I want to quote this sentence from The Pattern on the Stone again:
One reason why finite state machines are so useful is that they can recognize sequences.
Regular expressions are based on state machines.
This article only covers the key processes, and basic concepts will no longer be explained.
Foreword ¶
The construction of a regular expression engine can be divided into three steps:
- Parse the regular expression through the double-stack method and construct an equivalent NFA.
Convert the NFA to an equivalent DFA through the subset construction method.
This is not required, although NFA can also recognize strings, DFA runs faster.
- Simplify the DFA to the minimum number of states through Hopcroft’s algorithm. This step is also not required, it just makes the space usage more optimal.
In addition, the actual code implementation may be slightly more complex. For the sake of clarity, the article will use Python-like pseudo-code to illustrate. The specific Python and C++ code are placed in the link at the end of the article.
The regular expression to be implemented is very simple. It only supports the following rules:
abConcatenate two expression stringsa|bTake the “or” relationship between two expressions, matching either onea*Kleene closure, i.e., repeat 0 or more timesa?Indicates optional, i.e., occurs 0 or 1 timea+Indicates repeat 1 or more times, which is actuallyaa*[0-9]Indicates a character within a certain range is hit, for example,[a-zA-Z]indicates upper and lower case letters are hit.(ab)Parentheses indicate that the expression within has priority in binding
For example: (a|b)*ab can match the string aaab, but cannot match bbba. For another example, [0-9]* can match the digit string 123, but cannot match abc.
The priority of closure operators should be higher than other operators. The quantified table of priorities precedence is as follows:
| Operation | Priority (Higher is Larger) |
|---|---|
ab | 1 |
a|b | 1 |
a* | 2 |
a? | 2 |
a+ | 2 |
In terms of data structure, both NFA states and DFA states have at least two fields:
idis the unique identifier of the state.is_endindicates whether this state is a final state.
The structure State is used as the base class for states, and NfaState and DfaState will inherit from it.
Code representation of State base class
class State:
id: int
is_end: bool
Next, the three processes will be explained in detail.
Constructing an NFA ¶
Under the same input symbol, the NFA state may have multiple target states. Therefore, the structure design of the NFA state is as follows:
Code representation of NfaState
class NfaState(State):
# Transition table, { Char => { Target States... }}
transitions: dict[C, set[NfaState]] = {}
def add_transition(self, ch, to):
self.transitions[ch].add(to)
if self.is_end:
self.is_end = False
The add_transition method is responsible for adding a transition relationship from the current state to the target state.
One difference between NFA and DFA is that NFA can add empty edges. In this article, the symbol epsilon, which is the Greek letter ε, is used to represent the empty symbol.
An empty edge means that you can move along it without inputting a symbol. If the target state also has an empty edge, this transition can be performed recursively. For example, in the figure below, state 1 can continuously jump forward without inputting any symbols.
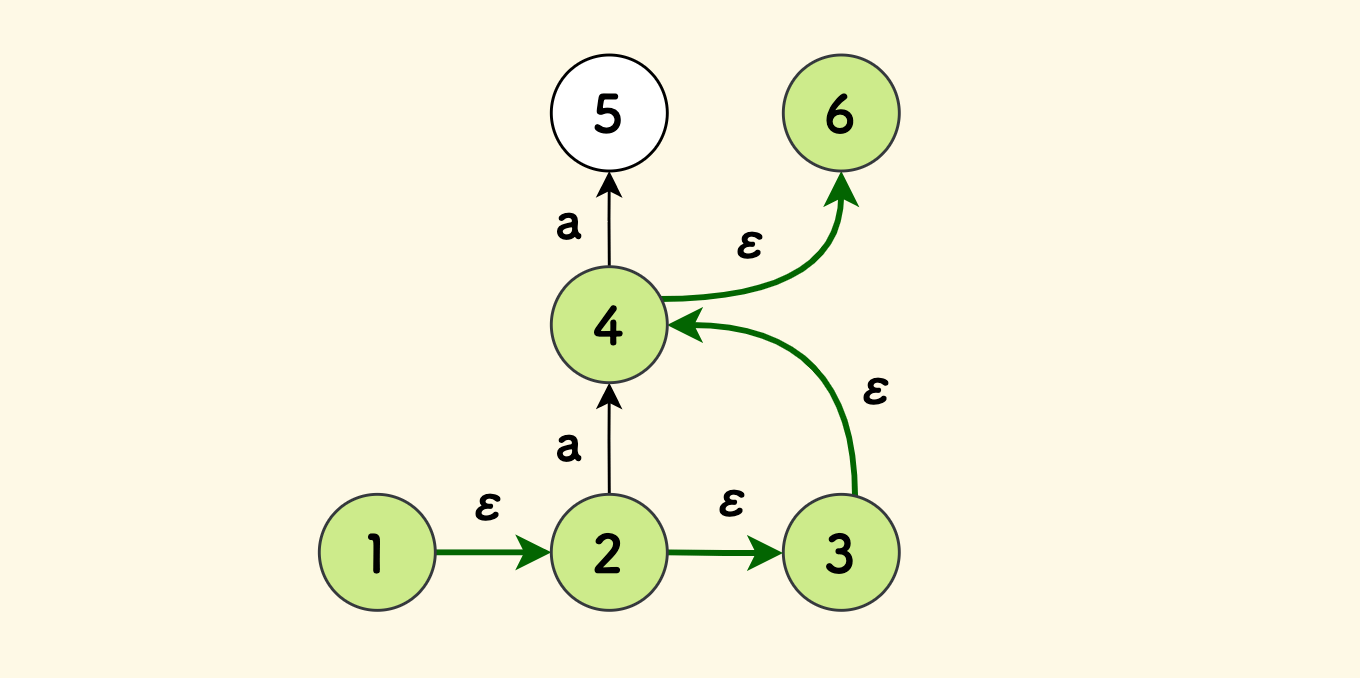
The NFA has only one start state, but can have multiple end states. However, designing the NFA structure to have only one end state simplifies the problem, because an NFA with multiple end states can be converted to an equivalent NFA with only one end state by adding empty edges.
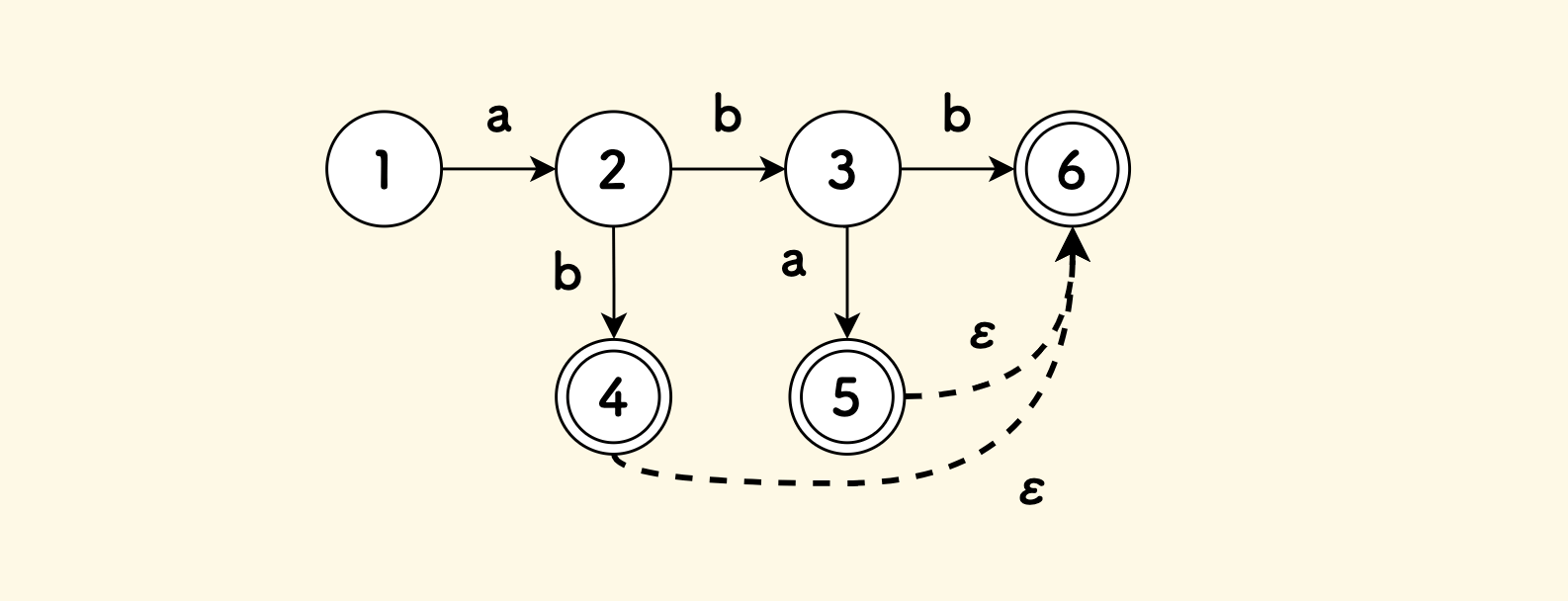
Code representation of Nfa state machine
class Nfa:
start: NfaState
end: NfaState
There are two key points in constructing an NFA from a regular expression:
- Use the double-stack method to parse the regular expression from the bottom up
- During the parsing process, continuously construct the NFA for different rules
This construction process will be implemented in a class called NfaParser.
Code structure of NfaParser
class NfaParser:
id: int = 0 # State counter
def parse(self, s):
# Parse the regular expression string and return an NFA
pass
First, define a basic method new_state to count the newly created states, which is convenient for giving the id field an initial value when creating a new NfaState.
NfaParser's new_state method
def new_state(self, is_end):
self.id += 1
return NfaState(self.id, is_end)
Next, let’s see how to handle each regular expression rule in turn.
Each regular expression is backed by an NFA, and regular expression operators are used to combine and transform these NFAs by adding empty edges.
First, a simple input symbol
acan be expressed as the simplest NFA, where state2is the final state:
Pseudo-code for constructing an NFA from a single input symbol
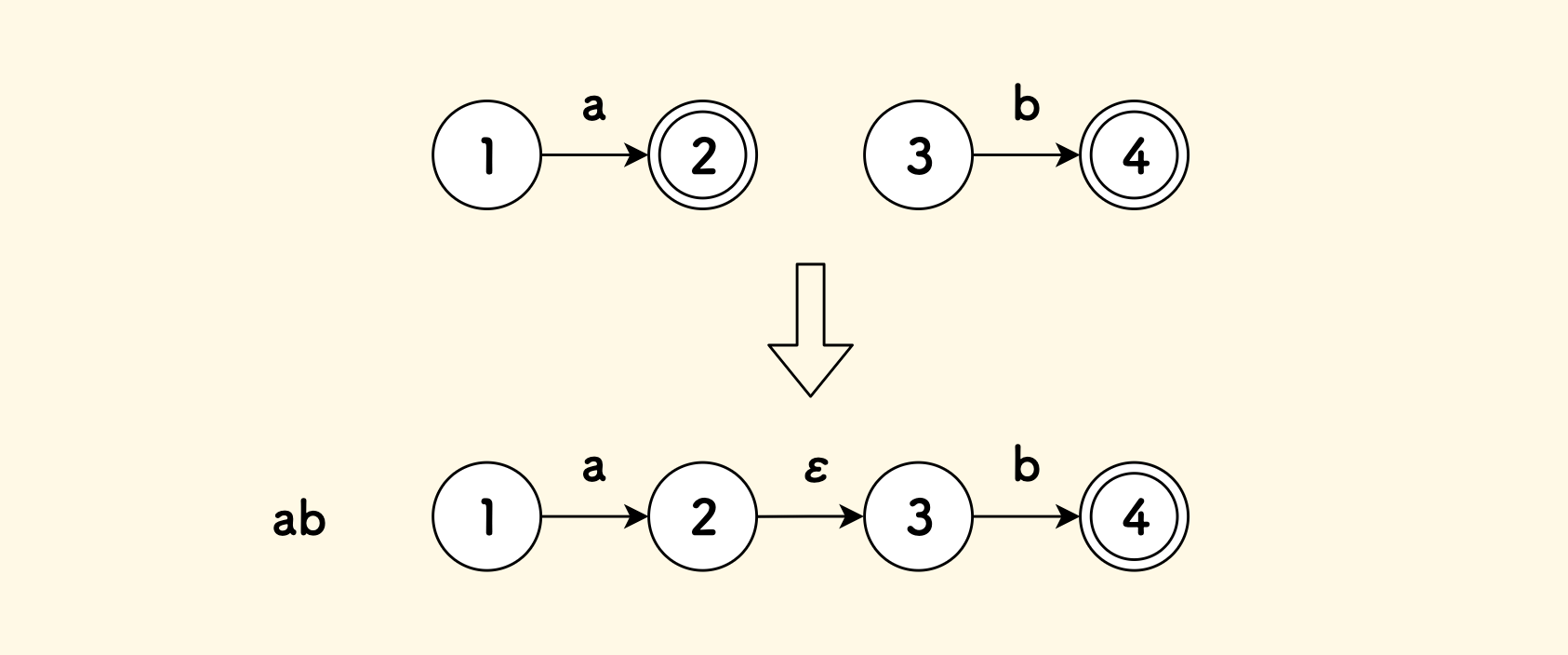
def create_nfa_from_symbol(self, ch): start = self.new_state(False) end = self.new_state(True) start.add_transition(ch, end) return Nfa(start, end)For the concatenation operator,
abcan be expressed as the concatenation of two NFAs,aandb:
Pseudo-code implementation of concatenation operator nfa_concat
def nfa_concat(self, a, b): # Add an empty edge transition 2->3 a.end.add_transition(epsilon, b.start) return Nfa(a.start, b.end)For the or operator,
a|bcan be expressed as the parallel connection of two NFAs,aandb:
Pseudo-code implementation of or operator nfa_union
def nfa_union(self, a, b): start = self.new_state(False) # 5 end = self.new_state(True) # 6 start.add_transition(epsilon, a.start) # 5->1 start.add_transition(epsilon, b.start) # 5->3 a.end.add_transition(epsilon, end) # 2->6 b.end.add_transition(epsilon, end) # 4->6 return Nfa(start, end)For Kleene closure,
a*can be expressed as:
Pseudo-code implementation of Kleene closure nfa_closure
def nfa_closure(self, a): start = self.new_state(False) # 3 end = self.new_state(True) # 4 a.end.add_transition(epsilon, a.start) # 2->1 start.add_transition(epsilon, a.start) # 3->1 a.end.add_transition(epsilon, end) # 2->4 start.add_transition(epsilon, end) # 3->4 return Nfa(start, end)Similarly,
a?can be expressed as:
Pseudo-code implementation of nfa_optional
def nfa_optional(self, a): start = self.new_state(False) # 3 end = self.new_state(True) # 4 start.add_transition(epsilon, a.start) # 3->1 a.end.add_transition(epsilon, end) # 2->4 start.add_transition(epsilon, end) # 3->4 return Nfa(start, end)a+is very simple and can be directly expressed asaa*:Pseudo-code implementation of nfa_plus
def nfa_plus(self, a): return self.nfa_concat(a, self.nfa_closure(a))For character range syntax sugars such as
[0-9a-z], it actually creates an NFA with multiple edges:Pseudo-code implementation of create_nfa_from_ranges
def create_nfa_from_symbols(self, chs): start = self.new_state(False) end = self.new_state(True) if chs: for ch in chs: start.add_transition(ch, end) else: start.add_transition(epsilon, end) return Nfa(start, end) def create_nfa_from_ranges(self, ranges): chs = set() for r in ranges: start, end = r for x in range(ord(start), ord(end) + 1): chs.add(chr(x)) return self.create_nfa_from_symbols(chs)




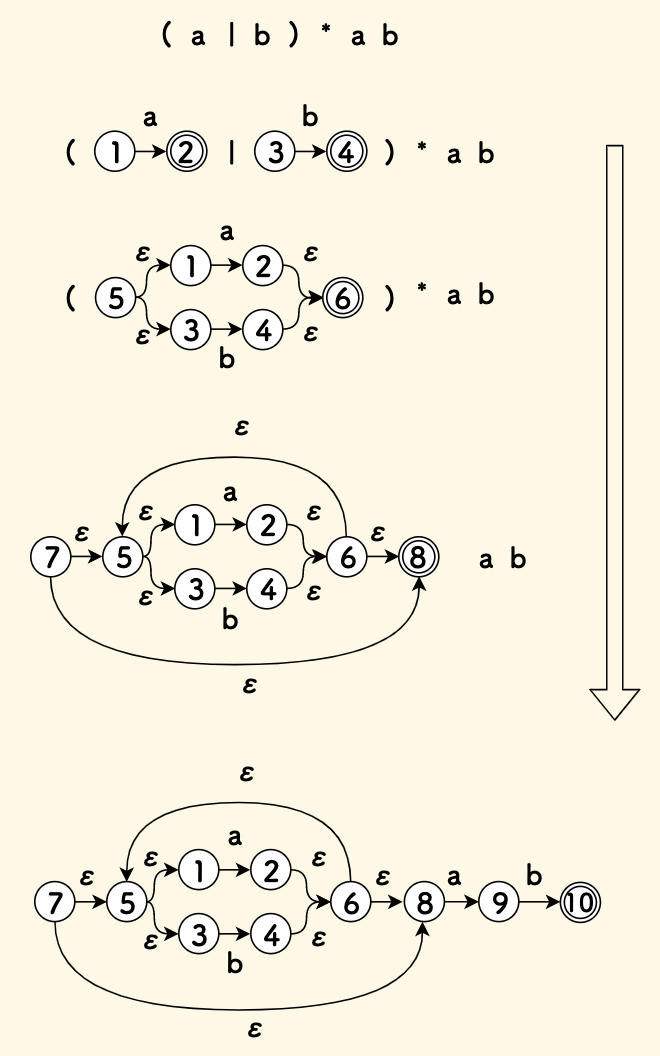
Let’s take an example, such as the expression (a|b)*ab. The process of evolving it step by step into the final NFA state machine is shown in the figure below:
The question now is, how to parse the regular expression string?
This is a parsing process, and the dijkstra double-stack algorithm will be used. It was created for parsing arithmetic expressions, but it also applies to parsing any expression with operator precedence relationships.
The double-stack method is essentially a bottom-up shift-reduce parsing process.
The double stack means that one stack stores the generated NFA state machine, and the other stack stores operators (such as |, *, etc.).
The parsing process has two actions:
- shift action: push the newly constructed NFA or operator onto the corresponding stack
- reduce action: if the time is right, pop the top operator and the corresponding number of NFAs from the stack and perform the calculation. The calculation is the functions mentioned above, such as
nfa_union,nfa_concat, etc.
The reason for using a stack is that there are precedence relationships between operators, and there are cases where you need to wait and then reduce. The reason for using two stacks is that we want to constantly examine the operator at the top of the stack. If only one stack is used, it will be inconvenient if the top of the stack is not sure whether it is an NFA or an operator.
Still taking (a|b)*ab as an example, its shift-reduce parsing process is shown in the figure below, where:
- When encountering characters
a,b, apply thecreate_nfa_from_symbolfunction to get the new NFA and push it onto the stack. - Calculate
(a|b): Pop the NFAs ofaandband the operator|from the stack, apply thenfa_unionfunction to get the new state machinep, and push it onto the stack. - Calculate
p*: Poppand the operator*from the stack, apply thenfa_closurefunction to get the new state machineq, and push it onto the stack. - Calculate
qa: Pop the NFAs ofqandafrom the stack, apply thenfa_concatfunction to get the new state machiner, and push it onto the stack. - Thus, further apply the concatenation rule to reduce
rbto the state machines, which is the final result.
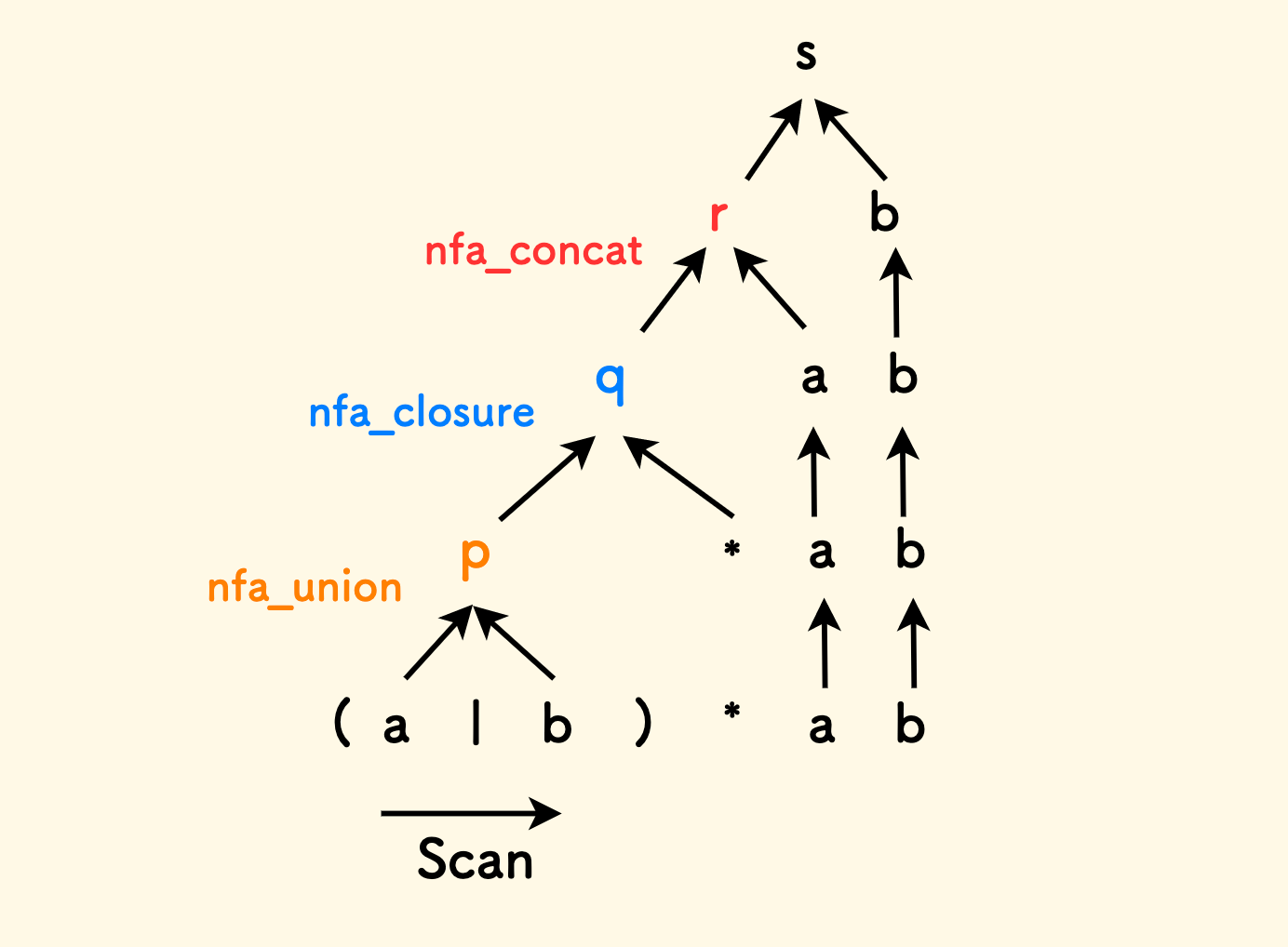
From this example, we can see that shift-reduce is a bottom-up parsing process, shifting to the right and reducing upwards.
Detailed process of the parsing algorithm:
- Define two stacks: one for storing NFAs and the other for storing operators
Define the sub-process for calculation:
Pop the top operator and pop the corresponding number of NFAs, and push the result onto the stack after calculation.
For example, for the operator
|and the operator*:def calc(self, nfa_stack, op_stack): op = op_stack.pop() if op == '|': b = nfa_stack.pop() a = nfa_stack.pop() nfa_stack.push(self.nfa_union(a, b)) elif op == '*': a = nfa_stack.pop() nfa_stack.push(self.nfa_closure(a)) # Other operator cases...From left to right, each time a character
chis scanned:If a non-operator character is encountered, use the
create_nfa_from_symbolfunction to construct a new NFA and push it onto the stack.The same is true for range syntax sugars, but the
create_nfa_from_rangesfunction is applied.If an operator is encountered, whether or not to reduce depends on the precedence relationship:
If the top operator of the stack has higher priority, then calculate first, then push onto the stack.
First calculate the top of the stack until the priority of the top of the stack is lower than the current operator; then push the current operator onto the stack.
Otherwise push onto the stack first, and wait for the opportunity to calculate later.
The code is as follows:
while precedence(op_stack.top()) >= precedence(ch): calc(nfa_stack, op_stack) op_stack.push(ch)- If a left parenthesis is encountered, push it directly onto the operator stack to wait for the right parenthesis to close.
If a right parenthesis is encountered, continuously pop from the stack for calculation until the left parenthesis is popped.
The code is as follows:
while op_stack.top() != ')': calc(nfa_stack, op_stack) op_stack.pop() # Discard the left parenthesis
- Finally, there should be only one element left in
nfa_stack, which is the calculation result.
There are some details to note here:
The concatenation operator of regular expressions actually has no “real body”. We can pre-process the regular expression in advance, which is equivalent to defining a symbol for it, such as
&.For example,
(a|b)*abcan be pre-processed into(a|b)*&a&b, which makes the parsing process easier.- In practice, the situation of escape characters must also be considered. For specific processing, please refer to the processing in the code implementation link at the end of the article.
- The timing of calculation does not consider the situation when the input ends. There may be operators and NFAs remaining in the stack to be calculated when the input ends. Then, after the input ends, check whether the operator stack is non-empty and calculate it.
So far, we can convert a regular expression into a non-deterministic finite automaton NFA.
Converting an NFA to a DFA ¶
For DFA states, there can be at most one possible target transition state under the same input symbol. Therefore, the structure design of DfaState is as follows:
Code representation of DfaState
class DfaState(State):
# Transition table, { Char => Target State }
transitions: dict[C, DfaState] = {}
The DFA state machine has only one start state and can have multiple end states, so its structure is designed as:
Code representation of Dfa state machine
class Dfa:
start: DfaState
# The set of all states, convenient for matching functions to use
states: set[DfaState]
If you don’t mind the time overhead of matching NFA compared to DFA, we can use only the NFA parsed in the first part to match strings. Since the state of the NFA can reach multiple target states under the same input character, we need to check every possible transition path. In addition, since there are empty edges, we need to recursively find all possible target states along the empty edges forward.
Both of these points cause a problem: NfaState has non-unique target states under the same input. This is also the reason why matching with NFA is slower than matching with DFA.
Subset construction deals with this problem, and its approach is:
- All states reachable from a state are added to a set and used as a new state in the DFA.
- In the presence of empty edges, continuously add the states passed along the empty edges to this set.
In this way, there will be two effects:
- The transitions between sets become unique.
- Eliminates empty edges.
In other words, this constructs a DFA.
It is worth noting that NFA can always be converted into a DFA with equivalent capabilities. Subset construction is universal and is not limited to the regular expression scenario.
The subset construction process is illustrated with an example. The left side of the figure below is the NFA, and the right side is the constructed DFA:
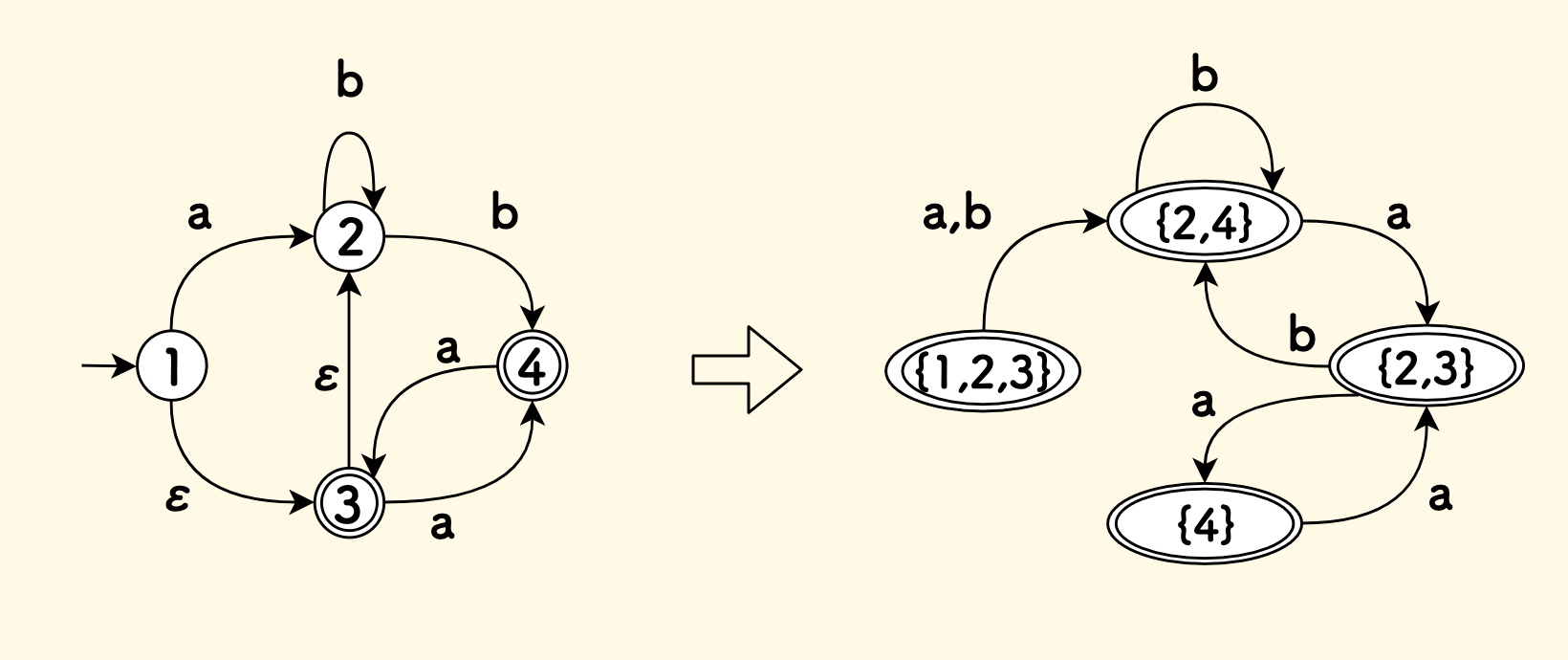
- At the beginning, construct a set
{1}with the initial state itself, recursively search for reachable states along the empty edges, and add states2and3to get{1,2,3} Examine all non-empty outgoing edges of
{1,2,3}(that is, examine the non-empty outgoing edges of each state in the set):- For the character
a, the reachable states are{2,4}, and the expansion along the empty edges is still{2,4} - For the character
b, the reachable states are{2,4}, and the expansion along the empty edges is still{2,4}
- For the character
Examine all non-empty outgoing edges of
{2,4}:- For the character
a, the reachable state is{3}, and the expansion along the empty edges gives{2,3} - For the character
b, the reachable states are{2,4}, and the expansion along the empty edges is still{2,4}
- For the character
Examine all non-empty outgoing edges of
{2,3}:- For the character
a, the reachable state is{4}, and the expansion along the empty edges is still{4} - For the character
b, the reachable states are{2,4}, and the expansion along the empty edges is still{2,4}
At this step, no new set is generated, so it ends.
Finally, four new sets are obtained, and each set is a
DfaState.In addition, the set containing the final state is also the final state in the DFA.
- For the character
We can implement the process of converting NFA to DFA in a class called DfaBuilder.
In the example above, there are two main processes:
Each time you jump to a set, expand it along the empty edges.
We can call the set of states
Nafter continuous expansion along the empty edges theε-closure(N)ofN.To recursively expand along the empty edges, you can use the depth-first method. The code is shown below:
Pseudo-code implementation of epsilon_closure function
def epsilon_closure(self, N): # Recursively expand the NfaState set in place along the empty edges # Push all NfaState in N onto the stack stack = [] for s in N: stack.push(s) # DFS depth-first traversal while stack: s = stack.pop() # Along the empty edges, find all reachable states and add them to the set for t in s.transitions[epsilon]: if t not in N: N.add(t) # Push onto the stack stack.push(t)If a new set is generated, add it to the processing queue.
The main construction process is:
- At the beginning, construct the starting set
{1}with the initial state of the NFA For each possible non-empty character outgoing edge, examine the set of reachable states. This transition action is called the
movefunction:Pseudo-code implementation of move function
def move(self, S, ch): # move(S, ch) returns the target state jumped to from state S through the non-empty edge ch N = self.d[S.id][ch] self.epsilon_closure(N) # Expand along the empty edges id = self.make_dfa_state_id(N) if id not in self.states: # If it has already been generated, return and do not create a new one self.make_dfa_state(N, id=id) return self.states[id]One detail is that if a set (or
DfaState) already exists, do not create a new one.- If the target set reached by
movehas not been processed, add it to the processing queue.
This processing process is breadth-first, and the code can be implemented as follows:
Pseudo-code implementation of DfaBuilder's main process for constructing DFA
def build(self):
# Initial state: the entire closure reachable from the starting state of the NFA along the empty edges
N0 = {self.nfa.start}
self.epsilon_closure(N0)
S0 = self.make_dfa_state(N0)
# q is the queue to be processed, first-in-first-out, which is breadth-first
# The so-called "processing" is to fill in the transition table of non-empty edges for each DfaState S
q = [S0]
# q_d is the ID of all states already in the queue
# If it has already been added to the queue, there is no need to add it again
# Actually q is a unique queue
q_d = {S0.id}
# The DFA to be built finally
dfa = Dfa(S0)
while q:
# Pop a state S to be processed
S = q.pop(0)
q_d.remove(S.id)
# For each possible **non-empty** transition edge ch
for ch in self.d.get(S.id, {}):
# Jump into another state T
T = self.move(S, ch)
# Record the transition edge
S.add_transition(ch, T)
if T not in dfa.states:
if T.id not in q_d:
# T is not marked, add it to the queue
q.append(T)
q_d.add(T.id)
# S has been processed and put into dfa
dfa.states.add(S)
return dfa
Finally, the process of constructing the DFA from the NFA obtained by parsing the regular expression (a|b)*ab earlier is shown in the figure below. NfaState that are in the same set in each step of this graph will be colored green. It can be seen that the DFA equivalent to this expression contains only three states.
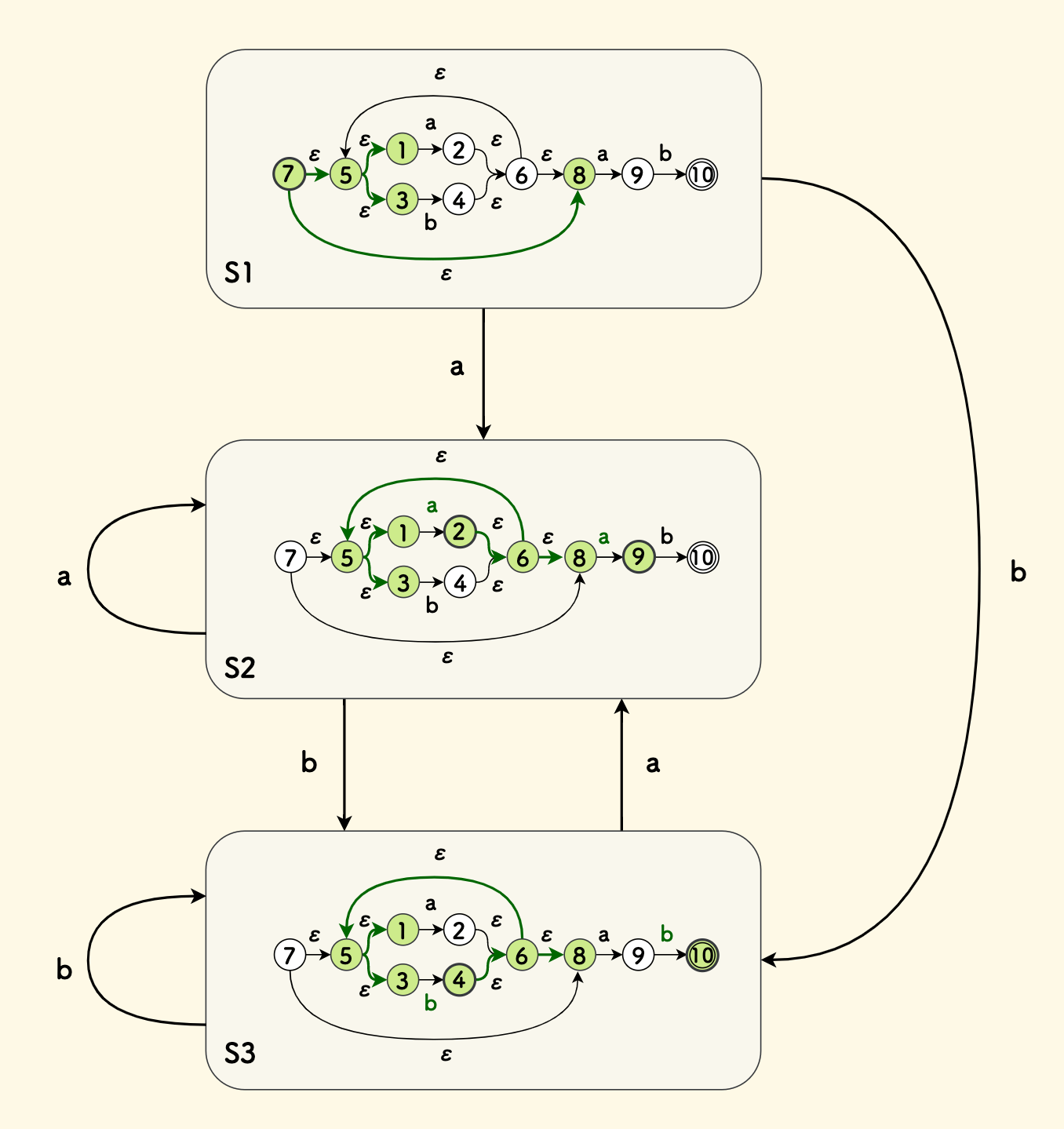
So far, we can convert a regular expression to a DFA, and we can also write a matching function: Continuously input characters, jump states according to the input characters, and if you reach a final state when the input ends, it means the match is successful.
DFA matching function match
class DFA:
def match(self, s: str):
st = self.start
for x in s:
if x not in st.transitions:
return False
st = st.transitions[x]
return st.is_end
Simplifying a DFA ¶
Finally, how to minimize the number of states of a DFA?
There are three things we can do:
- Clean up dead states, that is, remove non-final states that have no outgoing edges.
- Clean up unreachable states.
- Merge equivalent states.
The first two points are very easy to understand and will not be discussed further.
The third point uses the Hopcroft DFA minimization algorithm. This algorithm is very clever:
- First, assume that all states of the DFA are divided into two groups, for example, divide all final states into one group and the others into another group.
In each group, find the states that can be “distinguished” and perform the split.
The key to distinguishing is: if for a certain input character, the target transition states of the two states are not in the same group, then these two states should not be in the same group, and this group should be split.
- Repeat step three continuously until there is no more splitable situation. These groups constitute the final minimized DFA.
Let’s look at an example:
Initially, all states are in one group. The left side of the figure below is the original DFA, and the right side is the grouping situation.

First, split the final state
Eout, forming two groups{A, B, C, D}and{E}.The group
{E}has only one state member, so there is no need to consider splitting.- Examine each state of the group
{A, B, C, D}in turn, such asA. - Then examine each input character
aandbin turn. - If there is a situation where the target state of a state and the target state of
Aare not in the same group, collect them. All such states constitute a new group and are split out.
In the figure below,
Djumps toEwhen characterbis input, which is not in the same group as the target state ofA, so split{D}out.
- Examine each state of the group
With the same idea, we can split
{B}from{A, B, C}:Examine states
AandC, and the target states reached are all in group{A, B, C}.But state
Breaches target stateDin group{D}when input characterb.
There are currently four groups. Following the same idea, no more splitable situations can be found. So the algorithm ends.
These four groups are the four states of the final new DFA.

While the state simplification ends, the transition relationship needs to be maintained.
You only need to fill in the transition relationship between their groups according to the original transition relationship between
DfaState: if the original stateAcan reach stateBthrough edgea, add an edgeabetween the groups they are in.In addition, the group containing the final state is also the final state in the new DFA.
The simplified DFA finally obtained in this example is shown in the figure below:






Finally, let’s analyze the code implementation.
The process of simplifying the DFA is implemented in a class called DfaMinifier:
At the beginning, initialize to two groups.
Continuously execute the
refinefunction to split until it cannot be split.DfaMinifier's main process minify function
class DfaMinifier: dfa: Dfa # The original DFA to be simplified def minify(self): # All final states are in one group g1 = self.make_group({s for s in self.dfa.states if s.is_end}) # Other states are in one group g0 = self.make_group(self.dfa.states - g1) # Initially divided into two groups gs = {g0, g1} # Continuously split until it cannot be split while self.refine(gs): pass # Rewrite DFA self._rewrite_dfa(gs)The
refinefunction is responsible for checking whether each group can be split and executing the split.refine Function code implementation
def refine(self, gs): for g in gs: # Check each group for a in g: # Find the set of states different from a in the group g2 = self.find_distinguishable(g, a) if g2: # Execute the split g1 = self.make_group(g - g2) # Add a new group and remove the discarded group gs.remove(g) gs.add(g1) gs.add(g2) # A split occurred return True # No split occurred return Falsefind_distinguishableis a sub-process of therefinefunction, responsible for collecting states “different” from the given state, to form a group that can be split out:find_distinguishable Function code implementation
def find_distinguishable(self, g, a): # Find the set g2 of all other states b that are not equivalent to a in group g # If it does not exist, the empty set is returned x = set() for ch in a.transitions: # For the case where a has an outgoing edge, examine the target state reached by each outgoing edge ta = a.transitions[ch] # Check each other state b in the same group for b in g: if b != a: # tb is the target state of b under this symbol, note that it may be None tb = b.transitions.get(ch, None) if tb is None or self.group(ta) != self.group(tb): # The groups where the target states are located are different, record it x.add(b) if x: # For an outgoing edge, you can distinguish it, so break directly break return self.make_group(x)
Finally, the process of regenerating a DFA is relatively simple and will not be expanded.
Code Implementation ¶
The complete code implementation is placed on github:
- Implementing a Simple Regular Expression Engine Python Version
- Implementing a Simple Regular Expression Engine C++ Version
Update @2023-09-03:
I implemented a C++20 compile-time regular expression engine: compile_time_regexp.hpp
(End)
Please note that this post is an AI-automatically chinese-to-english translated version of my original blog post: http://writings.sh/post/regexp.
Related reading:
- Arithmetic Expression Evaluation (Double-Stack Method)
- Automaton Verification of Floating-Point Number Strings (DFA & NFA)
Original Link: https://writings.sh/post/en/regexp