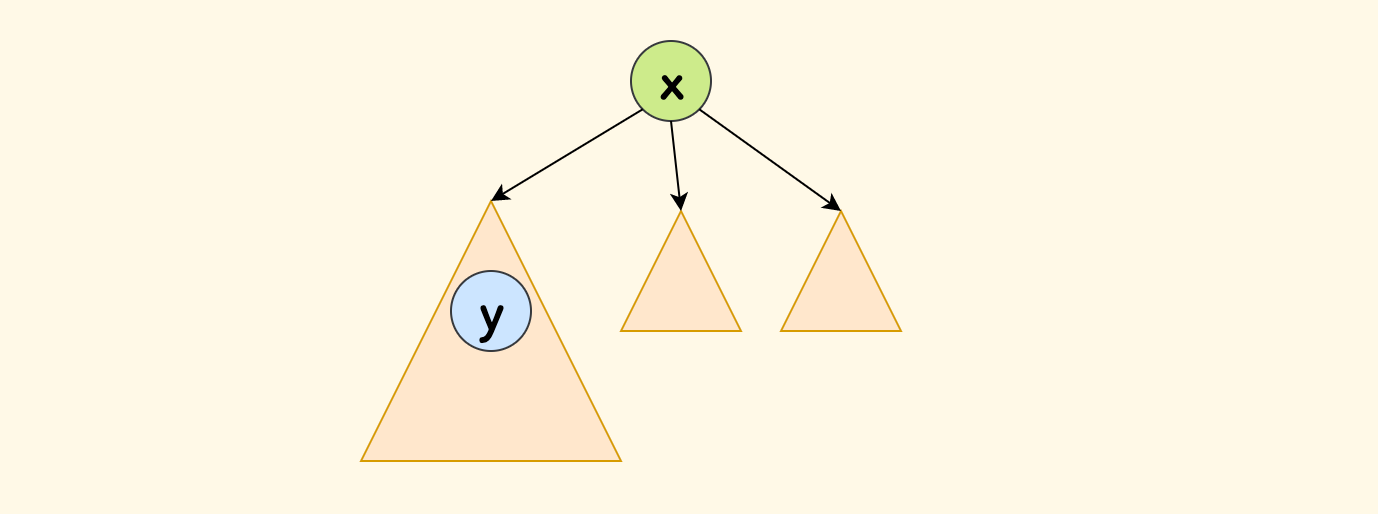
- 先解决完只考虑 $y$ 中的物品形成的子问题。
现在加入物品 $x$ 形成一个新的子问题,同时新增了 $y$ 对 $x$ 的依赖关系。
此时,把 $x$ 放入背包后, 由于 $y$ 依赖 $x$,所以选择了 $x$ 的基础之上、可以进一步选择 $y$,当然也可以不选。
也就是说,父节点问题可以利用子树的结果,而反过来则不行,这就是为什么要先处理下层节点的原因。
转移方程
父节点可以利用子树的结果,那么就可以用递归来解决,确切的说是简单的树形 DP – 先计算完子树的答案,然后向父节点转移。
定义函数 dfs(x) 来求解 $f_x(j)$,现在的代码框架如下:
void dfs(int x) {
// TODO: 初始化 f[x][j]
for (auto y : edges[x]) {
dfs(y);
// TODO: 子树 y 向 x 转移
}
}
先求解子树 $y$,也就是要先递归进去,然后在回溯过程中(也就是 dfs 的后序)来计算 $f_y$ 向 $f_x$ 的转移。
现在考虑转移方程。
首先,必须选择 $x$,那么对任何一个不超过背包大小 $m$ 的体积 $j$ 来说,都 至少获取到 $x$ 自身的价值,即先初始化 $f_x(j) = w_x$。
然后,在选择 $x$ 的基础之上,可以进一步选择任意一个子节点 $y$。
那么,枚举每一个体积 $j$,考虑从 $f_y$ 向 $f_x(j)$ 的转移。
进一步,假设分配给子树 $y$ 的体积是 $k$,那么其他部分(子树 $x$ 内的剩余部分)分配的体积是 $j-k$,此时的可得到的价值是 $f_y(k)+f_x(j-k)$。
下图中,蓝色圈内是 $y$ 分配到的体积 $k$、红色圈内是 $x$ 内剩余的分配体积 $j-k$,每一个圈都代表一个已经计算完毕的子问题。
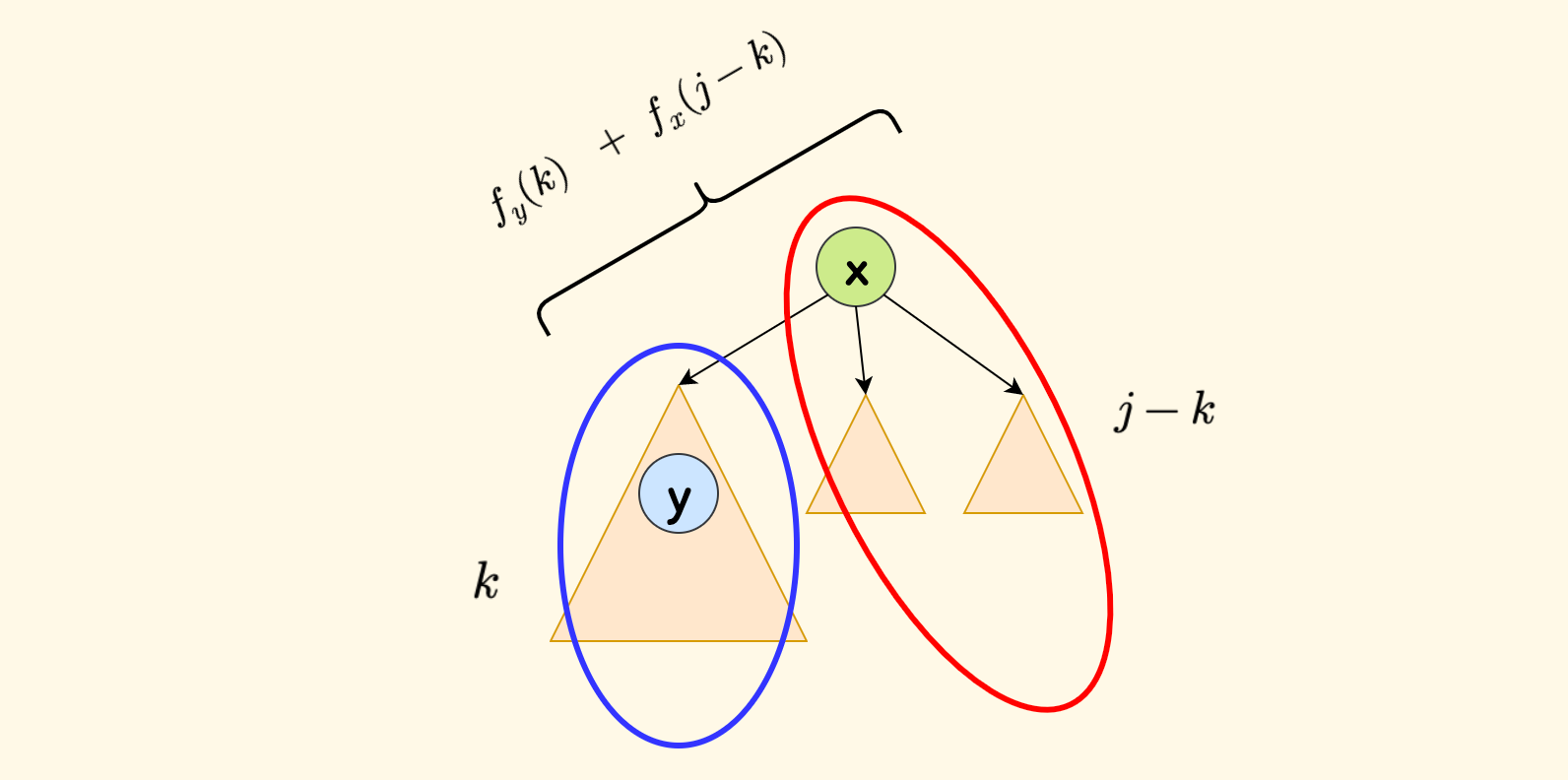
只需要枚举每一个 $k$,来不断和 $f_x(j)$ 取最大值即可。
但是,需要注意的是,因为 考虑选择一个子节点 $y$ 的前提是、必须选择其父节点 $x$ ,所以 $j$ 至少为 $v_x$, 同样的道理,分配给子树的体积 $k$ 也不应该超过 $j-v_x$。
完整的转移方程如下:
\[f_{x}(j)\leftarrow \max_{v_{x}\leq j\leq m, \ 0\leq k\leq j-v_{x}} \{ f_{x}(j),\ f_{y}(k)+f_{x}(j-k)\}\]模板代码
至此,可以完整实现 dfs 函数:
void dfs(int x) {
// 至少选择 x
for (int j = v[x]; j <= m; j++) f[x][j] = w[x];
for (auto y : edges[x]) {
dfs(y);
// 枚举 x 的分配体积 j, 至少为 v[x]
for (int j = m; j >= v[x]; j--)
// 枚举子树 y 的分配体积 k, 不超过 j-v[x]
for (int k = 0; k <= j - v[x]; k++)
f[x][j] = max(f[x][j], f[y][k] + f[x][j - k]);
}
}
不过,和 01 背包滚动数组的实现类似,这里有一个转移方向和迭代方向的问题需要特别留意。 因为存在 $f_x(j-k)$ 向 $f_x(j)$ 的转移,这是从一个更小的状态值 $j-k$ 向更大的 $j$ 去转移,那么就要考虑迭代方向的问题。 因为每个物品只允许使用一次,所以必须倒序循环($j$ 从大到小,和转移方向逆序)。
原因在于,比如说三个状态值 $j_a < j_b < j_c$,如果正向循环的话,会导致 $f_x(j_a)$ 会影响 $f_x(j_b)$ 的结果,$f_x(j_b)$ 会影响 $f_x(j_c)$, 也就是更小的 $j$ 会对更大的 $j$ 的 dp 值形成级联影响,这个所谓的「影响」就是子树向父节点的转移过程、也就是会利用多次子树 $y$ 的结果,违背物品只利用一次的限制。
在使用滚动数组的背包问题中,转移和迭代的方向关系是至关重要的,第一次接触难免会一头雾水,这篇文章写的更详细一些。
最后,只需要从根节点发起调用即可,最终答案是 $f_{root}(m)$ :
int solve() {
dfs(root);
return f[root][m];
}
一些感想
- 虽然最终的代码很简洁,但是这个问题还是有难度的,而且在 边界处理、迭代方向 上都有坑点。
- 既然是先处理树的最下层,如果不用
dfs来做,也可以用拓扑序 [2] 来做,然后逆序 DP。 - 额外一个感悟,树形背包看上去有一点「换根 DP」[3] 的感觉,虽然不是一类问题,但是 DP 转移上有点相似 ~
一些题目 ¶
选课
现在有 $n$ 门课程,要选修其中 $m$ 门。每门课有个学分,每门课有一门或没有直接先修课,要学习一门课程必须先学习完它的先修课。 问可以获得最多的学分。
-- 洛谷 P2014. 选课
每个课的先修课最多有一门(也可以没有先修课),那么形成的是一个森林结构。
只需新增一个虚拟根节点,比如 $0$ 号节点,其学分为 $0$,而且必选,那么问题就成为了树上背包问题。 但是要特别注意,此时要选修的课是 $m+1$ 门了。
剩下的事情,代入前面所说的模型即可。
选课 - C++ 代码
vector<int> edges[N]; // 父节点到子节点, 0 号是虚拟节点
int w[N]; // 价值数组, 即学分, w[0] = 0
// f[x][j] 表示只考虑子树 x 的子问题时选取总体积 j 的最大价值
int f[N][M];
void dfs(int x) {
f[x][0] = 0;
for (int j = 1; j <= m; j++) f[x][j] = w[x];
for (auto y : edges[x]) {
dfs(y);
for (int j = m; j >= 1; j--)
for (int k = 0; k <= j - 1; k++)
f[x][j] = max(f[x][j], f[y][k] + f[x][j - k]);
}
}
int solve() {
m++;
w[0] = 0;
dfs(0);
return f[0][m];
}
重建道路
一颗以 $1$ 号节点为根的、节点数目为 $n$ 的有向树,最少断几个边可以分离出一颗节点数目恰好为 $p$ 的子树?
-- 洛谷. P1272 重建道路
这可能并不能严格地算一个树上背包问题、但是它的解决思路和树上背包非常相似。
定义 $f_x(j)$ 为子树 $x$ 保留大小为 $j$ 的子树, 且包含 $x$ 的最少需要删边的数目。
首先,如果只要保留 $1$ 个节点,即只保留 $x$ 本身的话,要删的就是它的所有出边。
f[x][1] = edges[x].size(); // 只保留 x 的时候
另一种更普通的情况是,也保留 $x$ 的子树中的一些节点。那么和树上背包问题的思路一样,枚举一下子树的分配。
考虑每个可能的保留节点数 $j$, 对于 $x$ 的一个子节点 $y$,假设子树 $y$ 分配了 $k$ 个节点,那么 $x$ 的剩余部分就分配了 $j-k$ 个节点。
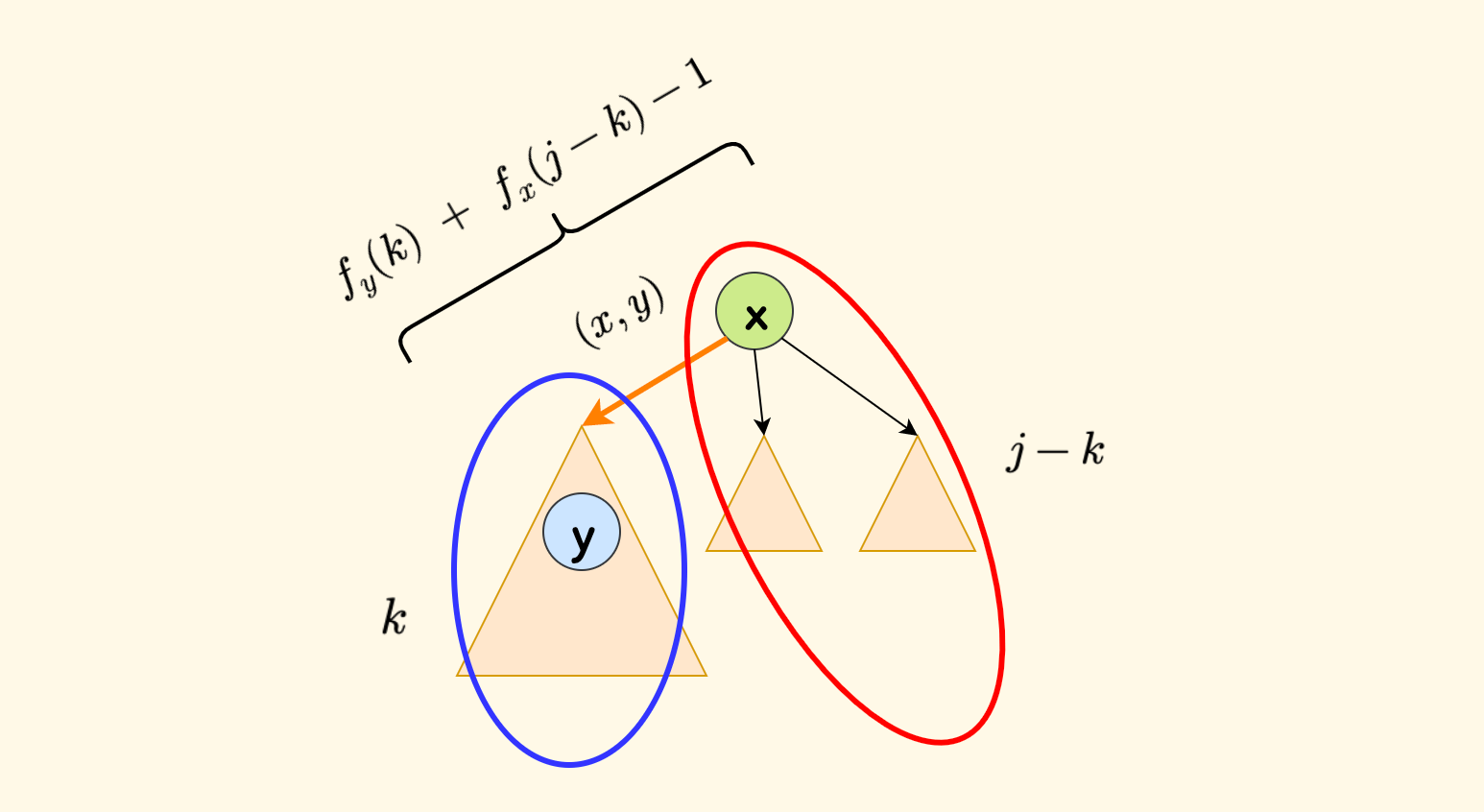
那么,此时子树 $x$ 内的删边数目是:
\[f_{y}(k)\ +\ f_{x}(j-k)-1\]这个减一的原因在于,我们要保留根节点 $x$,那么就不能删除边 $(x,y)$,也就是图中黄色的边。因为一旦删除这个边, 整个子树 $y$ 就都不会被保留了,也就无从谈起给 $y$ 分配了多少个要保留的节点了。
和树上背包模型一样,因为要保留根节点 $x$,所以 $j$ 的下界是 $1$,$k$ 的上界是 $j-1$。 此外,由于必须考虑保留子树 $y$,那么 $k$ 的下界是 $1$。
枚举每一个子树,和 $f_x(j)$ 取最小即可。
dfs 函数代码如下:
const int N = 151;
int n, p;
vector<int> edges[N];
// f[x][j] 表示子树 x 保留 j 个节点, 且包含 x 的最少需要删除的边的数目
int f[N][N];
void dfs(int x) {
f[x][1] = edges[x].size(); // 只保留 x 的时候
for (auto y : edges[x]) {
dfs(y);
// 枚举要保留的节点大小 j, 必须保留 x, 所以 j 至少1
for (int j = p; j >= 1; j--)
// 枚举子树 y 中分配了多少节点 k, 至多 j - 1 (保留 x)
for (int k = 1; k <= j - 1; k++)
// 因为必须保留子树 y, 所以边 (x,y) 不能删
// 那么就应该采用 f[x][j-k] - 1
f[x][j] = min(f[x][j], f[y][k] + f[x][j - k] - 1);
}
}
接下来计算答案,这里有点坑。
我们需要遍历每个节点 $x$,来考虑以 $x$ 为根的子树中、保留 $p$ 个节点时的最小答案。
- 对于整个树的根、$1$ 号节点来说,就是 $f_1(p)$。
但是,对于其他节点没这么简单,要想最终保留 $p$ 个节点 且 以 $x$ 为根的子树,那么要把根 $x$ 和它的上游也分离才可以。 要多删一条边,所以此时是 $f_x(p)+1$。


综合答案部分,代码如下:
int solve() {
memset(f, 0x3f, sizeof f);
dfs(1);
// 答案取整体最小
// 注意,根节点的时候,即 f[1][p]
int ans = f[1][p];
// 但是其他节点,要考虑把它和上游的连接也切掉,所以+1
for (int x = 2; x <= n; x++)
ans = min(ans, f[x][p] + 1);
return ans;
}
简单总结 ¶
- 主思路:以物品(节点)划分阶段、先解决子问题、再推导到更大的问题。
- 转移从子树向父节点进行,也就是阶段上、自底向上加入物品。
- 转移方式:枚举子树的分配,综合得到的新价值、取最值。
- 注意迭代的方向 和 边界。
(完)
相关文章:基础的几种背包模型
