本系列共分为四部分:
本文是第四部分。
Maglev一致性哈希算法 ¶
Maglev哈希算法来自 Google , 在其2016年发布的一篇论文中[1], 介绍了自2008年起服役的网络负载均衡器Maglev, 文中包括Maglev负载均衡器中所使用的一致性哈希算法,即Maglev一致性哈希 (Maglev Consistent Hashing)。
我们要设计一个一致性哈希算法, 要求映射均匀, 并尽力把槽位变化时的映射变化降到最小(避免全局重新映射)。
Maglev一致性哈希的思路是查表: 建立一个槽位的查找表(lookup table), 对输入 $k$ 做哈希再取余,即可映射到表中一个槽位。 下面的图1.1是一个示意图, 其中 $entry$ 是查找表,里面记录了一个槽位序列, 查找表的长度为 $M$, 当输入一个 $k$ 时, 映射到目标槽位的过程就是 $entry\left[hash(k) \% M\right]$。
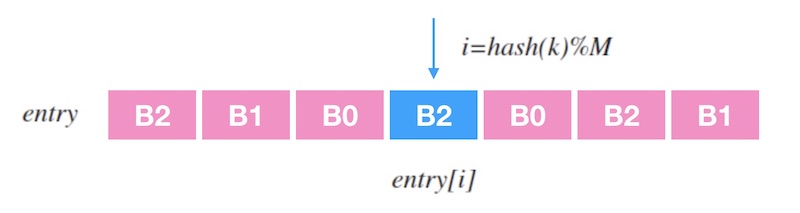
如何查表很好理解。 接下来看,如何生成一张查找表。 先新建一张大小为 $M$ 的待填充的空表 $entry$。 为每个槽位生成一个大小为 $M$ 的序列 $permutation$, 叫做「偏好序列」吧。 然后, 按照偏好序列中数字的顺序,每个槽位轮流填充查找表。 将偏好序列中的数字当做查找表中的目标位置,把槽位标号填充到目标位置。 如果填充的目标位置已经被占用,则顺延该序列的下一个填。 这么简短地讲不大容易明白, 看一个例子就可以清楚了。 下面图1.2是论文[1]中的演示填充查找表的原图:
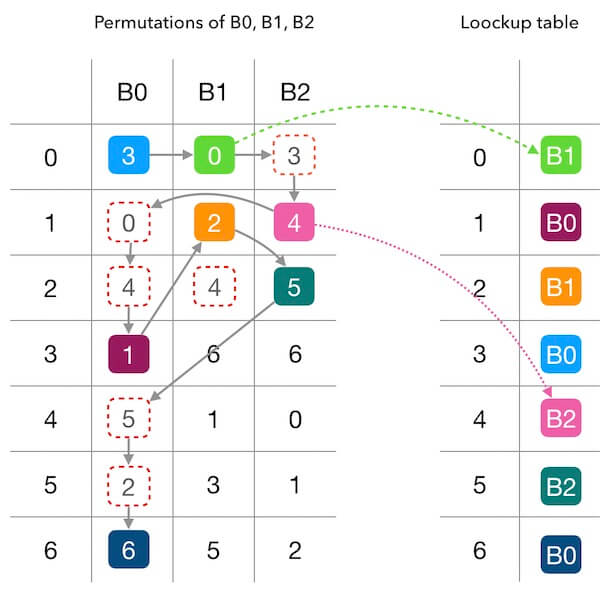
我做了一张更容易理解的图来理解填表过程。 下面的图1.3中,左边的每一个纵列代表槽位的偏好序列, 右边是我们要填充的查找表。 我们看下整个的填充过程:
- $B_0$ 的偏好序列的第一个数字是 $3$, 所以填充 $B_0$ 到 $entry \left[3 \right]$。
- 轮到 $B_1$ 填充了, $B_1$ 的偏好序列第一个是 $0$, 所以填充 $B_1$ 到 $entry \left[0 \right]$。
- 轮到 $B_2$ 填充了,由于 $entry \left[3 \right]$被占用, 所以向下看 $B_2$ 偏好序列的下一个数字,是 $4$, 因此填充 $B_2$ 到 $entry \left[4 \right]$。
- 接下来, 又轮到 $B_0$ 填充了, 该看它的偏好序列的第2个数字了,是 $0$,但是 $entry[0]$ 被占用了; 所以要继续看偏好序列的第3个数字,是 $4$, 同理, 这个也不能用,直到测试到 $1$ 可以用, 则填充 $B_0$ 到 $entry[1]$。
- 如上面的玩法, 直到把整张查找表填充满。
还有一个问题没有解决:偏好序列是怎么生成的? 取两个无关的哈希函数 $h_1$ 和 $h_2$, 假设一个槽位的名字是 $b$, 先用这两个哈希函数算出一个 $offset$ 和 $skip$
\[offset = h_1(b) \% M \\ skip = h_2(b) \% (M - 1) + 1\]然后, 对每个 $j$,计算出 $permutation$ 中的所有数字, 即为槽位 $b$ 生成了一个偏好序列:
\[permutation\left[j\right] = (offset + j \times skip) \% M\]可以看到,这是一种类似「二次哈希」的方法, 使用了两个独立无关的哈希函数来减少映射结果的碰撞次数,提高随机性。 生成偏好序列的方法可以有很多种(比如直接采用一个随机序列等), 不必须是 Google 的这个方法, 在原论文中也提到[1]:
Other methods of generating random permutations, such as the Fisher-Yates Shuffle, generate better quality permutations using more state, and would work fine here as well.
但是无论何种方式,目的都是一样的, 生成的偏好序列要随机、要均匀。
此外,论文中还提到[1]:
$M$ must be a prime number so that all values of $skip$ are relatively prime to it.
意思是, 查找表的长度 $M$ 必须是一个质数。 和「哈希表的槽位数量最好是质数」是一个道理, 这样可以减少哈希值的聚集和碰撞,让分布更均匀。
以上就是Maglev一致性哈希的算法的内容, 简单来说:
- 为每个槽位生成一个偏好序列, 尽量均匀随机。
- 建表:每个槽位轮流用自己的偏好序列填充查找表。
- 查表:哈希后取余数的方法做映射。
Maglev哈希算法的边缘情况 ¶
不过这个算法还存在一个边缘情况:假如所有的偏好序列都不包含某个数字呢? 下面的图1.4中,所有偏好序列都不包含 $2$,导致最终的查找表的 $entry\left[2\right]$ 是空的。
这种情况出现的概率非常低,但是并不是没有可能。 论文中未对这种情况做出说明,不过还是可以想到解决办法的(当然,方法不止一种): 如果填充后的查找表有位置没有被填充,可以统计下哪个槽位的占比最小,把那个槽位填到这里。
上面的图1.4中,不巧的是三个槽位都占了2个位置,那么直接随意给标号最小的 $B_0$ 好啦。
Maglev哈希的槽位增删分析 ¶
我们接下来看下这个算法是否满足一致性哈希算法的定义标准: 映射均匀和一致性。 由于偏好序列中的数字分布是均匀的,查找表是所有偏好序列轮流填充的, 容易知道,查找表也是分布均匀的, 这样,映射也是均匀的。 所以,下面着重分析下槽位增删对映射的干扰, 即分析槽位增删对查找表的填充的影响。
假如,槽位增删导致查找表的某个位置填充的槽位标号发生变化,我们称这是一种「干扰(disruption)」。 槽位增删必然导致填充干扰,我们的目的是追求这个干扰的最小化。
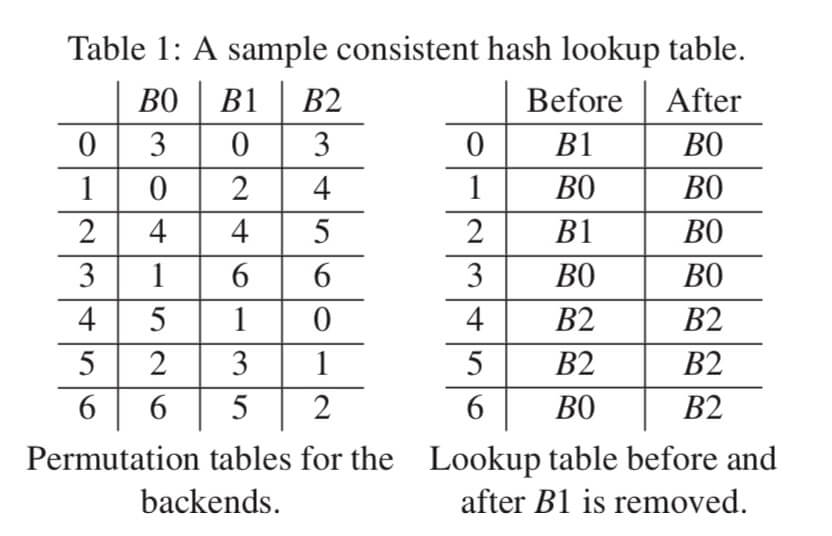
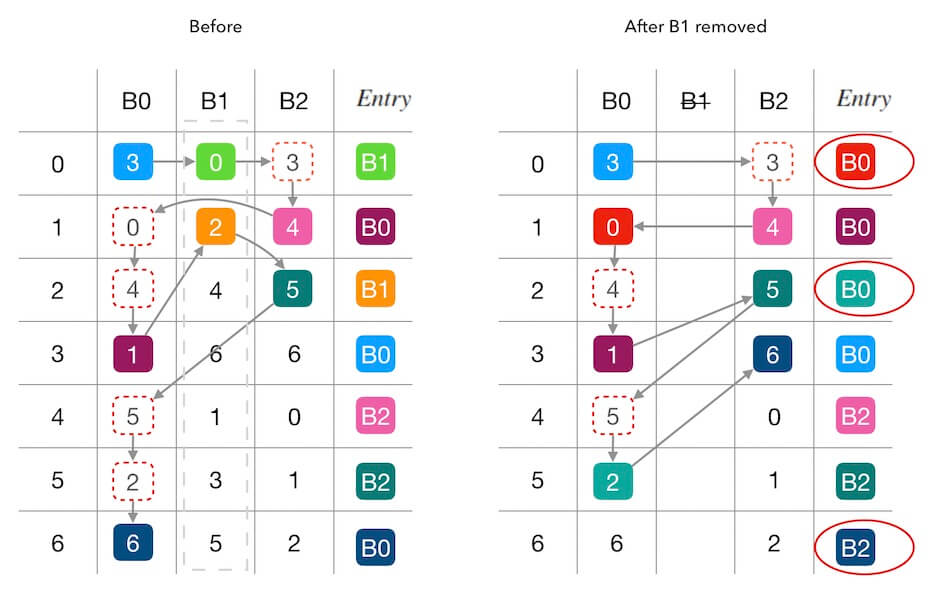
下面的图2.1中演示了删除槽位 $B_1$ 前后的填表情况。 红色圆圈内标出了受干扰的填表结果, 可以看到,查找表7个位置中有3个被重新填充。 其中两个位置(第 $0$,$2$行)是因为 $B_1$ 的移除导致被其他槽位接管, 还有一个第 $6$ 行的 $B_0 \rightarrow B_2$ 的联动干扰 (因为 $B_0$ 接管了 $B_1$ 的 $entry\left[2\right]$ 导致原本自己的 $entry\left[6\right]$ 被 $B_2$ 抢占)。
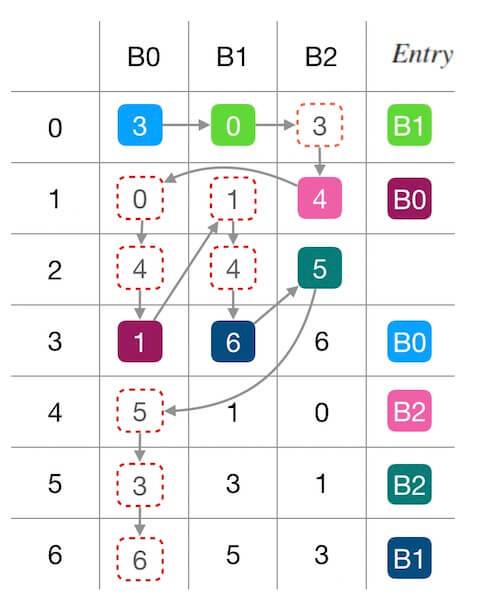
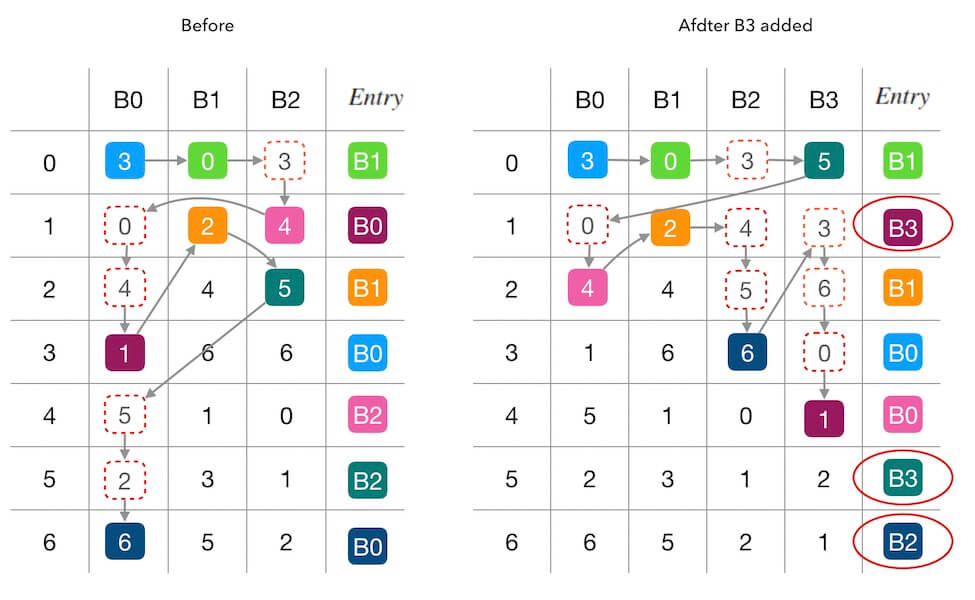
下面的图2.2中演示了新增槽位 $B_3$ 前后的填表情况。 同样,红色圆圈内标记了受干扰的填表结果, 可以看到,7个位置中有3个被重新填充。 其中两个位置(第 $1$,$5$行)是因为 $B_3$ 的加入抢占了其他槽位的填充机会, 另一个第 $6$ 行的 $B_0 \rightarrow B_2$ 则是一种联动干扰。
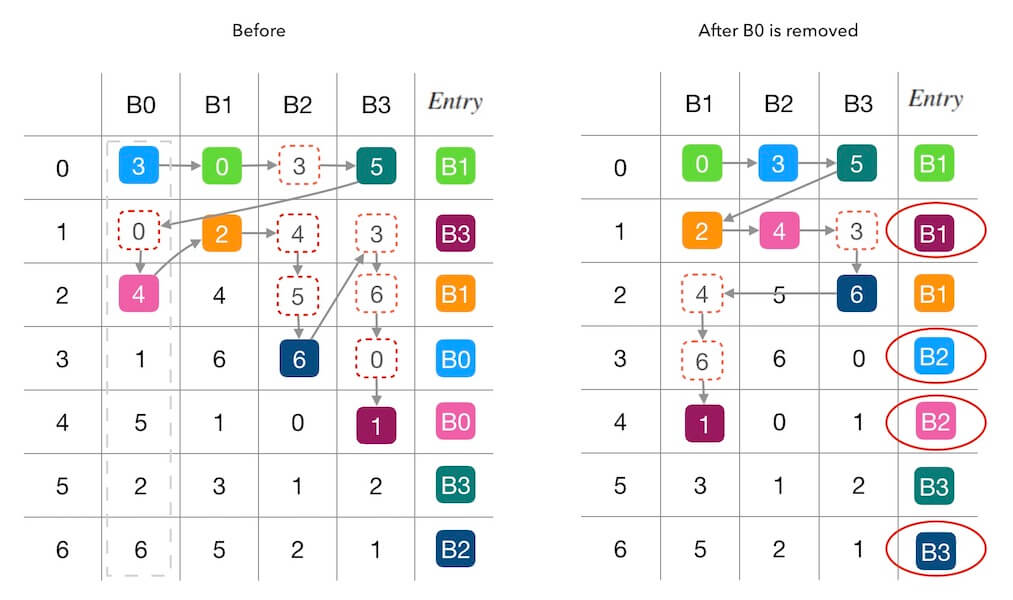
在上面图2.2的基础上,我们继续删除一个槽位 $B_0$, 看下前后的变化。 从下面的图2.3可以看出, 这一次的填表干扰更严重了, 7个里面出现了4个被重新填充。 其中两个(第 $3$,$4$ 行)是因为 $B_0$ 的移除导致位置被其他槽位接管, 还有两个(第 $1$,$6$ 行, $B_3 \rightarrow B_1$ 和 $B_2 \rightarrow B_3$)都是属于联动干扰。
查找表的重填意味着查表时的重新映射。 从上面的三个例子可以看出, Maglev一致性哈希虽然没有导致全量重新映射, 但却没有做到最小化重新映射。 论文[1]中关于Maglev哈希法对槽位增删带来的干扰影响的描述的用词是 minimal disruption, 而不是 minimum disruption 。 论文对于第一个例子的描述是这样的:
After B1 is removed, aside from updating all of the entries that contained B1, only one other entry (row 6) needs to be changed.
意思是,论文指出了联动干扰确实存在, Maglev哈希法并没有实现最小化的干扰。 不过,在 Google 的实际测试中总结出来, 当查找表的长度越大时,Maglev哈希的一致性会越好。
Maglev哈希的复杂度分析 ¶
显然,查表的时间复杂度是 $O(1)$ 。
下面分析下建表的复杂度。
论文[1]中给出了填表过程的伪代码实现。 其中,$N$ 是槽位的总数目,$permutation[i]$ 是槽位 $i$ 的偏好序列。 $next[i]$ 用来记录槽位 $i$ 的偏好序列将迭代的下一个位置(即这个序列该跑第几个了)。 对于每一个槽位 $i$ , 我们从它的偏好序列中找出一个候选的、还没占用的位置数字 $c$ , 然后把槽位标号 $i$ 填入查找表 $entry$ 中。

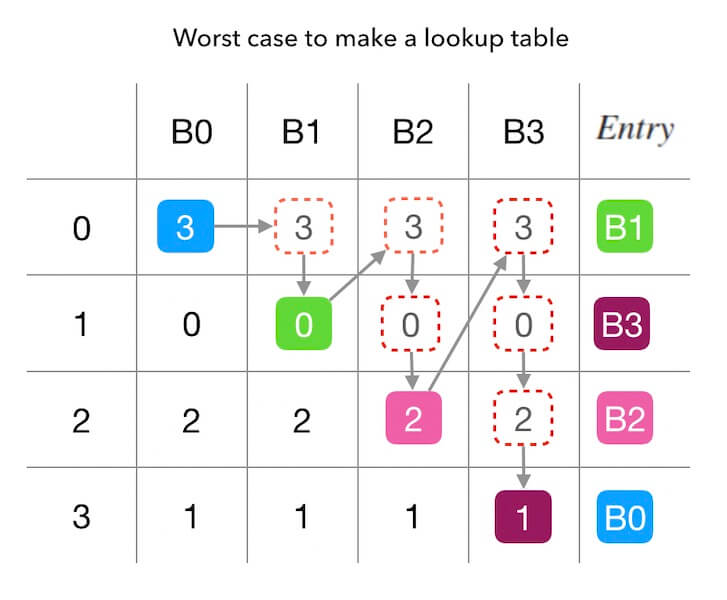
先看下,最坏的时间复杂度是怎样的? 那肯定是,在查找下一个合适的填充位置的时候, 把所有已经被抢占的位置数字放在这个目标位置的前面, 这样的尝试次数最多! 这种情况发生在 $N = M$ 且 所有偏好序列完全一样的情况下。 下面的图3.2中描述了这种复杂度最高的情况, 有3个槽位、查找表的长度为3、而且所有偏好序列都一样, 总共需要尝试 $4+3+2+1$ 个数字(也就是 ${((4+1)\times 4)} / {2}$), 所以最坏复杂度是 $O(((M+1)\times M)/2)$, 即平方级别的 $O(M^2)$。
现在考虑下平均的时间复杂度, 我们就要分析这个过程总共需要尝试多少个数字。 一步一步来想:
- 第一次填表的时候,由于查找表 $entry$ 还是空的,所以第一个数字一定合适, 只需要尝试 $1$ 次。
- 第二次填表的时候,由于前面已经填了一个槽位到 $entry$ 中, 所以空余的空位还有 $M-1$ 个, 所以每个空位被选中的概率是 $1/(M-1)$。 每次查找一个可以填充位置的过程,都是在一个偏好序列中尝试, 而序列的长度是 $M$ , 所以需要尝试 $M/(M-1)$ 次。
- 依次类推, 当我们已经填充了查找表 $entry$ 的 $n$ 个位置的时候, 我们下一步就需要尝试 $M/(M-n)$ 次来找到下一个可以填充的空位置。
计算下来,总共需要尝试的次数是: $M/M + M/(M-1) + … + M / (M - (M-1))$, 即 $\sum _{ n=1 }^{ M }{ \frac { M }{ n } }$, 是 $1$ 到 $1/M$ 的倒数之和 与 $M$ 的乘积。 调和级数和自然对数的差是收敛到一个小数的, 所以,平均的时间复杂度是对数级别的 $O(Mln(M))$, 也就是 $O(Mlog(M))$ (注意到 $O(ln(n)) = O(\frac { log_{2}{n} } { log_{2}{e} })$)。
一般选择 $M \gg N$ ($M$ 远大于 $N$) , 这样各个槽位的偏好序列更随机、均匀,也不容易发生不同槽位的偏好序列一样的情况。 当然,也不是越大越好, 越大的 $M$ 意味着更高的内存消耗、更慢的建表时长。 结合前面所讲的内容, 应该选择一个远大于 $N$ 的质数当做查找表的大小 $M$。 论文中提到,在 Google 的实践过程中,一般选择 $M$ 为一个大于 $100 \times N$ 的质数, 这样各个槽位在查找表上的分布的差异就不会超过 $1\%$。
Maglev哈希的测试表现 ¶
论文中对Maglev一致性哈希的测试关注在两个指标: 映射的平均性 和 对槽位变化的适应能力。
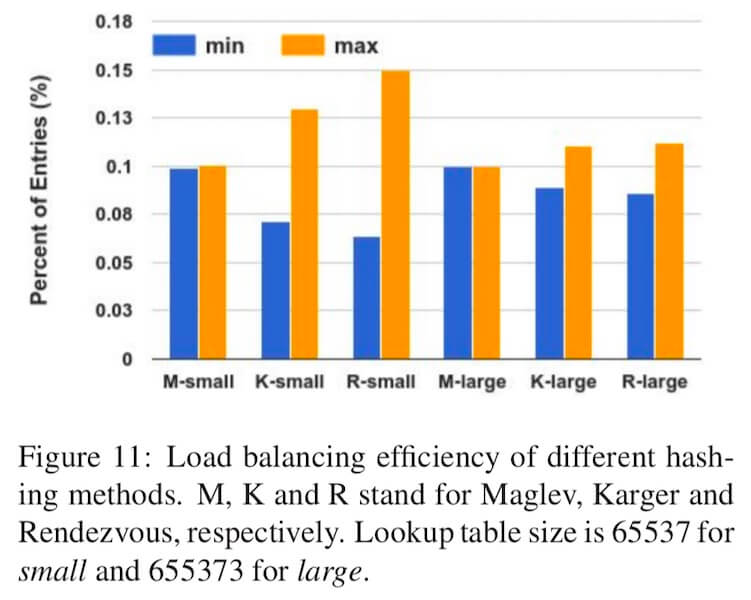
下面图4.1对比了 Maglev哈希、 经典的哈希环算法(Karger hash ring) 和 Rendezvous哈希环算法 在不同槽位数量的情况下(对应的查找表大小分别是 $65537$ 和 $655373$ ), 映射结果中占比最大和最小的槽位的占比。 从图中可以看到,两种槽位数量的情况下,Maglev的映射结果中占比最大和占比最小的占比量都非常接近, 也就是说,Maglev一致性哈希的映射平均性非常好。
关于槽位增删对映射一致性的干扰影响,由于哈希环算法实现了最小的重新映射, 所以当删除槽位时(比如节点故障时)哈希环算法可以保证剩余的槽位的映射不受影响。 而我们前面有分析,对于Maglev算法来讲, 则并没有做到最小的重新映射。 下面的图4.2中是 Google 对Maglev负载均衡器做的测试结果, 演示了在相同数量的后端节点、但是不同大小的查找表的情况下(分别是 $65537$ 和 $655373$), 映射结果发生变化的节点的占比相对于节点故障占比的关系。 可以看到,查找表越大,Maglev哈希对槽位增删的容忍能力更强,映射干扰也越小。
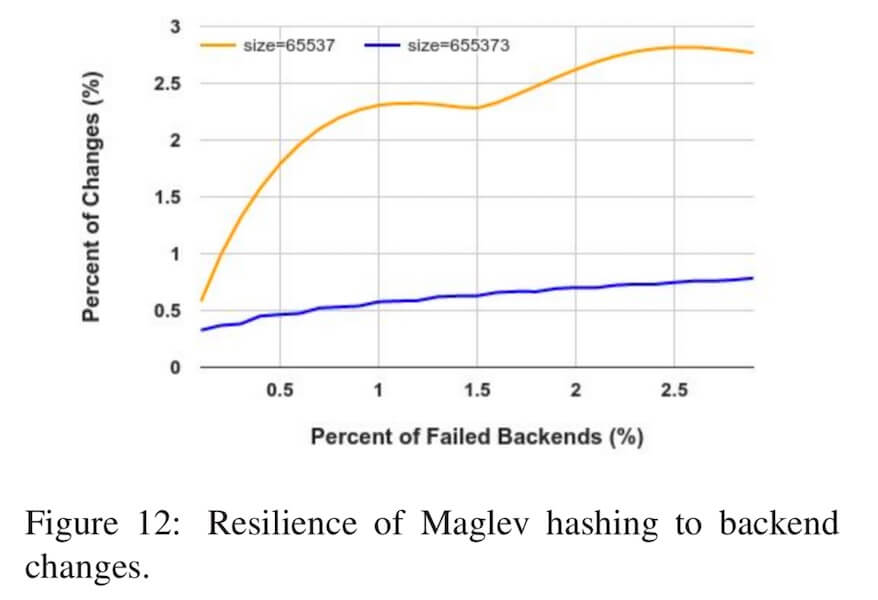
不过,即使这样,实际中 Google 仍然选择 $65537$ 作为查找表大小。 论文中给出的说法是, 当他们把查找表大小从 $65537$ 调大到 $655373$ 时, 查找表的生成时间从 $1.8ms$ 升高到了 $22.9ms$, 所以查找表的大小不是越大越好。 论文中同时提到:
because we expect concurrent backend failures to be rare, and we still have connection tracking as the primary means of protection.
意思是说, 在 Google 的场景下, 并没有把后端槽位的变化带来的干扰看的太重要。 实际上,工程中节点损失是低概率事件, 并且 Google 的设计中主要的保护手段是连接跟踪,而不是完全依赖一致性哈希。 这样,也可以理解了,这个一致性哈希算法的设计上就没有做到最小化干扰的要求。
Maglev哈希的热扩容和容灾 ¶
对于Maglev哈希来讲,热扩容或许还可以做,容灾却无法依赖备份的方式进行。
回到kvdb的例子上来, 看一下我们的诉求:
- 扩容: 新加一个节点, 如何做到不停服?
- 容灾: 损失一个节点,如何做到影响最小?
先看第一个问题: 如何做热扩容。
新加一个全新的节点时, 必然要迁移数据才可以服务。 还是采用类似的办法,即请求中继: 新加入的节点对于读取不到的数据,可以把请求中继(relay)到老节点,并把这个数据迁移过来。
老节点是什么呢? 就是加入新节点之前,数据应该映射到的那个节点。举例子来说, 观察前面的图2.2中,假设数据 $k$ 先前映射到的节点是 $B_0$, 后来因为新加入了节点 $B_3$, 导致 $k$ 现在映射到 $B_3$, 那么 $B_0$ 就叫做 $k$ 的老节点。
要知道数据的老节点是什么,就要保存一份加入新节点之前的查找表。 也就是节点要保存两份查找表。如果经最新的查找表映射到的节点上没有数据, 再去经老查找表映射到老节点上去查。
然而第二个问题: 如何做容灾, 则没那么容易。
图2.3演示了删除一个节点的情况,为了演示方便,这里直接把图2.3照搬下来:
图2.2中演示了新增节点前后的填表情况,如果我们从右往左看,它也可以演示删除节点的情况, 就是下面图5.1的样子:
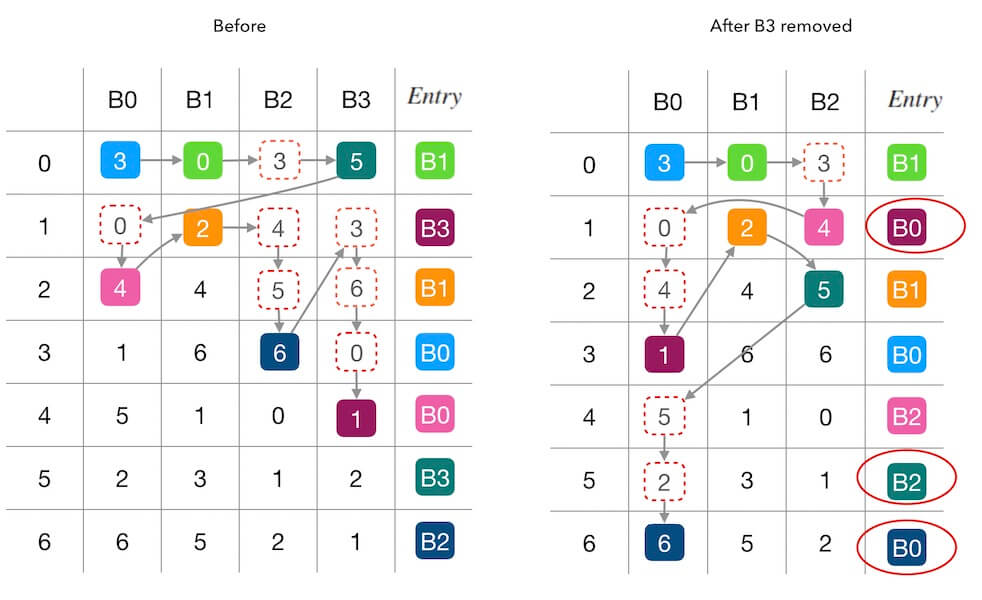
可以观察到两个图中都是从完全一样的状况、完全一样的表格,分别删除不同节点的情况。 图2.3中,删除 $B_0$ 后,导致了一个 $B_3 \rightarrow B_1$ 的映射变化。 所以, 我们需要把 $B_3$ 的数据备份到 $B_1$ 上,才可以应对这一变化,而不丢数据、不停服。 图5.1中,删除 $B_3$ 后则导致了 $B_3 \rightarrow B_0$ 和 $B_3 \rightarrow B_2$的映射变化, 意思是, 在损失节点 $B_3$ 之后, $B_3$ 中的数据一部分会映射到 $B_0$ 上, 一部分又会映射到 $B_2$ 上, 我们除非把 $B_3$ 的数据全部备份一份到 $B_0$, $B_1$, $B_2$ 上, 否则没有很好的办法做 $B_3$ 的数据备份。
这样,关于容灾这个话题, 我的结论是没有很好的办法做数据备份,所以无法做不停服的容灾处理。 (需要注意:这部分并不是论文中的内容,而是我个人的分析结论。)
论文中所讨论的Maglev哈希算法的应用场景是负载均衡,确切的说是弱状态化的后端的负载均衡。 如果后端节点的数据是类似数据库性质的强状态化数据,那么就会有容灾设计的问题。 如果后端节点是无状态的、或者是弱状态的(如缓存), Maglev哈希算法的一致性的特点还是有好处的:比如降低故障情况下的缓存击穿的比例、连接重新建立的比例等等。
带权重的Maglev哈希 ¶
Maglev哈希做到了尽量平均的映射分布,但是,如果槽位之间不是平权的呢? 关于带权重的Maglev哈希,论文中只提了一句话:
Heterogeneous backend weights can be achieved by altering the relative frequency of the backends’ turns.
意思是,可以通过改变槽位间填表的相对频率来做加权。 就是不「轮流」填了,可以你填1次,我填3次。 填表越频繁的槽位,权重就越大。
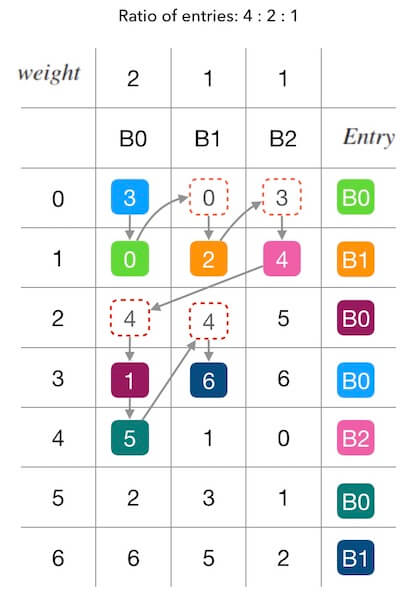
最后我们再玩一次填表游戏。下面的图6.1中,假设 $B_0$ 的权重是 $2$, 其他的槽位的权重都是 $1$, 也就是其他槽位每填表一次, $B_0$ 填表两次。 可以观察到,填表的结果上, $B_0$ 的席位占比 $4/7$, 符合权重的设定。
小结 ¶
Maglev哈希是 Google 在自家的负载均衡器Maglev中使用的一致性哈希算法。 槽位变化时,虽然避免了全局重新映射,但是没有做到最小化的重新映射。 映射的均匀性非常好。映射的时间复杂度是 $O(1)$, 建立查找表的时间复杂度是 $O(Mlog(M))$。 可以通过改变填表的相对频率来实现加权。 难以实现后端节点的数据备份逻辑,因此工程上更适合弱状态后端的场景。
– 毕 「一致性哈希算法 - Maglev哈希」
三个方法的总结 ¶
最后对一致性哈希环、跳跃一致性哈希和Maglev哈希做一次总结:
| 均匀性 | 最小化重新映射 | 时间复杂度 | 加权映射 | 热扩容 & 容灾 | |
|---|---|---|---|---|---|
| 哈希环 | ⍻ | ✔ | $O(log(n))$ | ✔ | ✔ |
| 跳跃一致性哈希 | ✔ | ✔ | $O(log(n))$ | ✔ | ✔ |
| Maglev哈希 | ✔ | ✘ | $O(1)$ | ✔ | ✘ |
引用 & 脚注 ¶
- Google, Daniel E., Cheng Yi etc. 2016. Maglev: A Fast and Reliable Software Network Load Balancer
本文原始链接地址: https://writings.sh/post/consistent-hashing-algorithms-part-4-maglev-consistent-hash
