本系列共分为四部分:
本文是第三部分。
跳跃一致性哈希法 ¶
跳跃一致性哈希 ( Jump Consistent Hash ) 是 Google 于2014年发布的一个极简的、快速的一致性哈希算法[1]。 这个算法精简到可以用几行代码来描述, 下面的就是 Google 原论文中的算法的 C++ 表示:
int32_t JumpConsistentHash(uint64_t key, int32_t num_buckets) {
int64_t b = -1, j = 0;
while (j < num_buckets) {
b = j;
key = key * 2862933555777941757ULL + 1;
j = (b + 1) * (double(1LL << 31) / double((key >> 33) + 1));
}
return b;
}
函数 JumpConsistentHash 是一个一致性哈希函数, 它把一个 key 一致性地映射到给定几个槽位中的一个上, 输入 key 和槽位数量 num_buckets, 输出映射到的槽位标号。
这个函数虽然短,却不那么容易看懂。 现在,先不要纠结上面这个函数本身, 我们一步一步地看论文中是如何推导出来这个函数的。
跳跃一致性哈希法的推导 ¶
假设,我们要求的一致性哈希函数是 $ch(k, n)$, $n$是槽位数量, $k$ 是要映射的键 key, $K$是映射的数据的总数量:
- 当 $n=1$ 时, 所有的 $k$ 都要映射到一个槽位上, 函数返回 $0$, 即 $ch(k, 1) = 0$。
- 当 $n=2$ 时, 为了映射的均匀, 每个槽要映射到 $K/2$ 个 $k$, 因此需要 $K/2$ 的 $k$ 进行重新映射。
- 以此类推, 当槽位数量由 $n$ 变化为 $n+1$ 时,需要 $K/(n+1)$ 个 $k$ 进行重新映射。
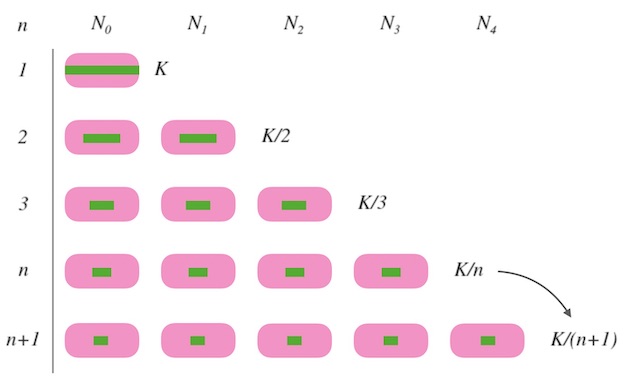
我们知道了每次需要重新映射多少份,才可以保证映射均匀。 接下来的问题是: 哪些 $k$ 要被重新映射呢? 就是说在新加槽位的时候,要让哪些 $k$ 跳到新的槽位, 哪些 $k$ 留在老地方不动呢?
Google 的办法是用随机数来决定一个 $k$ 每次要不要跳到新槽位中去。 但是请注意,这里所说的「随机数」是指伪随机数,即只要种子不变,随机序列就不变。 我们程序语言中的随机数发生器都是伪随机的:
>>> random.seed('some-seed')
>>> random.random(), random.random(), random.random()
(0.5294407477447773, 0.9935403183087578, 0.1439482942989072)
>>> random.seed('some-seed')
>>> random.random(), random.random(), random.random()
(0.5294407477447773, 0.9935403183087578, 0.1439482942989072)
对每一个 $k$ , 我们用这个 $k$ 做随机数种子,就得到一个关于 $k$ 的随机序列。 为了保证槽位数量由 $j$ 变为 $(j+1)$ 时有 $1/(j+1)$ 占比的数据会跳到新槽位 $(j+1)$, 就可以用如下的条件来决定是否重新映射: 如果random.next() < 1 / (j+1) 则跳, 否则留。 那么,我们得到了初步的一个 $ch$ 函数:
int ch(int k, int n) {
random.seed(k);
int b = 0; // This will track ch(k, j+1).
for (int j = 1; j < n; j++) {
if (random.next() < 1.0/(j+1)) b = j;
}
return b;
}
可以看到,跳跃一致性哈希方法的思路和 跳跃表 skiplist 有些相似。
下面的图8.2是对这个函数的一个演绎。 $n$ 从 $1$ 变化到 $5$ 的过程中, $k_1$ 和 $k_2$ 每一次都要根据随机序列相应的值和目标分布 $1/n$ 的比较, 来决定留在原来的槽位还是跳到新槽位。
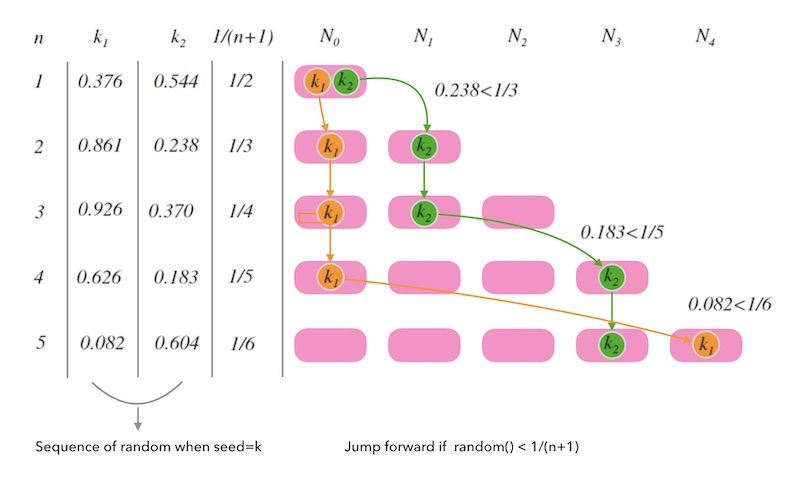
需要注意的是, $k$ 一旦确定, 随机序列就确定了, 每次计算 $ch$ 函数,都会重新初始化随机数种子, 这样后面的 for 循环就是在遍历一个确定的序列而已。 并不是真正的随机数。 就是说, $k$ 一旦确定, 给定一个 $n$ 时, $k$ 的映射结果都是唯一确定的, 也就是一致的。
另一方面,虽然随机序列是由种子决定的, 但是随机序列足够均匀,这才能保证 $ch$ 函数映射结果的均匀性。
$ch$ 函数没有造成全量重新映射, 而是 $1/(n+1)$ 份重新映射, 这个函数已经达到了一致性哈希算法的定义标准。 可以说,跳跃一致性哈希做到了最小化重新映射(minimum disruption), 做到了完全的一致性。
分析下它的时间复杂度呢? 显然是 $O(n)$ 。 接下来我们把这个时间复杂度优化到 $log$ 级别。
不难得知, $random.next() < 1/(j+1)$ 发生的概率是相对小的。 所以我们的判断条件命中率并不高, 只有少数的 $k$ 选择跳, 这正是优化点, 现在的 $j$ 是一步一步跑的, 那么接下来我们让 $j$ 跳着跑。
上面的 $ch$ 函数中, $b$ 是用来记录 $k$ 最后一次跳入的槽位标号。 假如我们现在处在 $k$ 刚刚跳入最后一个槽位的时刻, 此时一定有 $(b+1)$ 个槽位。 接下来的时刻, 我们要再新增一个槽位变为 $b+2$ 个时, 易知 $k$ 不换槽位的概率是 $(b+1) / (b+2)$。 假设我们要找的下一个 $b$ 是 $j$, 就是说,假设当槽位数目到了 $j+1$ 个时 $k$ 跳入最新槽位, 那么, 在此期间, $k$ 保持连续不换槽位的概率是(注意计算的终止项):
\[P(stay\_until\_j) = \frac {(b+1)} {(b+2)} * \frac {(b+2)} {(b+3)} * … * \frac {(j-1)} {j}\]化简得, $k$ 连续不跳槽直到增加到 $j+1$ 个槽位才跳的概率为 $(b+1)/j$。
下面图8.3 中, 虚线框内表示连续不变槽位, 其概率就是各次不变槽位的概率之积。
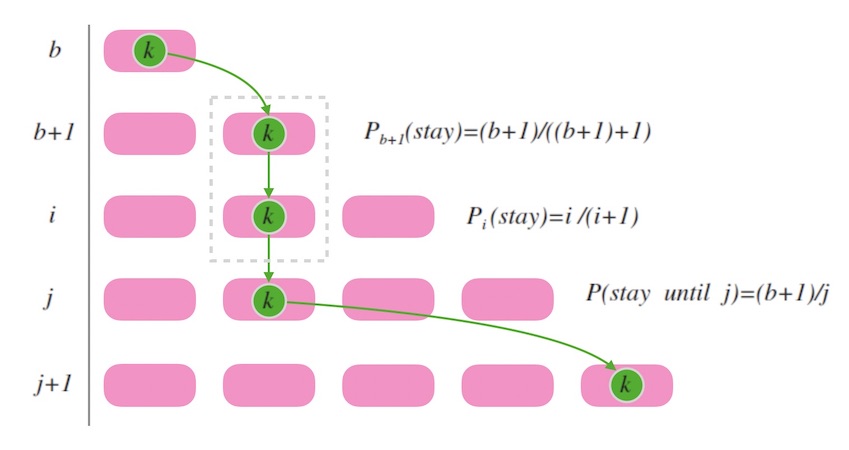
联系下我们前面设计的 $ch$ 函数, 我们改写函数 $ch$ 如下, 意即, 当符合连续不换槽的概率时, $j$ 直接跳过:
int ch(int k, int n) {
random.seed(k);
int b = 0, j = 0;
while (j < n) {
if (random.next() < (b+1.0)/j) b = j;
j += continuous_stays;
}
return b;
}
设 $r = random.next()$ 要满足 $r < (b+1)/j$ , 就必须 $j < (b+1) / r$ ,就是说 $j$ 不得大于 $(b+1) / r$ 才不至于漏掉迭代, 所以 $j$ 最多移动到 $(b+1) /r$,向下取整即 $floor(b+1)/r$, 进一步改写 $ch$ 函数如下:
int ch(int k, int n) {
random.seed(k);
int b = -1, j = 0;
while (j < n) {
b = j;
r = random.next();
j = floor((b+1) / r);
}
return b;
}
现在来分析下它的时间复杂度。 因为 $r$ 的分布是均匀的, 在槽位数将变化为 $i$ 的时候跳跃发生的概率是 $1/i$, 那么预期的跳跃次数就是 $1/2 + .. + 1/i + .. + 1/n$ , 调和级数和自然对数的差是收敛到一个小数的, 所以复杂度是 $O(ln(n))$。
论文[1]中提到:
It is interesting to note that jump consistent hash makes fewer expected jumps (by a constant factor) than the log2(n) comparisons needed by a binary search among n sorted keys.
意思是, 跳跃一致性哈希算法的复杂度是比二分查找的复杂度 $O(log(n))$ 要快一些的,因为有一个常数。 我猜了下作者的意思应该是这样的:
\[O(ln(n)) = O(\frac { log_{2}{n} } { log_{2}{e} })\]因为 $log_{2} e$ 是一个大于1的数, 所以, $O(ln(n))$ 虽然在复杂度上和 $O(log(n))$ 一样,都是对数级别复杂度, 但是,二分查找的复杂度是二分的,底是2, 跳跃一致性哈希的底是 $e$ , 跳的要更快。
还是没有达到最终 Google 的函数呀? 因为 Google 的 JumpConsistentHash 函数没有用语言自己的 $random$ , 而是自己做了一个64位的线性同余随机数生成器。
跳跃一致性哈希算法的设计非常精妙, 我认为最美的部分是利用了伪随机数的一致性和分布均匀性。
跳跃一致性哈希的特点 ¶
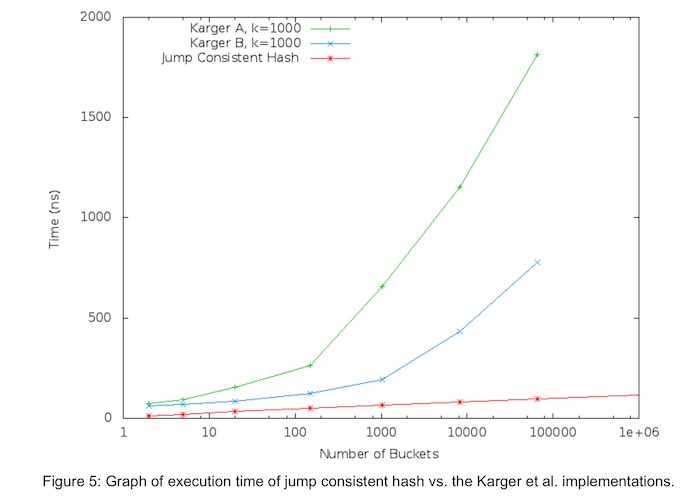
根据论文[1]中的试验数据来看, 跳跃一致性哈希在执行速度、内存消耗、映射均匀性上都比经典的哈希环法要好。
下图是论文[1]中跳跃一致性哈希算法和哈希环法关于运行时间的对比, 可以看到红色的线(jump hash)是明显耗时更低的。
下图是论文[1]中跳跃一致性哈希算法和哈希环法关于映射分布的均匀性的对比, 其中 Standard Error是指分布的标准差, 标准差越小则分布越均匀。 可以看到跳跃一致性哈希的分布要比哈希环的方式均匀的多。 这一点也可以理解, 跳跃一致性哈希的算法设计就是源于对均匀性的推理。
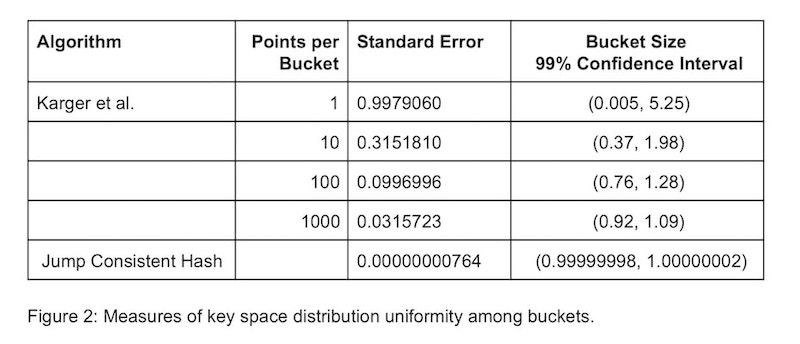
关于内存消耗上的对比结果, 其实已然不言自明。 经典的一致性哈希环需要数据结构的支撑, 空间复杂度是 $O(N)$ 的, 而跳跃一致性哈希算法几乎没有额外内存消耗。
一切看上去都很美好, 但是,跳跃一致性哈希算法有两个显著缺点:
无法自定义槽位标号
跳跃一致性哈希算法中, 因为我们没有存储任何数据结构, 所以我们无法自定义槽位标号, 标号是从 $0$ 开始数过来的。
只能在尾部增删节点
下面图9.3, 假如我们在非尾部添加一个新的槽位, 会导致这个位置后续的槽位的标号全部发生变化。 所以在非尾部插入新槽位没有意义, 我们只能在尾部插入。

图9.3 - 跳跃一致性哈希中在非尾部插入新槽位没有意义 对于在非尾部删除一个槽位也是一样的, 我们只能在尾部删除。

图9.4 - 跳跃一致性哈希中在非尾部删除槽位 如果导致后面的槽位全部重新标号,更提不上一致性映射。


跳跃一致性哈希下的热扩容和容灾 ¶
回到kvdb的例子上来, 我们讨论下如下问题:
- 扩容: 新加一个节点, 如何做到不停服?
- 容灾: 损失一个节点,如何做到影响最小?
先看第一个问题: 如何做热扩容。
新加一个全新的节点时, 必然要迁移数据才可以服务。 可以采用和一致性哈希环法类似的办法, 即请求中继: 新加入的节点对于读取不到的数据,可以把请求中继(relay)到老节点,并把这个数据迁移过来。
「老节点」是什么? 假如此次扩容时,节点数目由 $n$ 变为 $n+1$, 老节点的标号则可以由 $ch(k, n)$ 计算得出, 即节点数量为 $n$ 的时候的 $k$ 的槽位标号。
下图10.1是一个示例, 当新加一个节点 $N_n$ 时, $k$ 被映射到新的槽位。 老节点标号是 $N_{old} = ch(k, n)$。 当一个查询 $get(k)$ 到来, 因为 $k$ 此时映射到的是新节点 $N_n$ , 所以可能会查不到数据, 接下来把请求中继到老节点 $N_{old}$ , 即可以查到结果。 同时 $N_n$ 把 $k$ 对齐到自己这里。
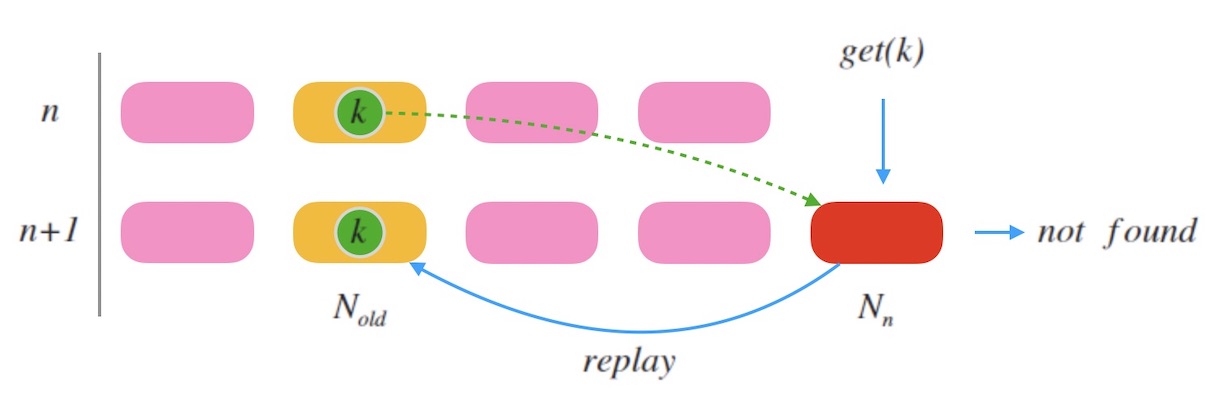
通过这种方式,可以做到整个系统不停服扩容。 关键在于如何找到老节点。
再看第二个问题: 如何做容灾。
先看下,当我们移除一个节点时,会造成什么影响?
假如移除最后一个节点, 如下图10.2中, 尾部节点 $N_4$ 被移除后, 整体映射情况和节点数为 $n$ 的时候是一致的。 一切看上去还好。 只要考虑如何备份 $N_4$ 上的数据就可以了。 参考上面如何扩容的玩法,可以把尾部节点的数据备份到老节点 (例如,图10.2中 $k_2$ 的老节点就是 $N_3$)。
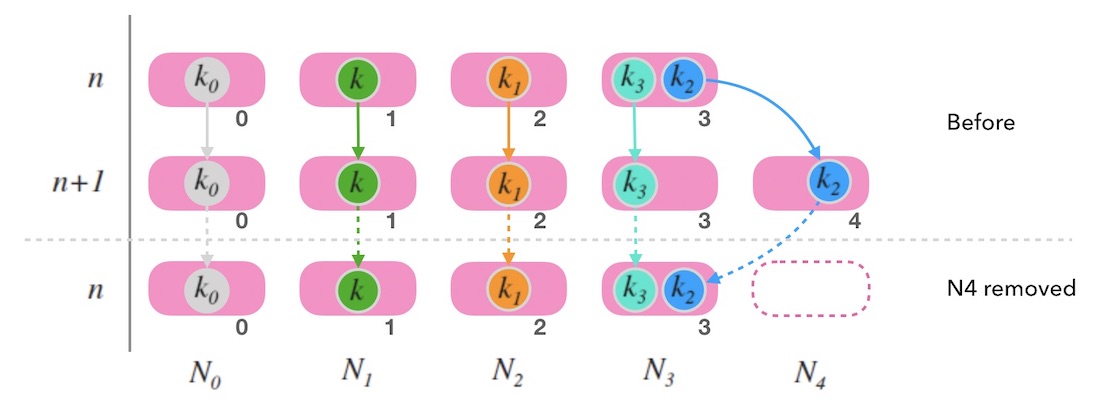
但是,移除一个非尾部节点的情况就不一样了。 下面的图10.3中,移除 $N_1$ 时,映射的整体结果会发生较大变化, 造成了大面积的映射右偏现象。 原因在于, 虽然跳跃一致性哈希映射到的节点标号和节点数是 $n$ 的情况是一致的, 但是,映射到的节点本身已经变化了。 在这种情况下,因为大量数据的重新映射, 跳跃一致性哈希已经不符合一致性哈希的定义标准, 带来的数据迁移的工作量也是巨大的。
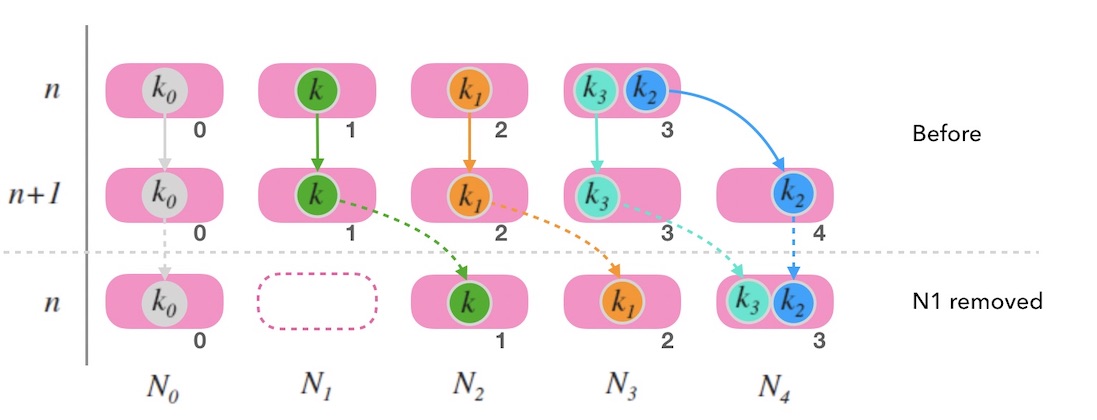
现实中,节点故障是肯定有可能发生在非尾部节点的。一旦这种情况发生, 除了故障数据丢失的问题之外,还面临大面积的映射偏移的问题。
至此,或许可以想到如何备份来容灾了,在执行数据写操作时,同时写一份数据到备份节点。 备份节点这样选定:
- 尾部节点备份一份数据到老节点。
- 非尾部节点备份一份数据到右侧邻居节点。
我们看下在这个容灾策略下的效果:
当删除尾部节点时:
下图10.4中, 删除了 $N_4$ 后, $k_2$ 被重新映射到 $N_3$, 因为 $N_4$ 的数据在 $N_3$ 有备份, 因此正常。

图10.4 - 跳跃一致性哈希中的容灾策略 当删除非尾部节点时:
下图10.5中, 删除了 $N_1$ 后, 由于 $k$, $k_1$, $k_3$ 都在邻居节点上有备份, 所以此时映射右偏后并不会造成三个数据丢失, 而且查询也是正确的。

图10.5 - 跳跃一致性哈希中的容灾策略


至此,跳跃一致性哈希下的热扩容和容灾的思路就讨论到这里。 虽然跳跃一致性哈希表现这么简单,思考起来比经典的哈希环法要复杂一些。
带权重的跳跃一致性哈希 ¶
最后,讨论下跳跃一致性哈希法如何对映射加权。
我们同样可以尝试虚拟节点(影子节点)的办法来做权重。
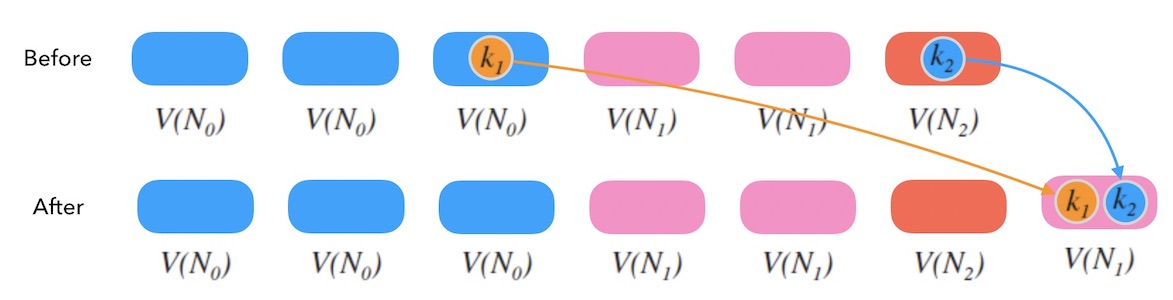
下面图11.1中, $V(N_{i})$ 表示 $N_{i}$ 的影子节点, 可以看到 $N_0$, $N_1$, $N_2$ 的权重比是 $3:2:1$。 当我们把比重变成 $3:3:1$ 时,和一致性哈希环一样, 可能会引起数据的重新映射,带来数据迁移工作。
小结 ¶
跳跃一致性哈希法最显著的特点是: 实现轻巧、快速、内存占用小、映射均匀、算法精妙。 但是,原始的跳跃一致性哈希算法的缺点也很明显,不支持自定义的槽位标号、而且只能在尾部增删槽位。 不过我们讨论下来,在这个算法下做热扩容和容灾也是有路可循的, 但是理解起来远不及哈希环直观。
– 毕「一致性哈希算法 - 跳跃一致性哈希法」。
本系列的下一文章 一致性哈希算法(四) - Maglev一致性哈希法。
引用 & 脚注 ¶
- John Lamping, Eric Veach, from Google. A Fast, Minimal Memory, Consistent Hash Algorithm
本文原始链接地址: https://writings.sh/post/consistent-hashing-algorithms-part-3-jump-consistent-hash
