本文是我对系统设计的一些思路和方法,源于个人经验的一个整体性总结。
这篇文章会很长、很长,如果你比较着急,可以只看高亮的文字,或者直接挑选感兴趣的章节。
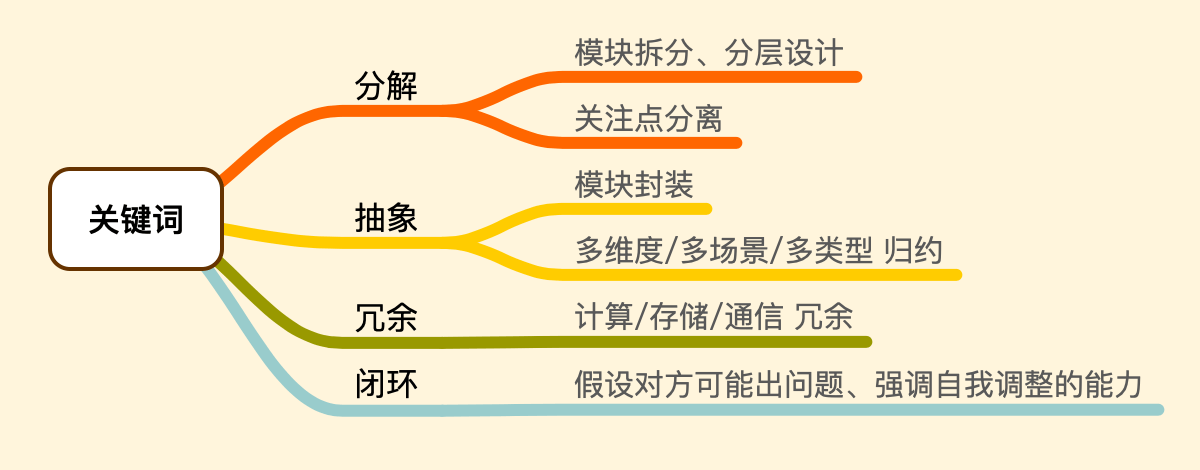
关键词 ¶
简单性和模块化是软件工程的基石,分布式和容错性是互联网的生命。
系统设计中的思维和方法,我认为可以提炼出 四个关键词:分解、抽象、冗余 和 闭环。
意识 ¶
2022 年写过的一篇相关文章:《系统设计中的心态和意识》。 这里再提其中四点:
- 设计先行:强调 先想后做,设计是方向性问题、其重要性甚至高于实现。
- 保持简单:设计者每增加一份复杂度,都应该反问自己其必要性。简单的系统更可靠、易扩展。
- 闭环思维:每个模块自身的 能力 和 错误 不要外溢。错误不可避免,重点是自我调整的能力。
- 开放重构:重构点总是会积累的,日常局部重构有益。好的模块设计下,局部重构完全可能。
技术方案 ¶
对于简单的需求,理清思路即可。稍复杂的,则需要做一份技术方案。
可由以下几个部分组成,不必给出所有,要视需求而定、因地制宜:
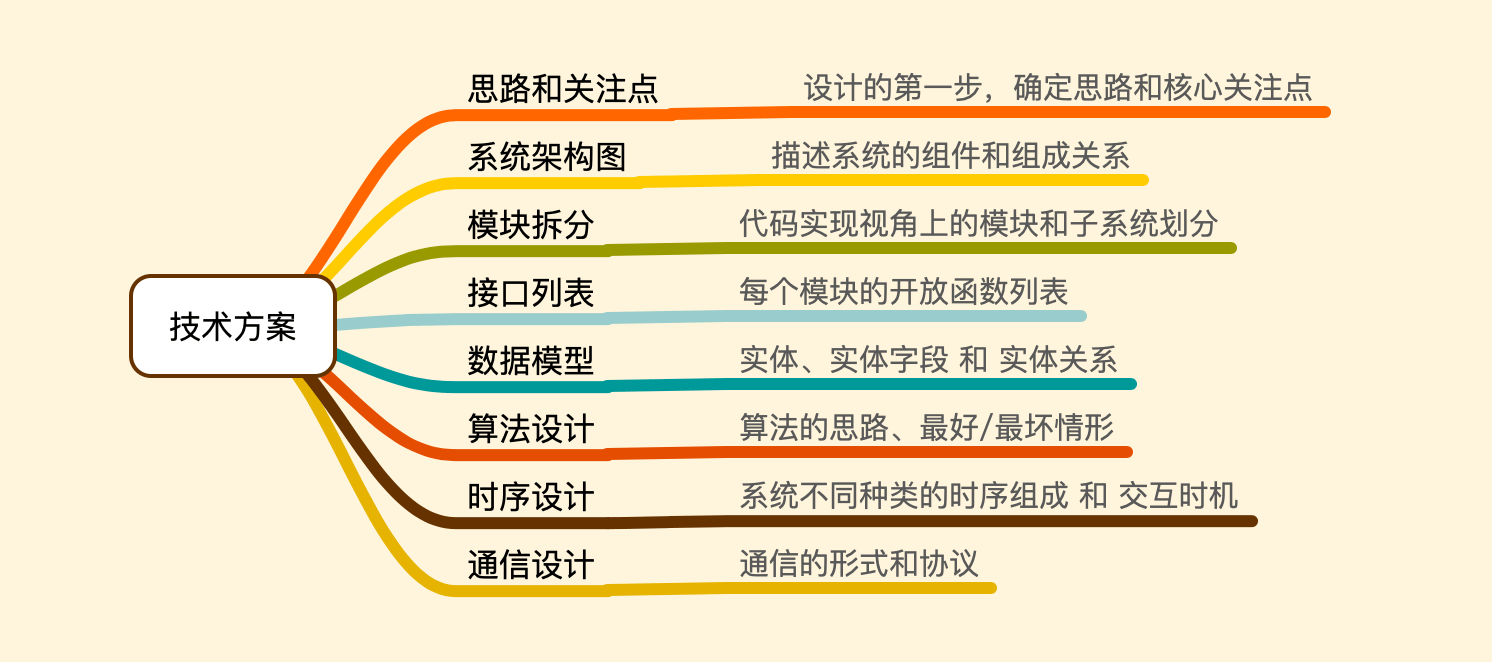
其中的每一项会在接下来的几个章节中细化说明。
系统关注点 ¶
系统的关注点可分为 功能性的 和 非功能性的(扩展性、一致性、性能)等。 非功能性关注点也是足够重要的,甚至会决定系统的整体设计。 互联网的世界中,人们总提倡「性能后面再优化、先跑起来再说」,但是在一些实时系统中, 比如在一些帧驱动的系统中,所有计算都要在十几毫秒内全部完成,性能是一个刚性限制,必须是在最开始就要考虑的因素, 否则后面的性能问题可能会引发重构。
一个例子,在一个库存管理系统中,转移库存是其最基础的能力,就是把一批库存从一处挪动到另一处,那么要考虑的关注点可以有:
- 原子性:批量的库存转移 要么全部成功、要么全部失败。
- 可回溯、可回滚:可以完全还原库存转移时的情况(事前库存、数量、事后库存)。
- 一致性:一方库存减少、另一方必须相应地增多同样的数量。
综合以上关注点,可以采用「复式记账」的思路,来达到类似「事务」的效果,同时要考虑对并发加锁 以及 锁过期 等问题。 总而言之,这个例子意在说明,理清「关注点」应该是系统设计的第一步,这样才可以进一步倒推后续的具体设计。
时序的概念 ¶
何为时序?
在分布式系统的模型中,进程内的事件顺序可直接由时钟确定,进程间的事件顺序则必须依靠通信。 下图中,可以确定先后顺序的有 e1 → e2 和 e1 → e3 → e4,但是 e2 和 e3, e4 之间的顺序都是无法确定的,也就是并发的。
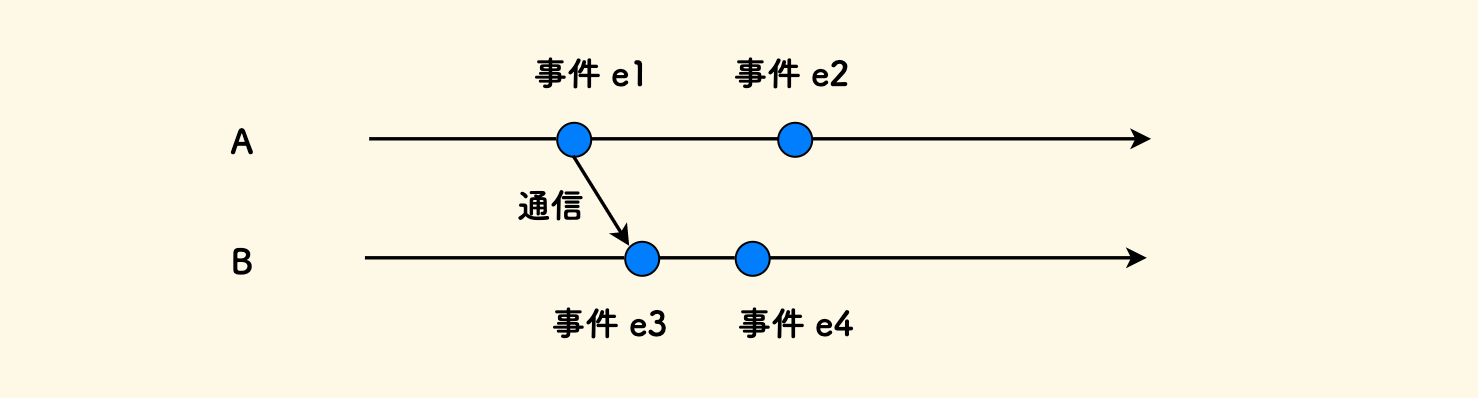
时序是一个概念,而非具体技术,就相当于逻辑上的「进程」,实际中可以是 进程、线程、或者协程, 只要一个过程可以独立拥有一根不依赖外部的时间线,就算作一个时序。 两个时序之间是在逻辑上是并发的。
在系统设计中,对于多时序系统,有必要给出:
- 系统包含几种时序 以及 每种时序负责的事情。
- 重点场景下时序之间的交互关系。
时序设计中蕴含着程序将如何部署和运行。比如在 k8s 中一个 Pod 就是一个时序,一个 Deployment 就是一种时序。 另外一个有趣的点是,因为 Goroutine 的强大存在,Golang 中多时序的程序设计变的非常简单。
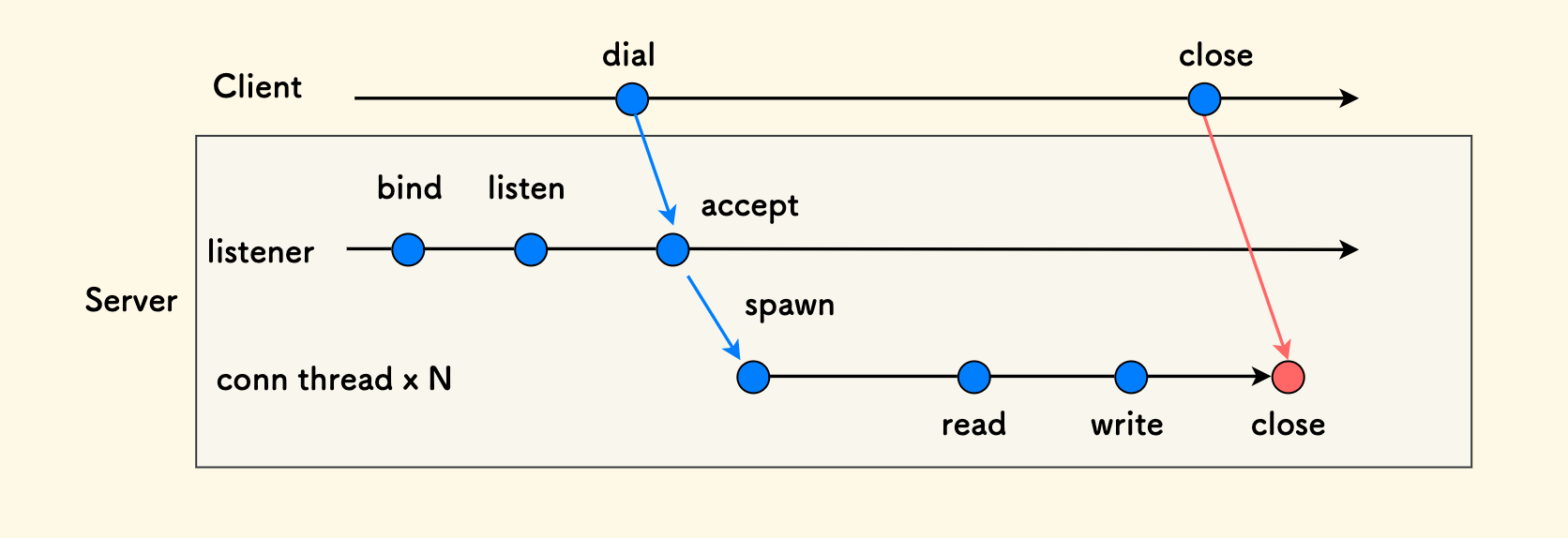
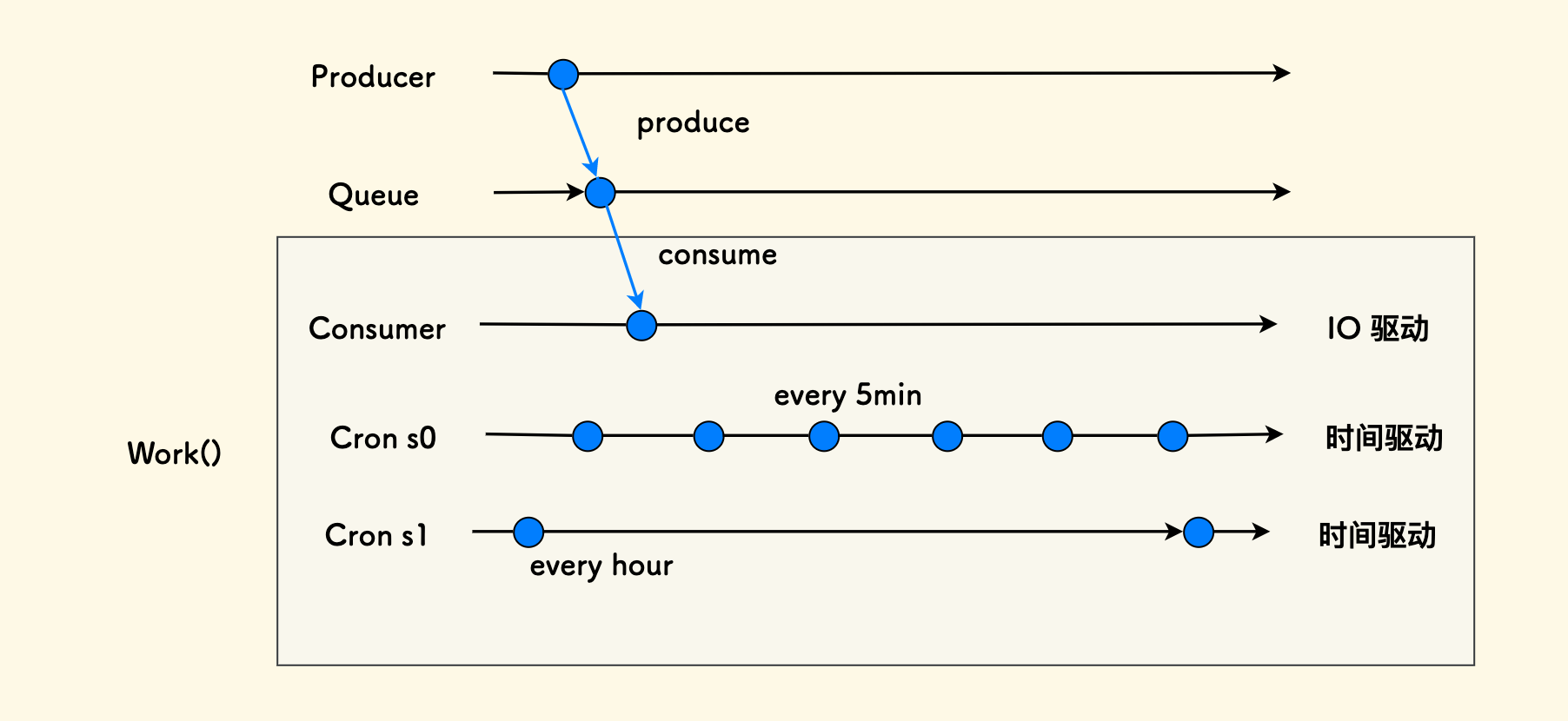
举一个时序图的例子,在一个典型的多线程实现的 TCP Server 中,主线程每建立一条新的连接,它都会创建一个子线程来负责这条连接的读写。 其时序图如下:
关于时序的「驱动方式」,我自己总结了常见的两类:
- 时间驱动的 (cronjob、ticking 循环 等)
- IO 驱动的(blocking 的读写线程等)
用代码来示意就是:
while ( time.sleep(n) ) { do ... } // 时间驱动的
while ( blocking read/write ) { do ... } // IO 驱动的
有人会说,IO 驱动本质上也是在「循环等待」,但是请注意,我们都是在概念上而言的。
我常采用一种 分离时序的方式,把同一个功能函数部署为两种不同的时序,比如说,对于异步业务处理而言, 可以划分为:
- Consumer 时序:即时处理一个,但容错要求低、失败时不必重试。
- Cronjob 时序:定时处理一批,作为补偿兜底、有重试能力。
不过由于功能相同,仍然可以做到只实现一个核心函数、只是部署上有所不同而已。 更进一步地,还可以继续划分多级 cronjob 实现阶梯化的补偿时效。
系统架构图 ¶
用来描述一个系统的所有部件和组成关系。
- 制图形式不重要、能表达清楚最重要。
- 相同的部件用同一种 颜色 和 形状 来表达。
- 部件间的关系最好按 层次化的树状结构 来表达,最好标注上 关系名称 和 通信形式。
- 复杂系统可以每个子系统一张架构图,但是最好要有一张总系统的组成图。
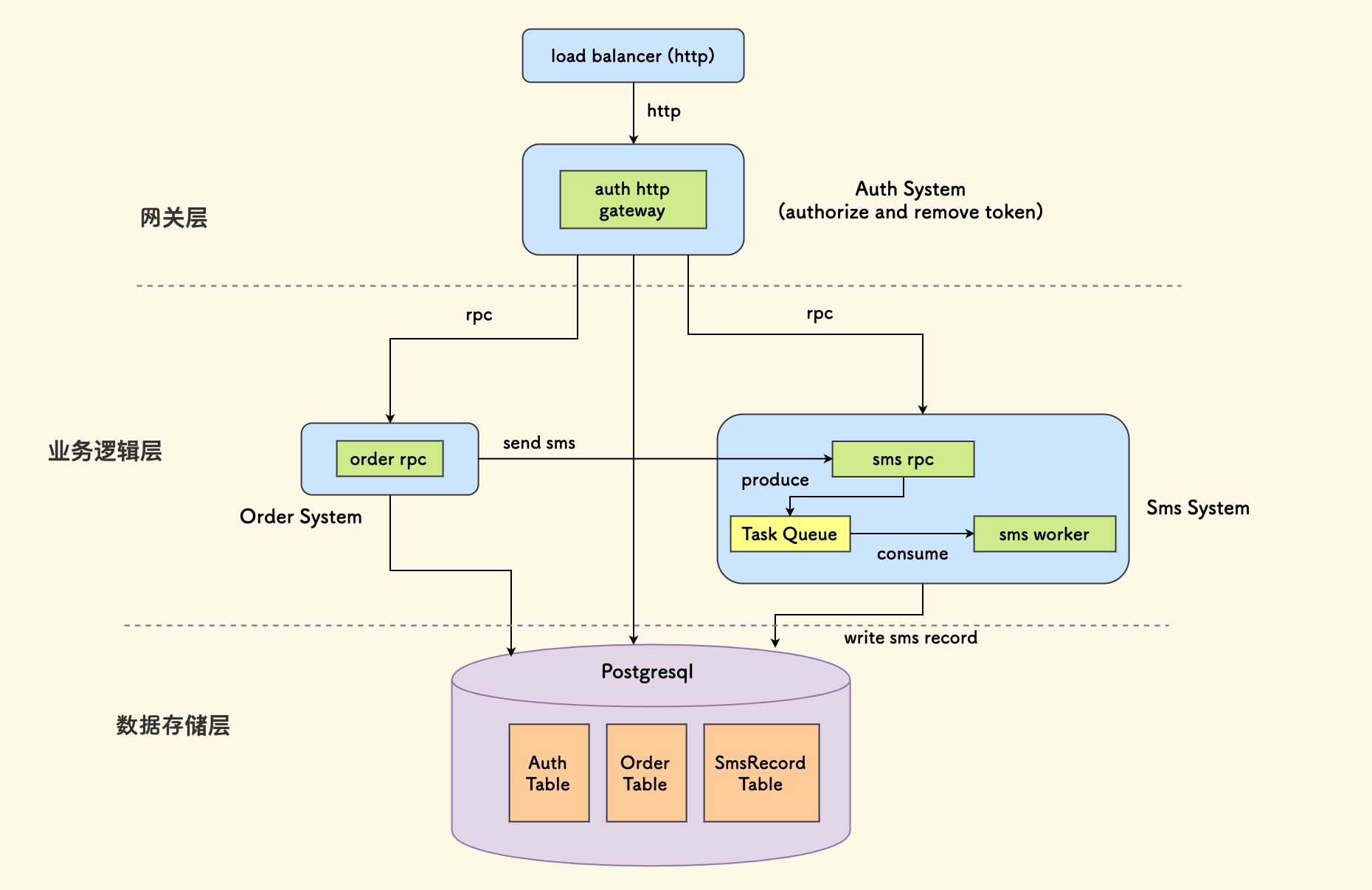
下面是一个简单的例图,从中可以看到以下信息:
- 总共分了三层:网关层、业务服务层 和 数据存储层。
- 外部请求经过七层负载均衡器进来,进入 Auth 服务。
- Auth 服务不仅剥离掉请求鉴权,而且是一个 HTTP 转 RPC 的网关。
- 再下一层有两个子系统:订单 和 短信。
- 短信子系统内部还存在两种时序:sms rpc 服务作为生产者、sms worker 作为消费者。
- 订单服务通过调用 sms rpc 服务来发短信、之后 sms worker 会去消费短信发送任务。
- 所有子系统的数据都分别存储在同一个 Postgresql 实例中的三张表内。
模块化 ¶
模块化是系统设计中最核心的概念之一,它基于前面所说的两个关键词:分解 和 抽象。
通俗的说,模块化的能力就是把事情分门别类整理的能力。
会有几个子章节:
设计的方向
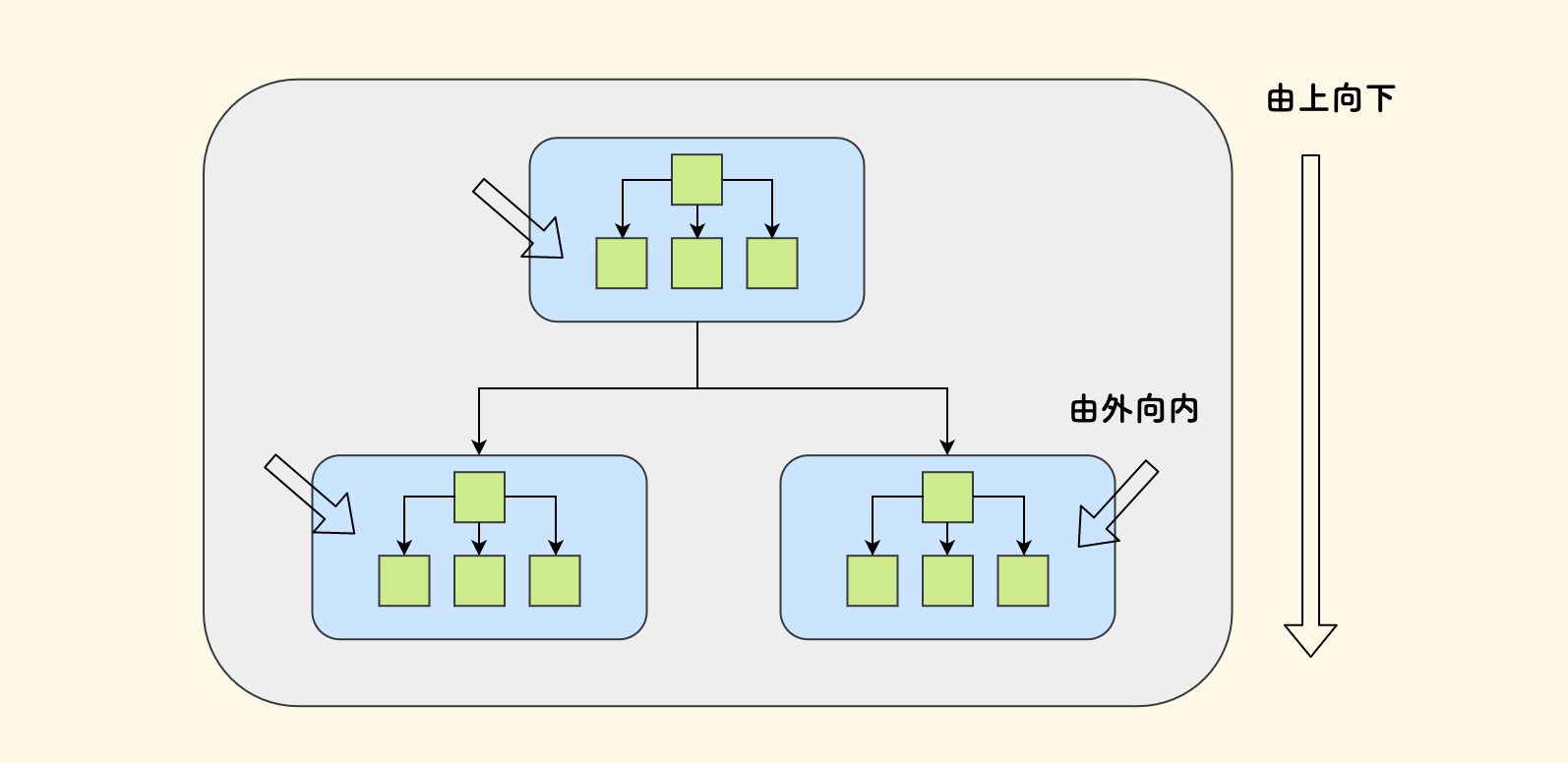
对于复杂的系统来说,应该 先做顶层设计、拆分子系统、按树状结构来做分层体系, 这样每个子系统在整体中扮演的角色才可以看的清楚。最后再逐个精细地设计各个子系统。
简而言之就是,设计的方向应该是由外向内、由上向下的。 如下图示意,先把整个系统拆解为几个蓝色的子系统,然后再具体设计每个子系统内绿色的具体模块。
模块拆分
我们这里所说的模块是概念上的,不限于某种编程语言的具体模块机制、可以是 函数、类、文件、目录、子系统 等。 我通常的做法就是 划分代码目录、组织成一个目录树。 这其中存在两种划分方式,横向拆分 和 纵向拆分:
- 通用的、薄的逻辑可以横拆放到一起。
- 纵深的功能可以纵拆成为一个单独的模块。
- 每一个模块都有其专注的话题。
- 不常变动的下沉、否则上浮。
有时直接做模块化是困难的,这一般源自对概念的分析不够清晰,解决的办法之一是理一张概念分层图。 把业务概念按照「谁理解谁」来搭积木,划分原则是,下层不理解上层、上层可以理解下层。 理出来概念之间的层次关系后,最终的模块划分就有了依据。
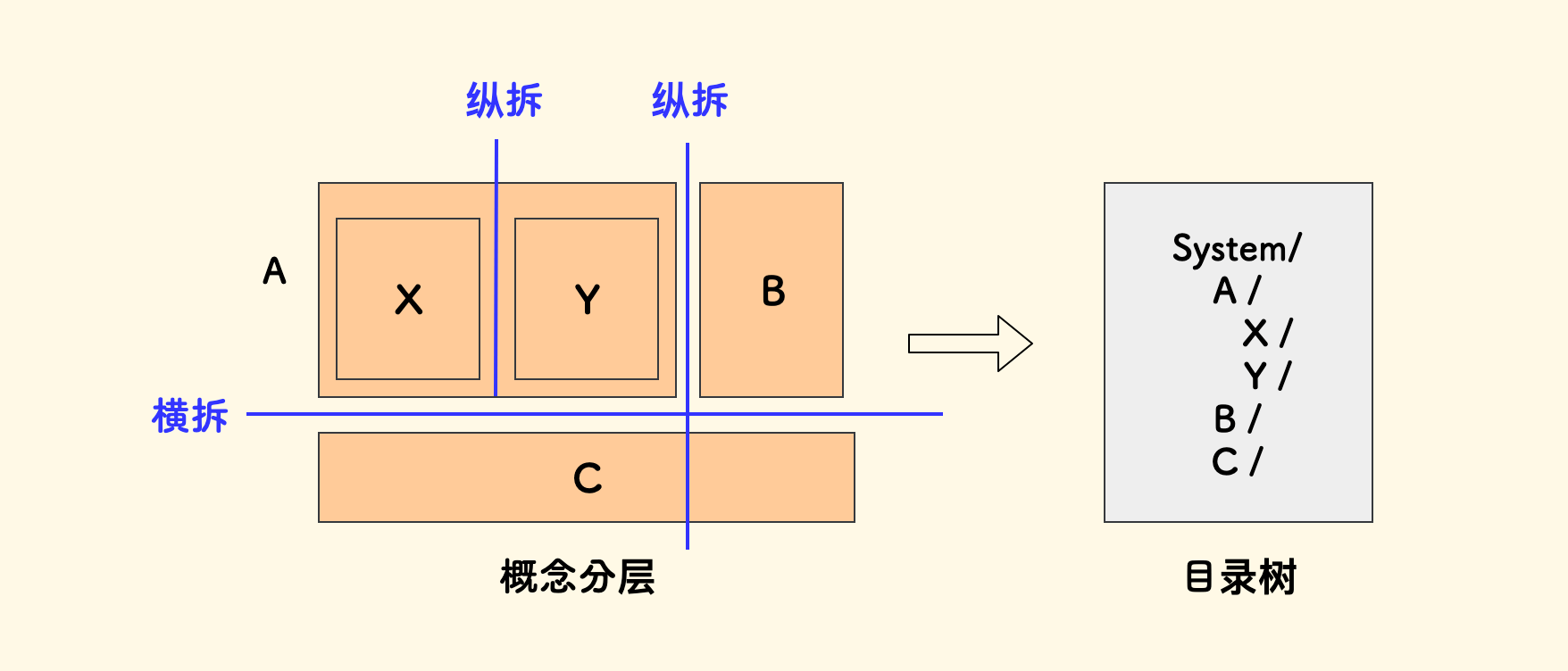
举一个例子,在典型的一个存在子母单的 和 拆单逻辑 的电商系统中,以 Python 语言为例,概念分层图如下:
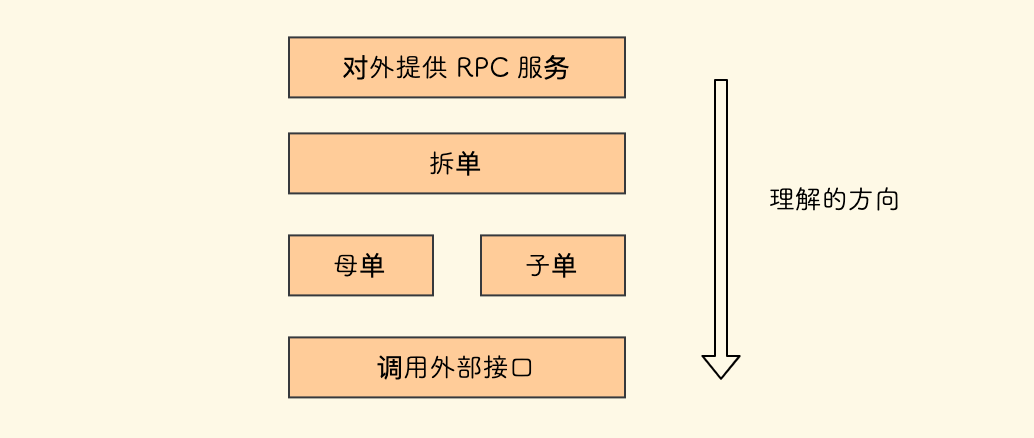
代码目录可以拆解如下:
order_system/
|- rpc_service/ // RPC 接口,胶水层 (横拆)
|- models/ // 存放数据表模型(横拆)
| |- order.py
|- clients/ // 外部调用封装 (横拆)
|- base/ // 基础函数封装 (横拆)
| |- order.py // 比如 create_order 等基础函数 (纵拆)
| |- sub_order.py // (纵拆)
|- splitor/ // 订单拆分子单的拆单器 (纵拆)
| |- algorithm.py // 拆解订单的算法实现
| |- split.py // 拆单器的实现
| |- consumer/ // 及时拆分订单的消费者
| |- cronjob/ // 补偿拆单的时序
面向对象中的类型继承树
在面向对象 OOP 设计中,类之间的关系也可以组织成一颗类型的继承树,也可看作一种模块划分。 下面是一个行为树中节点类的继承树的例子,其中每一个 Node 表示一个类,自上而下表示继承关系:
Node
|- SingleNode // 单孩子节点
| |-- DecoratorNode // 装饰器节点
|- CompositeNode // 组合节点
| |-- SequenceNode // 顺序组合节点
| |-- SelectorNode // 选择组合节点
| |-- ParalleNode // 并行组合节点
|- LeafNode // 叶子节点(无孩子)
| |-- ConditionNode // 条件节点
| |-- ActionNode // 行为节点
分层设计
计算机中分层设计无处不在,比如 OSI 七层模型。 这里再提一次 《通灵芯片》 中的名言:
计算机是以组成一个分层体系的部件构造的,每一个部件都重复多次。 要懂得计算机,你只要理解此分层体系就行了。
分层在系统设计中可以理解为,将拆分好的模块划分到不同的层次上、形成层次化的几类模块。
讲究的原则是:
- 上层可以理解下层,下层不理解上层。
- 下层对上层提供能力和服务支持、且对上层做好抽象隔离、屏蔽实现细节。
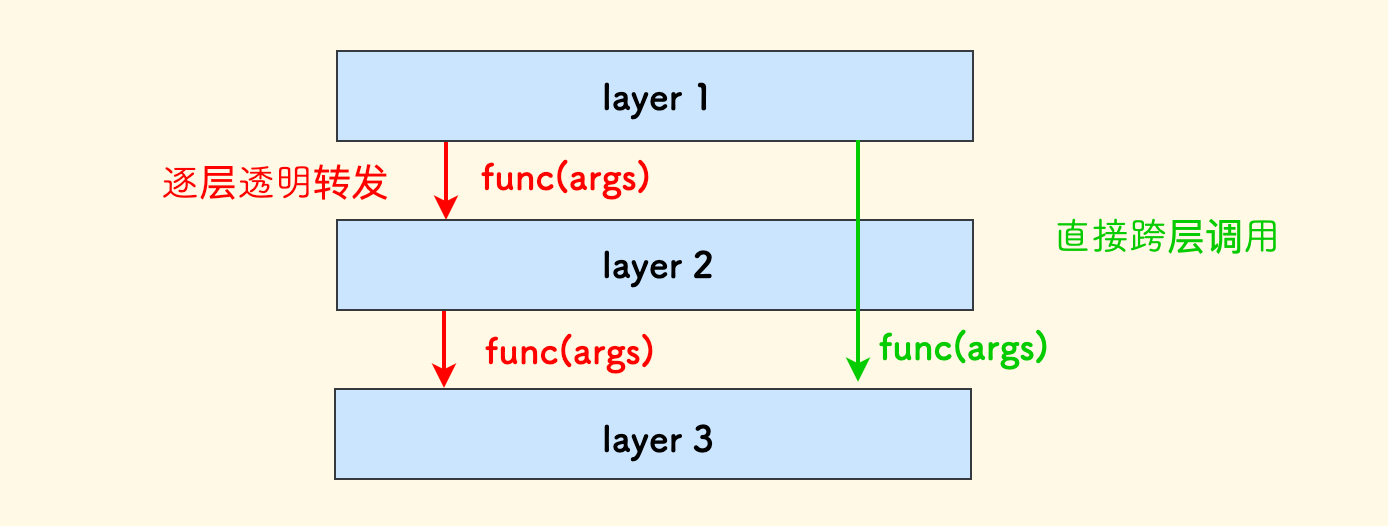
- 上层可以对下层进行跨层调用,同一层之间的调用也并无强限制(视情况而定)。
- 复杂性尽量下沉。
这个「下层不理解上层」的意思是说,下层模块中的代码不可以去直接调用上层模块中的代码。 原因是,下层是上层的依赖,如果下层去调用上层,就产生循环依赖了。
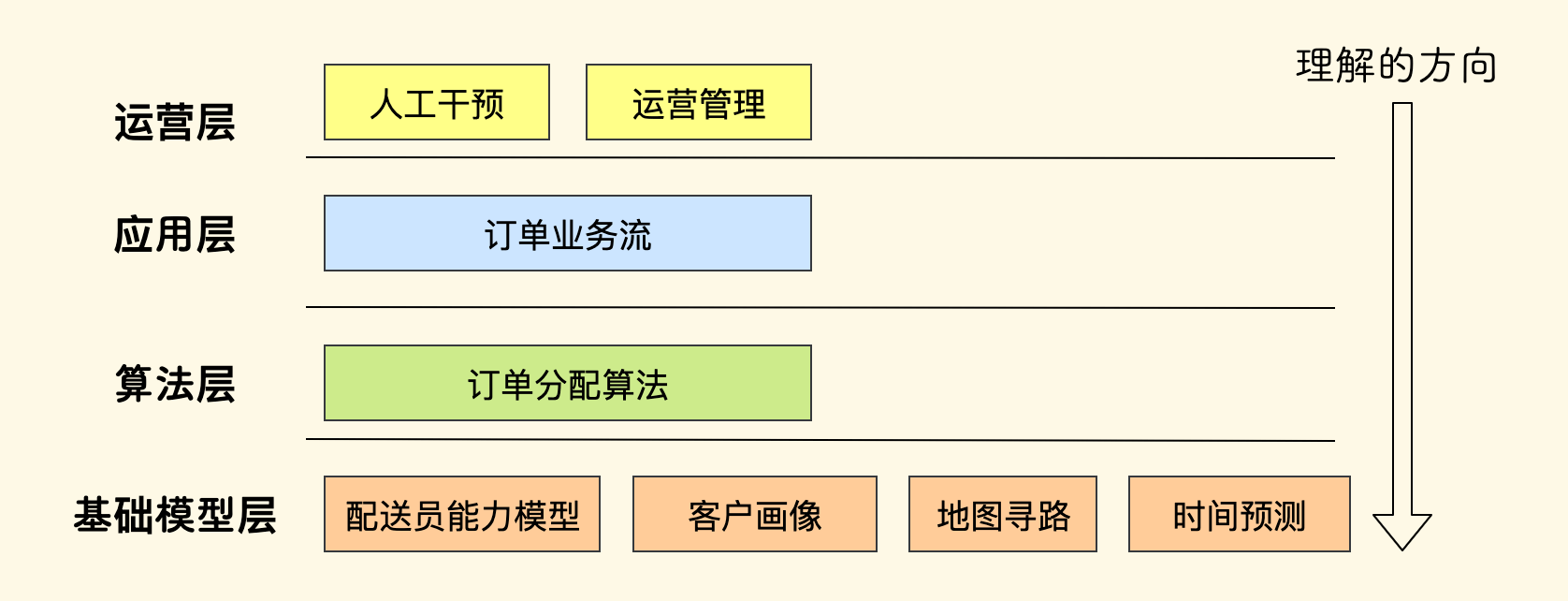
举一个例子,假如要设计一个简单的给配送员分配订单的系统,分层设计的示意图可以如下:
- 每一层都有一类专注的话题。
- 理解(依赖)的方向是自上而下的,下层不可逆向调用上层。
层次之间要做好概念的转化和抽象隔离。 如果一个函数调用是一路向下层透明转发的,说明中间的层次并未凭添更多的能力支持,那么不妨直接跨层调用。 或者思考分层的合理性、是否中间层次的能力太薄可以省去。
复杂性尽量下沉的意思是说,下层模块的开放姿势要尽可能的简单,尽量闭环可以处理的错误、隐藏没有必要对上方暴露的概念, 这样才不会向上层的众多调用者传播复杂性。
从我们对分层设计的各种原则来看,它是反对循环依赖的,也就是说, 所有模块按照依赖方向要最终组织成一个有向无环图。但是这种反循环依赖的态度应该是开放的,因为实际实现中循环依赖难以避免, 虽然往往是源于分层设计的不合理,不过也有例外。因为可能一个模块之中,存在两个不同的概念对同一个另外的模块具有相反的依赖方向。
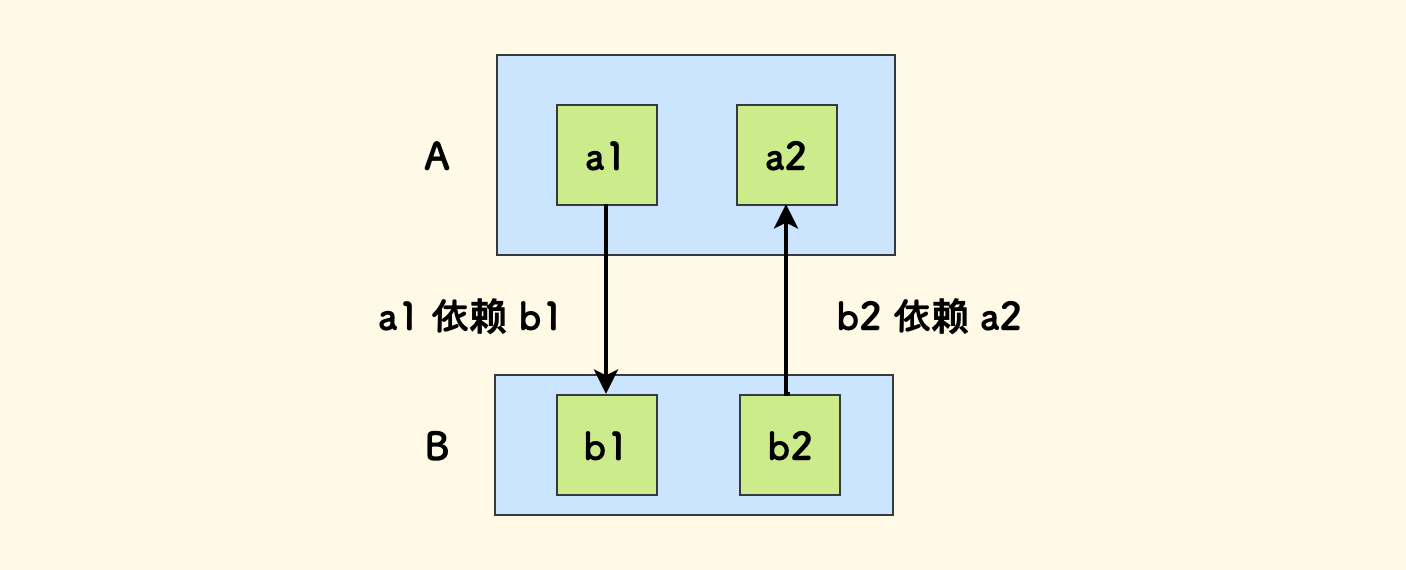
这种情况下,要么继续拆分为两个更小的子模块,要么实现中应用循环导入的一些具体技术。 这也是为什么实际代码实现中,两个子系统之间相互调用的现象有时难以避免的原因。总而言之,保证大多数情况下无循环依赖即可。
分层设计也有其缺点,同样来自 《通灵芯片》 的一段话:
分层系统中的底层部件的故障可能会波及整个系统。
一个底层模块出现问题、或者发生不兼容修改,就会波及到其上层所有依赖它的模块。越底层的模块,影响的范围可能越大。 也正因如此,底层设计要健壮和长远。不过,针对这个缺点,可以应用 冗余设计 的技术来弥补。
另外,我们强调了层次之间要设计好抽象隔离,但这同时也增加了理解成本。 作为上层调用者,对于非常关键的场景,有必要摸清下层的实现逻辑,以明确调用路径上的性能损耗、最好/最坏情形 和 异常情况, 即「白盒思维」。有些性能敏感的系统的设计中,哪怕是一些进程内的函数调用,中间做了几次内存拷贝、有无做动态内存申请都是需要清楚的。 不过,这个过程会增加开发的精力和时间消耗,做不做这种调查、量情量力而行。
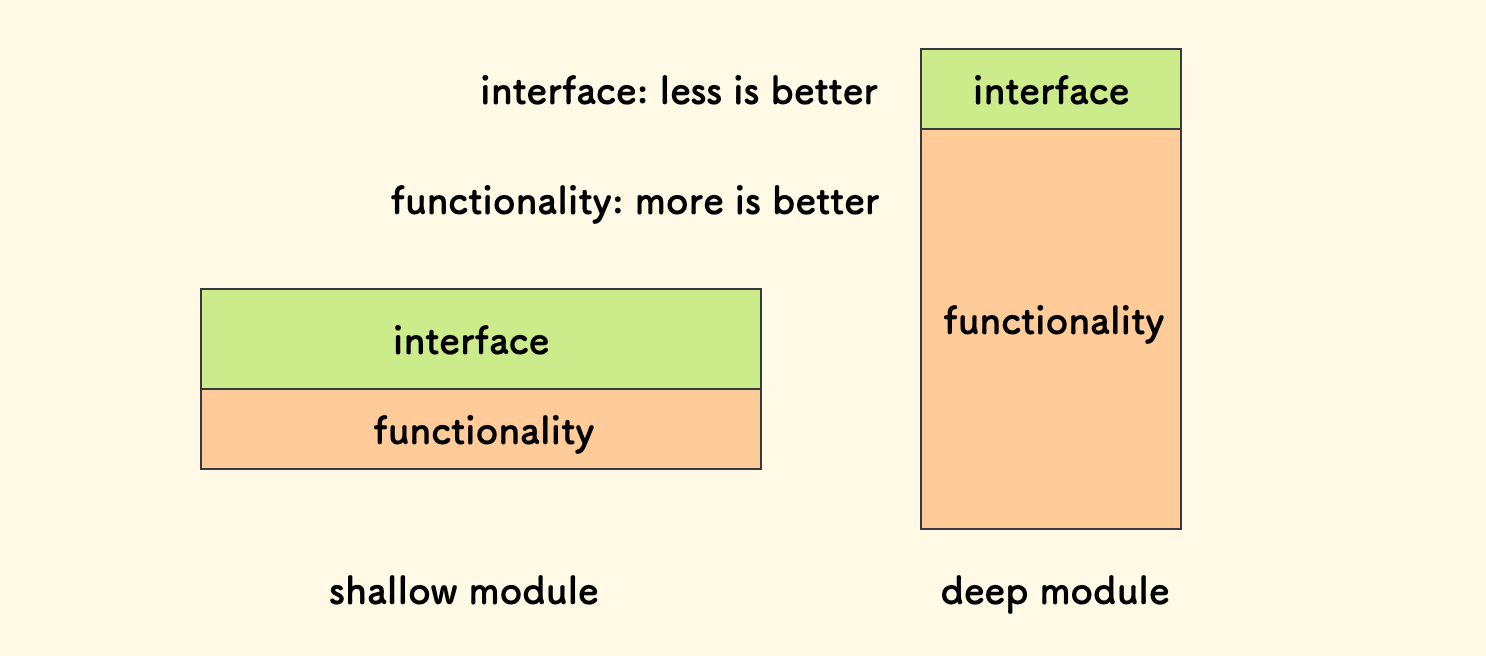
深浅模块
最初是从一本软件设计的小书 《A Philosophy of Software Design》 中了解到了这个概念:
The best modules are those that provides powerful functionality yet have simple interface, that calls deep.
最好的模块是深模块,它们有着强大的功能同时提供简洁的接口。
耦合和内聚
耦合表达的是模块间的关系、内聚表达的是模块内的关系。
当我们说两个模块是耦合的,说明其中一个模块的修改必然引起另一个模块的修改。
在大多数情况下,我们期望的是 高内聚和低耦合:
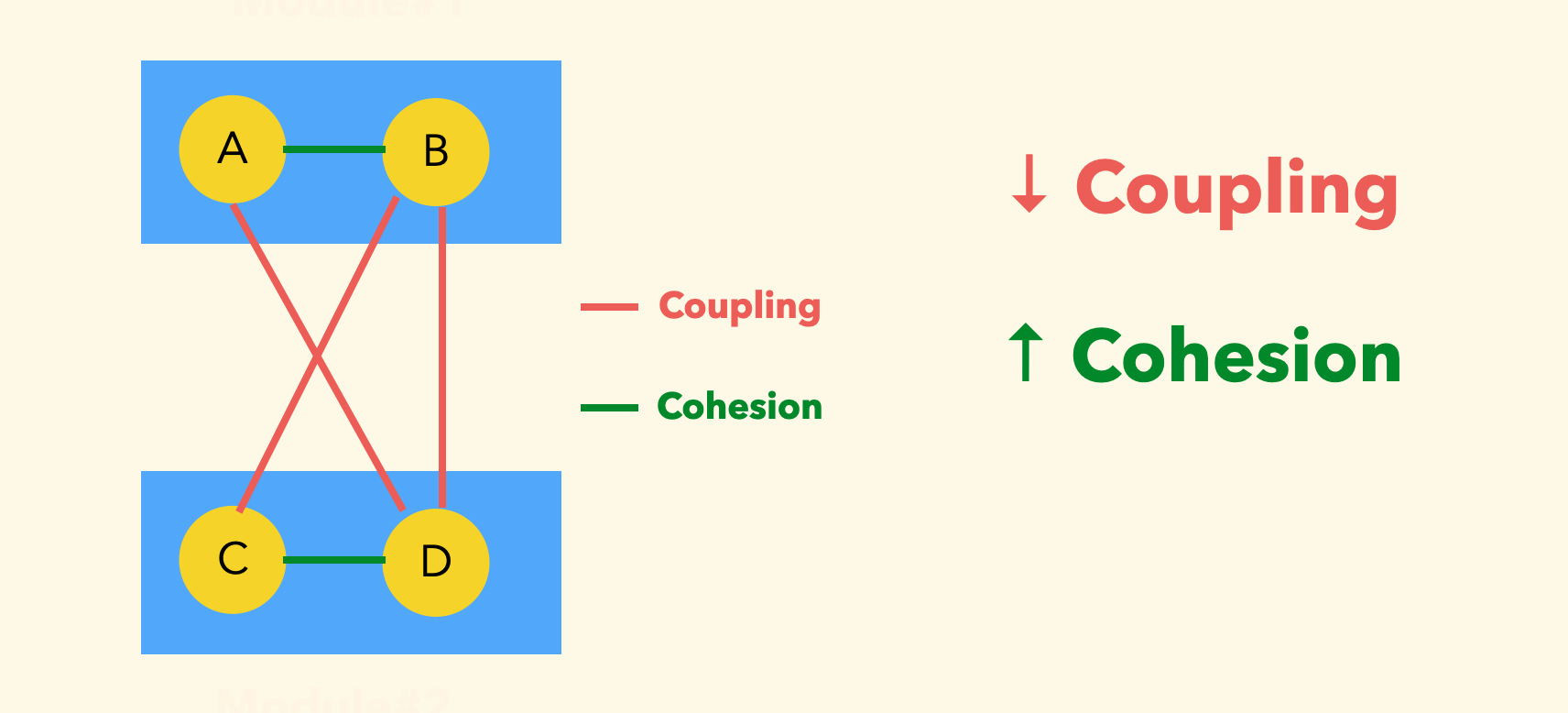
因为模块间低耦合意味着未来的修改相对独立、扩展更加灵活。模块内的高内聚意味着模块本身设计地更「深」。
不过,万事无绝对,低耦合的设计有时会带来性能下降 和 理解成本的上升。 这是因为,为了实现低耦合,可能要引入中间层抽象,这些「间接关系」可能是一些中间函数调用、数据格式转换过程,即会带来额外开销。
你可以想象一下,从零写一个 Web 服务器实现一个网站,相比采用一个成熟的 Web 框架来实现相同的能力,后者显然是低耦合的, 但是前者实现地足够好的话,性能会更好,因为它完全不必考虑通用情况、也省略了抽象隔离的中间转换。 我想,C++ 世界中程序员喜爱自己造轮子的一个原因,就是他们额外关注这些中间抽象带来的额外开销。
不过大多数情况下,管理软件的复杂性更为重要,大的方向一般是「低耦合」设计,与此同时尽量降低这些额外损耗。
模块的动态组合
在分层设计中已经提过,模块要最终组织成一个有向无环图,也就是森林结构。再简洁一些,可以组织成一棵树,这只需加一个虚拟根节点来占位即可实现。
模块化就行搭积木一样,如果模块之间的耦合足够低,我们甚至可以做动态模块组合(DSL)。 我觉得这是模块化带来的最惊艳的能力之一。
一个绝佳的例子是 行为树,其中每一个节点即是一个模块,不同类型的节点实现了不同的行为。 节点之间的组合关系可以有 顺序、选择 和 并行,这十分像「编程语言」中的控制流,通过把行为节点组合成一颗树,就组合出了一套行为。 如果进一步把组装结构序列化成数据(比如 JSON),就可以通过数据来还原行为,也可以走通信来传递,比如远程下发一段行为树结构的数据给一个智能体让它做一套动作。
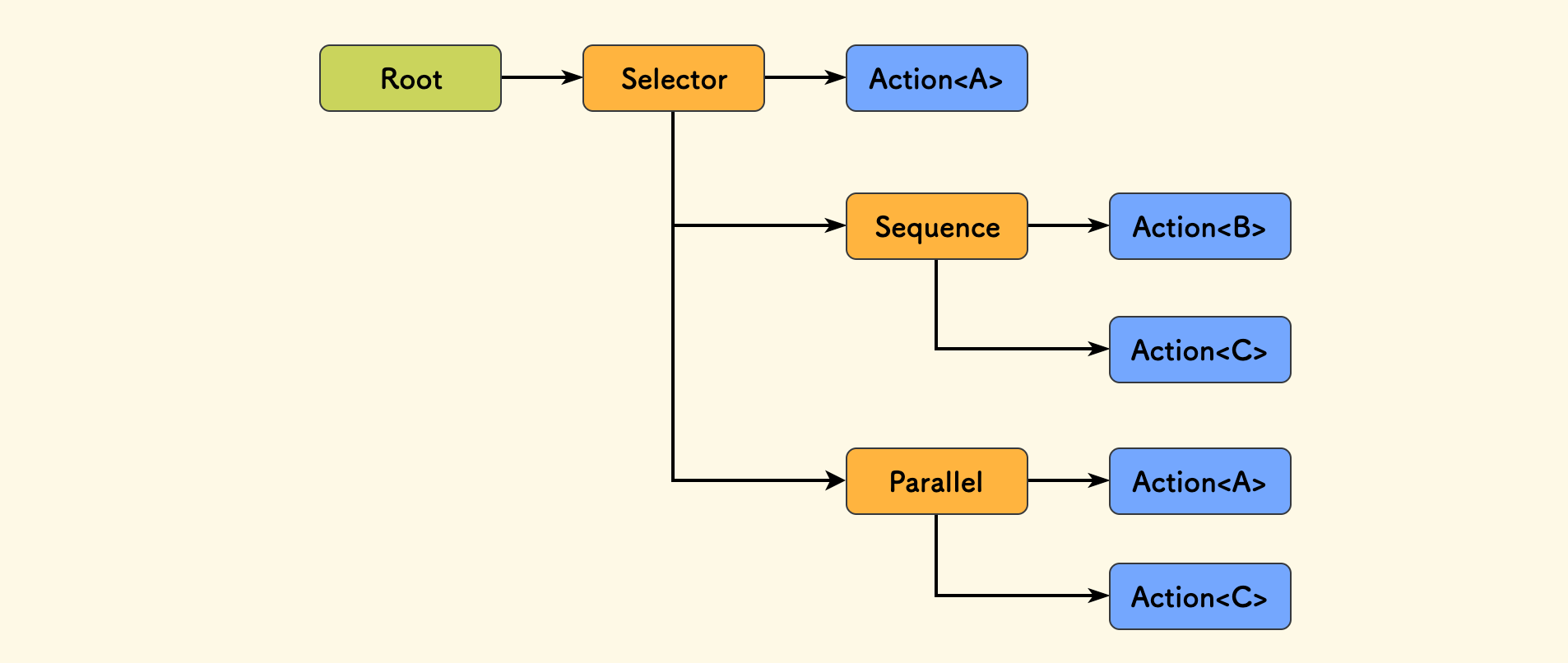
这个例子给出了如何做动态模块组合的启示:
- 模块之间是松耦合的。
- 组装成为一棵树结构是一个不错的主意。
接口设计 ¶
接口在这里并非狭义地指 HTTP 和 RPC 接口,而是广义上指函数。
接口列表
一个模块开放的所有能力,构成其接口列表。设计接口列表时:
- 推荐从顶层模块开始、向依赖方向倒推接口列表。
讲究 分清 和 分净 :
- 分清是说接口之间尽量正交、无能力重叠。
- 分净是说不存在遗漏场景未覆盖。
- 定义接口时,不必过多去思考如何实现,此时更重要的是,它需要成为什么样子。
举例说,我们要定义一个 heap 堆的接口列表,那么可以如下设计:
Value Top(); // 返回堆顶元素, 如果是空堆,则属于未定义行为
size_t Size(); // 返回堆中元素数量
void Put(Value value) // 向堆中插入一个元素
Value Pop(); // 弹出堆顶元素,如果是空堆,则属于未定义行为
对于前面拆单的那个例子,基础函数模块,可能会有很多接口,每个接口是相对简单的。 拆单器可能逻辑比较复杂,但是对外只需开放一个接口。
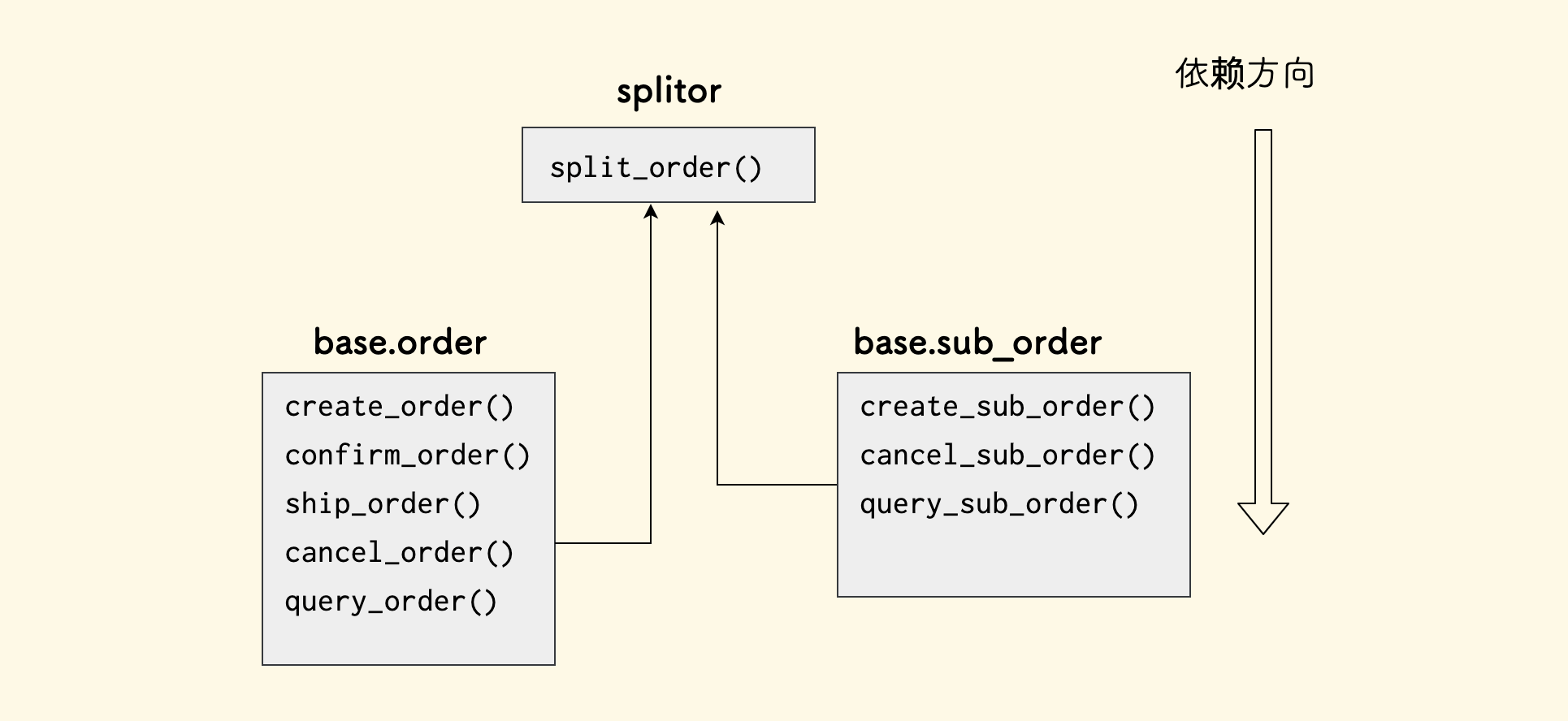
设计一个好的接口
接口设计是考验功力的环节,好的接口的特征应该是:
- 力求简洁、能力强大。不推荐纯转发性质的薄接口。
- 一个接口专注做好一件事。
- 标注好支持的情况:接口是否可以重复执行?是否存在未定义行为?可能发生的错误?
接口定义的简洁性比它本身的实现更重要,不管实现怎么复杂,首先要卖相好。有一句话这么说,挺有意思:
优雅的接口,龌龊的实现。
不提倡只做透传、纯转发性质的薄接口,因为它没有为系统新增任何实质性的能力。反而增加了模块之间的耦合联系,提高了复杂性。 不过存在一路透传参数的情况,比如 Golang 中的 Context 结构体, 这相比于全局变量的方式更好。虽然参数是一路透传的,但是途径的函数实现的能力并不相同,这并不违反这里所说的原则。
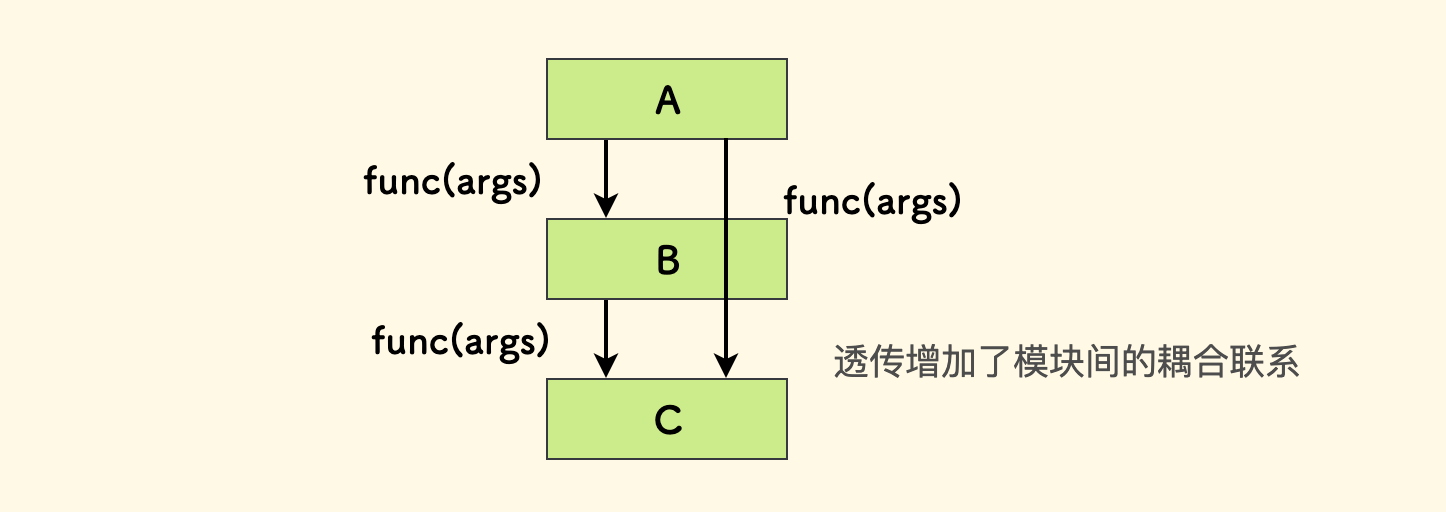
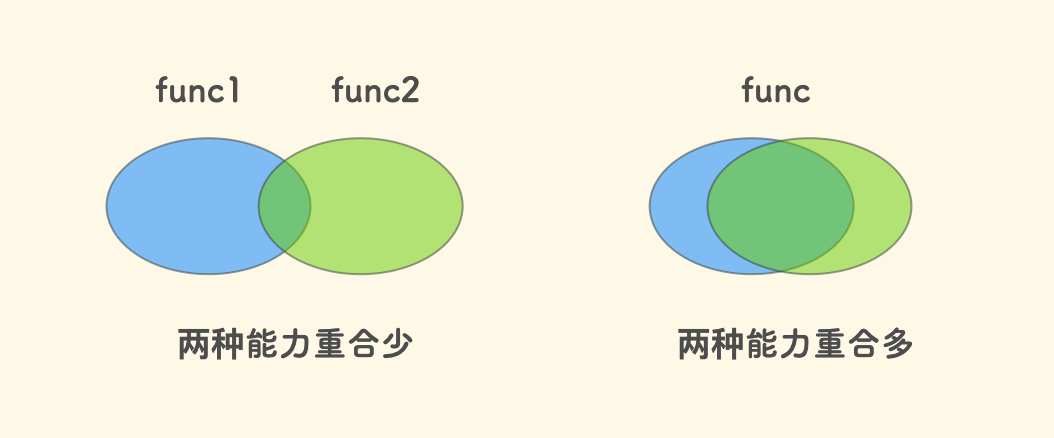
一个接口的能力尽量相对确定。如果两种能力重合度并不是那么高,建议分开作为两个接口。 如果硬是做到一起,可能会让调用者难以确定会发生的行为。
两个具体的通常和例外的 Case 举例
有时会看到一些叫
GetOrCreate或者CreateOrUpdate的函数,我个人是反对这种设计的。 因为调用者可能难以确定会发生什么。分离成两个确定的函数可能更好,因为就具体实现的能力而言、其实并未有太多耦合。如果两种能力重合较多,也有例外 Case 。
比如说一个数据容器,提供了一个函数叫做
Get(key),它可能会做对输入检查越界。 如果某些情况下,调用者可以确信输入的正确性,此时避免检查可以提高性能,所以提供无检查的版本UncheckedGet(key)。 这种情况下分离两个接口比提供一个综合的Get(key, shouldChecked)的通用方法要好,虽然两者主要做的事情是一致的, 但是UncheckedGet的目的之一就是消灭条件分支,第二种设计显然无法绝对消除这一点。
接口设计中有一个「幂等」的概念。一个接口是幂等的,说明它可以被重复调用、而不会有意外发生。 对于一个写性质的接口,尤其值得关注。 比如说,对于一个创建对象的接口,如果我们采用 Append 追加的方式,接口就不是幂等的,因为调用几次就会新增几个对象。 如果每次创建前都去检查一下是否已有对象存在、只有不存在的情况下才去创建,那么这个接口就是幂等的。当然并非一定要用预先检查存在性的方式, 比如对于一个哈希表来说,向其中插入一条数据自然会是幂等的。幂等的概念也存在于脚本的设计之中,在执行一个脚本之前,有必要关心其是否可以重复执行。
此外,接口的设计应该让通用情况下的调用尽可能简单。比如参数默认值要贴合最通常的情况。
Interfaces should be designed to make the common case as simple as possible.
-- 《A Philosophy of Software Design》
交换数据
某些系统之间并不靠接口沟通,而是依赖交换数据。比如我之前做的 bitproto 就是一种比特级别的数据交换格式, 里面不涉及接口的概念,结构体就是协议本身。这其中有两种形式:
- 两个系统交换自己的数据给对方。
- 基于一个全局共享的数据池,即 黑板模式。 比如说,行为树就是基于这种方式在节点之间交换数据;游戏中的知识池也是这种模式,就是一个模块化的大结构体。
直接交换数据往往会比接口的方式支持的情况更为丰富。比如说我们有 N 个关键字段,那么可以支持的情况会是这 N 个字段所有可能的取值的组合。 其设计思想也和面向接口完全不同,而是面向数据的,这种情况下完全没有接口的概念。
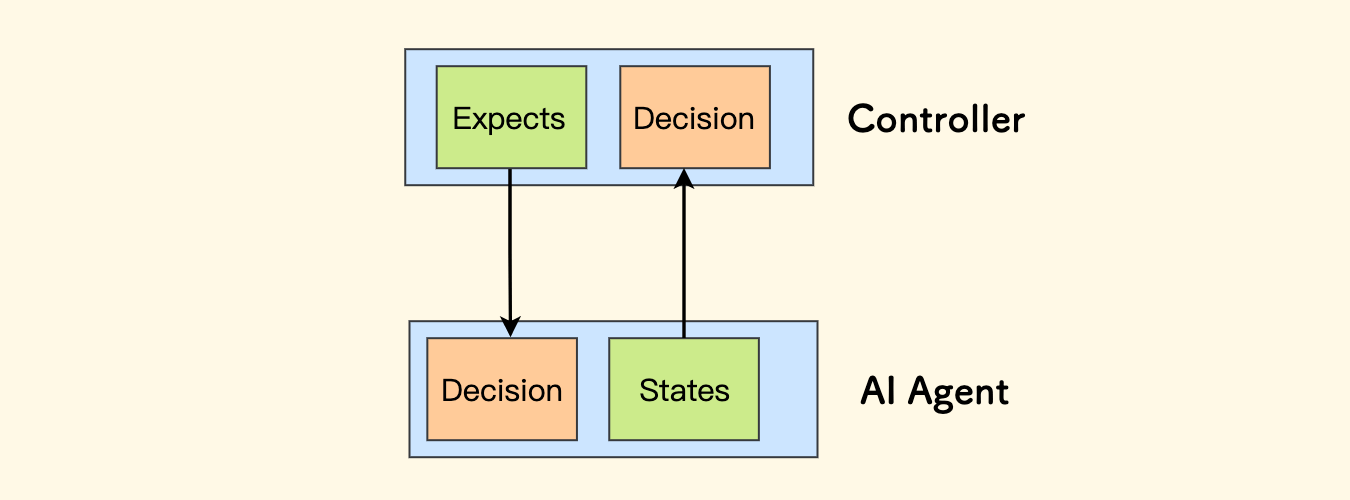
在实时控制的程序中,比如控制一个智能体、机器人、游戏中的英雄等,可以采用不断交换数据的形式,控制方给出期望达成的状态、被控制方给出当前实际的状态, 都通过结构体呈现。双方都会实时观察对方的数据,来实时调整自己一侧的策略,实现了闭环控制。
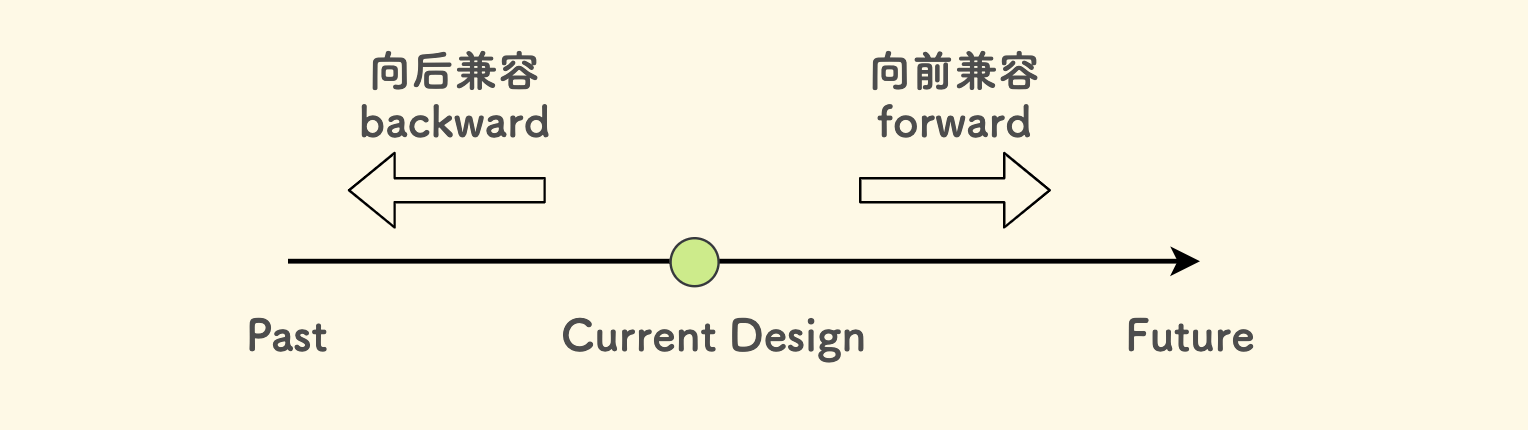
接口的兼容性
- 向前兼容是说,当前的设计要能兼容未来的使用情况。
- 向后兼容是说,当前的设计要能兼容以往已经存在的使用情况。
用一张图来理解,下图中的时间线是自左向右、从过去到未来:
向前兼容关注的是扩展性,这个考验设计者的前瞻能力,尤其是大方向不要发生结构性设计错误。 比如说,预先设计好占位字段。在一些嵌软通信协议中,会有这种 Dummy 字段,一方面可能为了结构体对齐的考虑,另一方面就是为了向前兼容。 现在还无法确定这个字段的内容,但是未来可能会填一写数据进去。这样当那一天来临的时候,协议的结构和长度不会被破坏,解码者不会陷入错误。
这个 Dummy 字段例子的进一步说明
Web 领域的开发者可能难以理解这一点,因为对于他们来说,新增字段稀疏平常,不必预留占位字段。 这是因为无论是 HTTP 协议、还是 Protobuf 这种高级协议格式,它们会在协议中隐式植入反射信息。

这些反射信息用以描述数据的长度(比如 Content-Length)、或者字段的排列顺序等。 而对于「惜字如金」的嵌入式通信中,基本不会加入反射信息( CheckSum 是个例外), 这时协议的长度变化、结构性变化就会影响到解码正确性。

向后兼容更难一点。尤其是对于 删除 和 更新。应该做好事先调查,或者干脆提供一个新版本的接口。 柔和的方法是,新老版本并行存在一段时间,直到所有调用者都顺利迁移完成。
对于一个调用者而言,尽量控制外部接口破坏兼容性带来的影响面:
- 对外部接口只做转发式的封装并没有太大意义,这并不能减少接口兼容性破坏时的修改量。
如果依赖的多个外部接口能力相似,可以进一步抽象。这种情况、由于抽象层的存在,不至于对某个外部接口的调用散落在各处,有助于减少这种影响。

- 一个外部接口破坏兼容性的本质是它的不可用。所以还可以有一种策略,就是预先设计好冗余能力和故障转移机制。

前面的这几种例子,都暗示着 兼容设计 和 冗余设计 之间存在关系,我想「破坏兼容」本身是一种故障,而冗余设计的目的就是转移故障。
对于某些类型的客户端,其依赖接口的向后兼容性极为重要。因为它们无法实时升级、软件的更新会需要比较长的时间, 比方说 手机端的软件、智能设备上的固件。
最后,我认为也要辩证地看待打破兼容性的做法。因为保证兼容性是很累的,如果一直抓住「向后兼容」的保证不放的话, 系统会变的复杂、也会拖慢迭代。这很大程度取决于软件本身的定位。比如说 C++ 的复杂,不过这也是其魅力所在,十年前的程序仍然可以通过现在的编译器。
数据模型 ¶
广泛的说,数据模型的设计可以理解为数据结构的设计。不过这里主要关心的是实体和实体关系。 实体是指系统主要处理的数据对象。
数据模型的设计应该考虑下面几个因素,这都与数据是如何使用的密不可分:
- 数据的存储形式(内存、磁盘、数据库等)。
- 实体的组成(字段)和 实体关系。
- 实体在存储上的组织形式(顺序、索引等),这和如何查询数据息息相关。
- 字段的含义应该是直接而确定的。
- 保持数据模块的纯粹性、最好和逻辑分离。
我的习惯是,先划分实体、再考虑实体关系、最后再补充实体自身的详细字段。
对于互联网后端服务来说,一般数据模型的设计就是数据表的设计,一般推荐的是 3NF 范式。 不过,在某些情况下,可以做冗余设计,比如说定义冗余字段、缓存等,这一般为了加速查询。 实体关系一般有两种:一对多关系(比如属于关系、分组关系) 和 多对多关系(比如标签)。 我们的习惯是不推荐直接用数据库的外键,而是在应用层理解外键关系。 此外,在数据库存储的数据模型中,理解索引的结构和查询的原理非常重要。
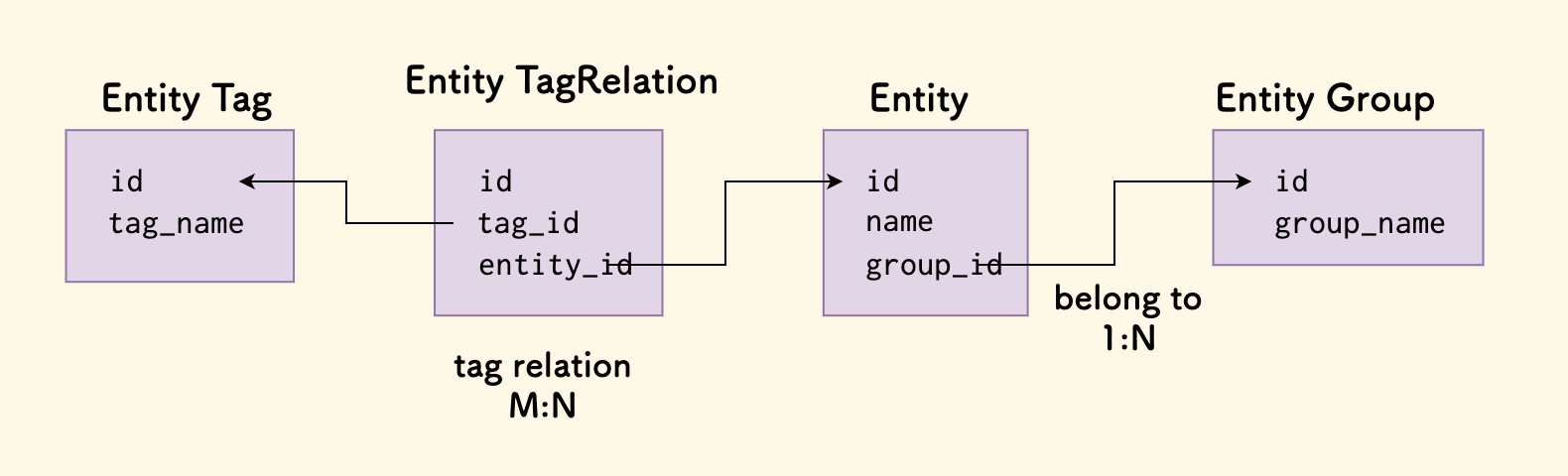
数据的字段应该是直接而确定的。 比如说,一个实体有两个字段 isA 和 isB,查询的逻辑总是 isA or isB,那么会先询问 isA,如果得到假的答案, 那么要继续询问 isB。这里就会让查询变的「间接」起来,对于单个条目来查询尚且还好,但是如果做一次性批量查询,会比较难受。这种情况下,不如直接冗余一个答案在实体上。
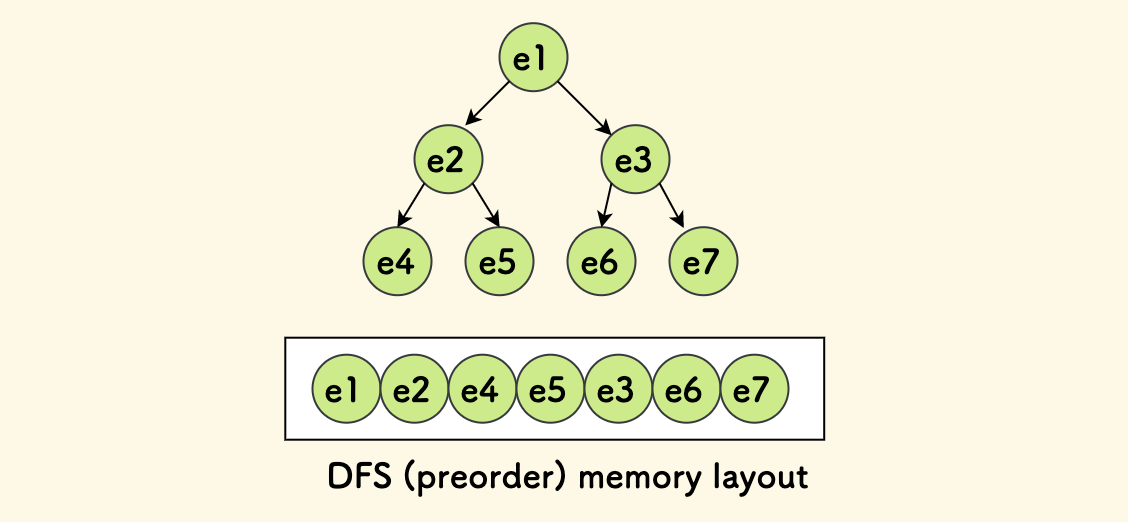
在一些实时系统中,数据模型主要存储在内存中,定义为结构体,比如游戏中,一个实体可以划分为几个组件结构体的组合。 另外,这种情况下需要关注实体在内存中的布局(对齐 和 顺序、局部性原理),按查询的顺序来存储可能会性能更好。 比如说内存中的一颗树,如果我们总是采用深度优先的方式来查询,那么不妨直接按 DFS 的顺序来排列这些数据,事实上,对于线段树就可以这么干。
另外,存放数据模型的模块要保持纯粹,意思是不要和行为揉在一起。 原因在于,一个行为函数应该可以对其投喂任意符合条件的实体数据,把数据和行为分离有助于提高行为函数的通用性。 通俗的说,不要在数据模型的结构体上绑定太多的逻辑方法,而是把逻辑实现到对应的系统模块中去。 下面的代码是不推荐的,这里只定义数据字段即可,而不要在这里定义复杂逻辑。实现一个单独的 cancel_order 函数才是更推荐的。
class Order:
# 省略字段定义..
def cancel():
pass
关注点分离 ¶
本章节是本文中除了模块化之外最大的一个话题。
关注点分离背后的思想仍然是模块化,每个模块专注于单一的职责,不同的职责分离到不同的模块中去做。
我总结了一些重要的关注点分离的设计方法:
前面在 时序的概念 章节中已经举过一个「时序分离」的例子,不再复述。
生产消费分离
我总结了生产消费模型的两种经典场景:
任务型消息
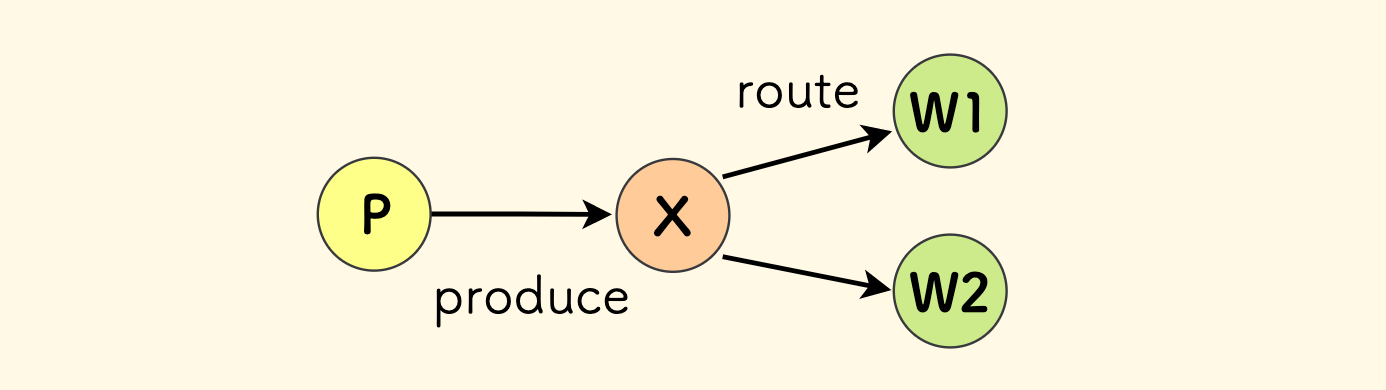
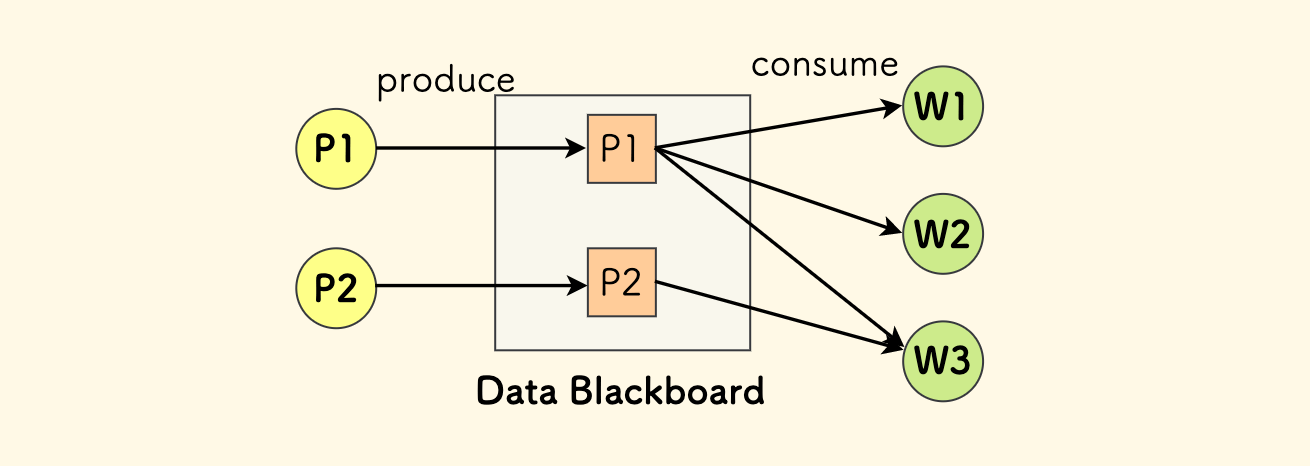
只是为了异步处理、或者为了扩容来提高处理效率。比如说对于带网络 IO 的任务,可以扩展消费者的方式来提高并发。 此时,生产者理解消费者,可以把它们直接划入同一个模块中。
下面是这种场景下最简单的模型,
P代表生产者、Q代表队列、W代表消费者。 生产者直接把消息吐到队列、同一种类型的Worker扩展了多份来消费。
信号/事件型消息
生产者不理解消费者。 生产者不要关心谁来消费,二者解耦,可以不处于同一个模块。
队列的作用之一,就是用来解耦。
常用的场景就是 信号/事件 系统:
// 生产者视角 producer.emit("signal", data); // 消费者视角 consumer.on("signal", handler);下面是这种场景下的模型,以 rabbitmq 为蓝本,
X代表交换机,对原始消息进行路由,这可以是直绑、也可以是复制、也可以是模式匹配等等。 总之是为了决定消息会发给哪些队列。在这个模型中,队列也可以有多个,背后的消费者也可以有多种类型。这个模型非常适合构建「信号/事件系统」,因为它充分实现了生产消费分离。生产者作为一个广播者、不必关心信号最终会流向哪个队列、也不关心最终会被谁消费。



举一个例子,在一个订单系统中,我们在订单的关键状态节点上加上信号:
signal(order.created)
signal(order.confirmed)
signal(order.shipped)
signal(order.delivered)
signal(order.finished)
signal(order.cancelled)
然后,在其他系统中,就可以订阅这些信号。比如前面的拆单器,当一个订单得到确认后,就会触发拆单:
splitor.on("order.confirmed", handle_split)
在拆单完成的时候,它也会释放一个信号 order.split_done。可能会有另外一个系统,比如仓库系统,订阅了这个消息,创建出库单。 从时序的角度看这个过程,如下图所示:
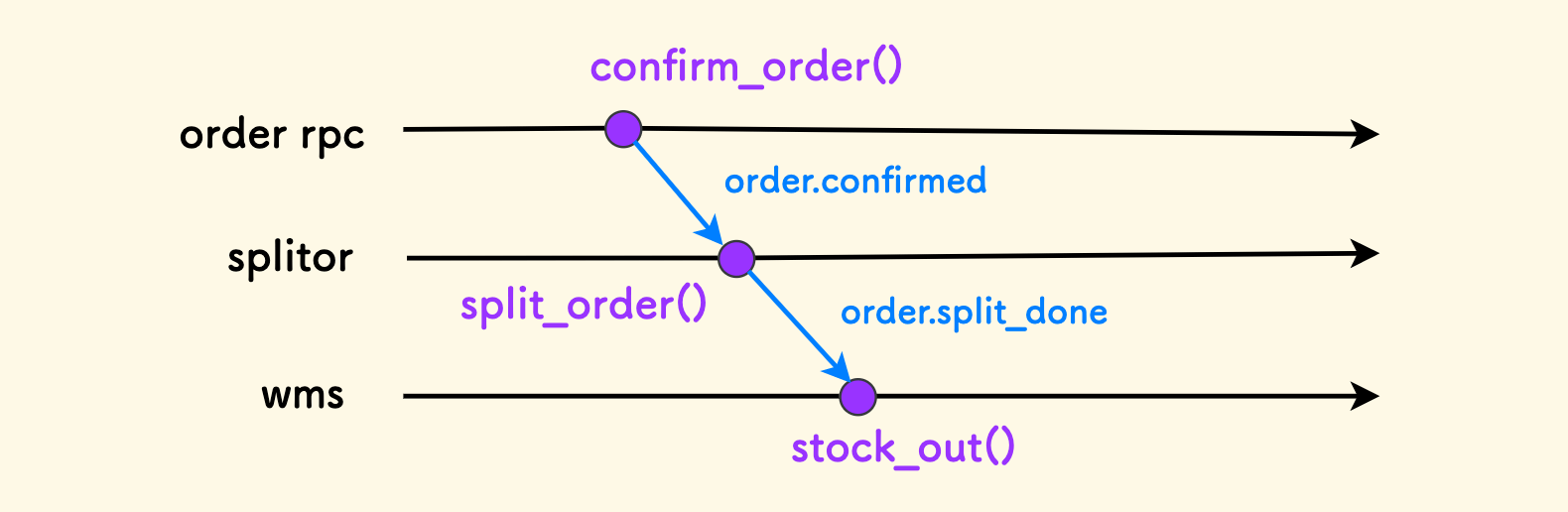
在这种信号系统中,订阅关系转换成路由关系注册到交换机,信号消息会复制到多个队列,然后流向几种不同类型的消费者,而且各种消费者可以伸缩。
信号系统可以把多种时序联系起来。不过要经过精心设计:
- 过度滥用信号也会导致时序混乱、难以治理。
- 是否会形成「环形信号链」,比如
a → b → c → a导致消费会无休止的进行下去。 - 信号的定义,可以围绕 关键状态节点、关键事件 设计。
生产消费分离更多地是作为一种重要的设计思想。有时并不一定非要借助一个「队列」。 比如对于进程内的信号系统,可以省略队列,生产者直接把消息路由到消费者,此时中间的交换机就充当了解耦者的角色。 我实现过一个叫做 blinker 的信号库,其中用一个 trie 字典树来存储订阅关系,相当于这个交换机的角色。
另一个例子,在依赖一个数据池来交互的系统中,生产者只负责写它的数据区,而不关心谁来看。 关心这块数据的消费者自己去查询。这里面同样没有队列的概念,甚至没有交换机的概念。 所以,生产消费分离更多是一种解耦思想,并非一种具体技术。
读写分离
顾名思义,分离数据的 读时序 和 写时序,使二者互不依赖。
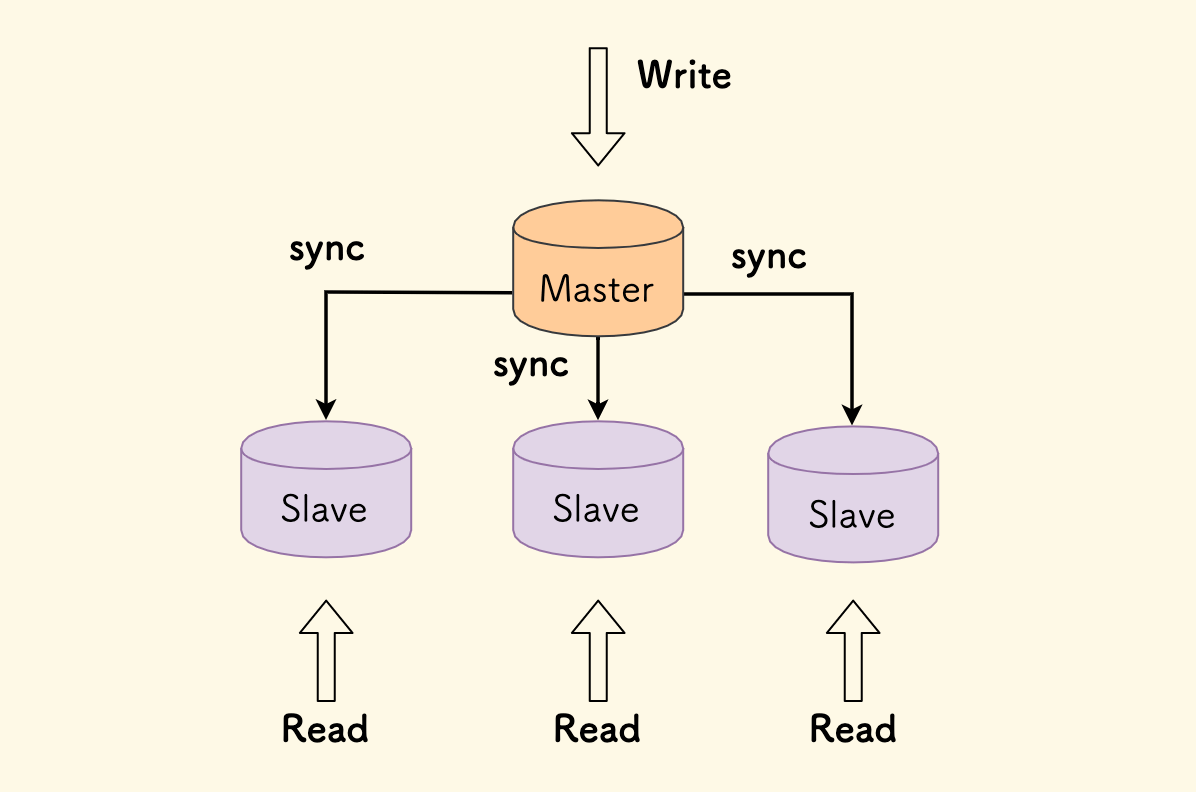
最经典的例子是,MySQL 的主从架构,写主读从:
- 可以降低主库压力。
- 从库是只读的,支持横向扩展,即一主多从,可支持更多的读请求。
MySQL 主从模式下的一致性和响应时间的问题
- 如果主从同步是异步的,就可能存在延迟,客户端会面临数据一致性问题。比如刚刚写到主库的数据,可能无法及时在从库中读到。 虽然这种延迟一般会很低,但是无法根本避免。
- 反之,如果主从同步是同步的,客户端写主库的时间开销就会增加。
这其实是分布式系统中一个「鱼和熊掌无法兼得」的问题, 从单节点结构扩展到多节点的分布式结构时,响应时间和一致性在某种程度上是反相关的。
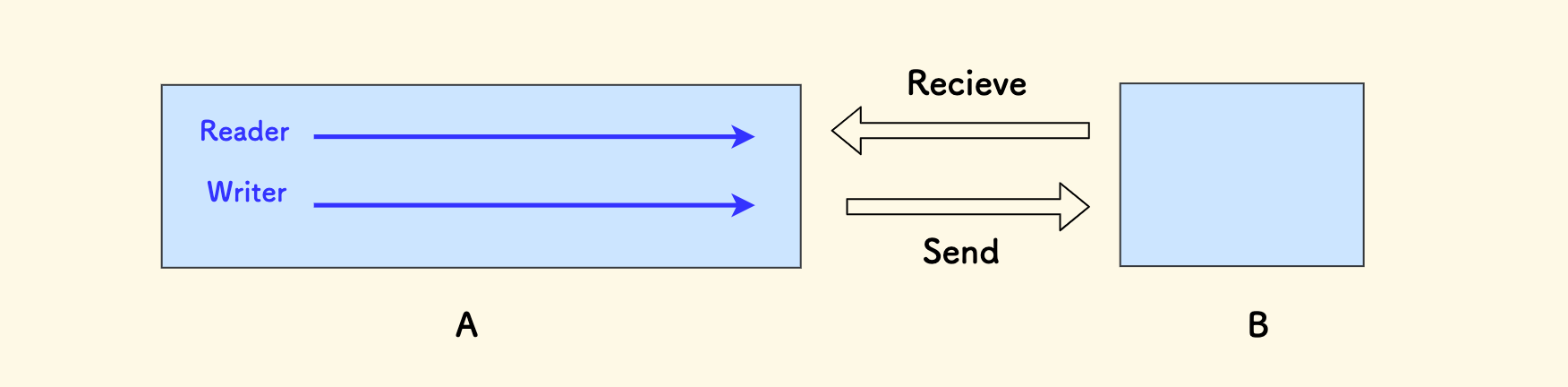
另一个例子是关于通信的。比如 TCP 是支持全双工通信的,即允许通信的双方同时进行数据的 发送 和 接收。 那么对于应用层如何利用这个全双工的能力呢?需要分离读写时序,在 Golang 程序中,就是两个 goroutine, 其中一个是 发送者,另一个是 接收者,二者互不依赖。读不必等写、写也不必等读,并发进行,有助于提高通信效率。 就这个 Case 而言,也可以叫它 「收发分离」。
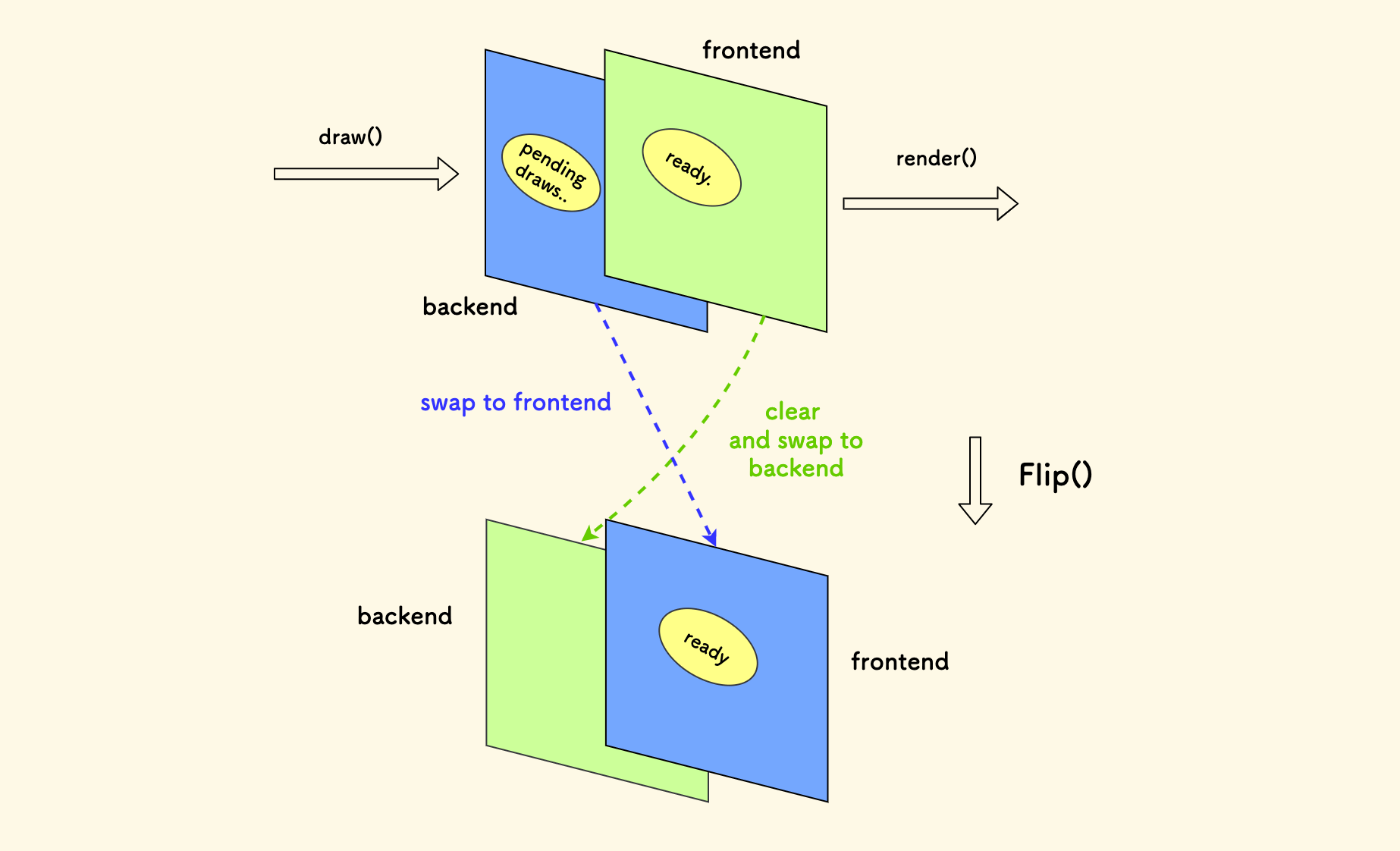
最后一个例子是 双缓冲设计模式。 比如在游戏的时间帧循环中,存在两块缓冲区,前端缓冲区面向渲染、后端缓冲区给当前帧进行绘制,在帧尾把两块缓冲区进行交换(通常是交换指针)。 这样避免了读写冲突、确保了每一次渲染的完整性、避免闪烁。实际上就是把读写的缓冲区分离。 在我开发的信号库 blinker.h 中也用到了这种设计。
计算和 IO 分离
在一个计算相对复杂的函数中,尽量把 外部数据依赖 和 计算过程 分离。
- 把算法实现为一个独立的函数,或进一步放入一个独立的模块中。
- 算法所依赖的外部数据,通过参数的形式输入到算法函数。
对于具有 复杂计算、又对外部有多种数据依赖 的过程,一个示意性的例子是:
- 定义一个
Prepare()函数,负责准备一次算法调用中要用到的外部数据。 - 定义一个
Solve()函数,实现算法过程,只包含计算。 - 定义一个
Post()函数,把计算结果应用回功能流程中。 - 最后再实现整个功能函数,组合三者。
void Feature() {
ctx = Prepare(); // 准备数据
solution = Solve(ctx); // 只做计算
Post(solution); // 应用结果
}
其思想和后续 算法的纯粹性 章节是一致的,好处有:
- 可以集中精力关注计算的复杂性,而不被数据查询所干扰。
- 计算过程干净清晰,相对独立,尤其方便做单元测试。
- 如果依赖的数据存储在远程,比如数据库中,先查到内存中,这样计算过程就不必再关心数据读取的 IO 成本。
数据和行为分离
在前面的 数据模型 章节中曾提到过这种设计方法。
考虑下面两种实现方式,二者的取舍非常细腻:
在一个实体的类中直接定义一个方法:
class Entity { // data fields.. void Handle(); };将功能定义为一个独立的函数,与数据模型分开:
struct Entity { // data fields.. }; void Handle(Entity e);
你肯定会见到过许多在 class 中同时定义 数据字段 和 功能方法 的情况,这本身没什么问题。 这两者并无绝对好坏之分。
关键要看 功能是否局限于一个实例之内。 因为对于一个实例方法,调用它的前提是要先拿到实例本身。而对于一个独立的函数来说,却不必如此。
我只能给出偏好第二种方式的一些典型特征:
- 数据字段是完全开放的,结构更偏向于纯数据设定。
- 函数可以处理的是一类实体,而不是具体的一种。
- 函数可以处理一批实例,而不仅仅是单个。
其中第一点是最有力的区分特征:
- 对于一类如数据容器的结构来说,比如一个
hashtable,skiplist等,它们的数据字段、内存布局都是私有的,必须要通过开放的方法来访问它。 这时候,选择第一种方式。 - 而对于一种实体结构体,比如 订单数据、通信结构体、知识池 等,它们的数据字段是完全开放的, 更偏向于纯数据的设定。这时候,选择第二种方式。
- 在 C++ 中,关键字
class和struct仅在默认的访问设定不同。 约定俗称的做法是,对于纯数据设定的结构,采用struct关键字,否则采用class关键字。
// 第一种情况,数据是私有的,必须要通过方法来访问
class Hashtable {
private:
Bucket* buckets;
size_t capacity, size;
public:
void Set(Key, Value);
Value Get(Key);
};
// 第二种情况,数据是开放的
struct Knowledge {
Entity NearbyEnemies[N];
Entity DyingSoldiers[N];
};
后两点强调的则是 行为的通用性 和 批量处理的性能, 如果要处理的实体存在 多种类型、多种数量 的特征,偏向第二种方式。
一个例子是游戏开发中的 ECS 架构,先定义一些组件结构体, 比如 位置、运动、精灵 、动画、渲染、目标、血条。游戏中的实体,比如 英雄、士兵、坦克、炮弹、树木、行人、防御塔 等,可以由不同的组件组合出来。 注意,实体不再是一个结构体了,而是一些结构体的组合。 行为系统只关注它感兴趣的组件,比如运动系统只会处理所有带有 位置 和 运动 的实体。 这种模式下,行为必须和数据分离,因为所处理的是一批实体、而且是不同种类的实体,你无法把行为绑定到某种实体类型上。 ECS 中的组件和实体构成了一张二维表格,适当设计好在内存中的布局,对 CPU 缓存友好,可以提高批量处理的性能。
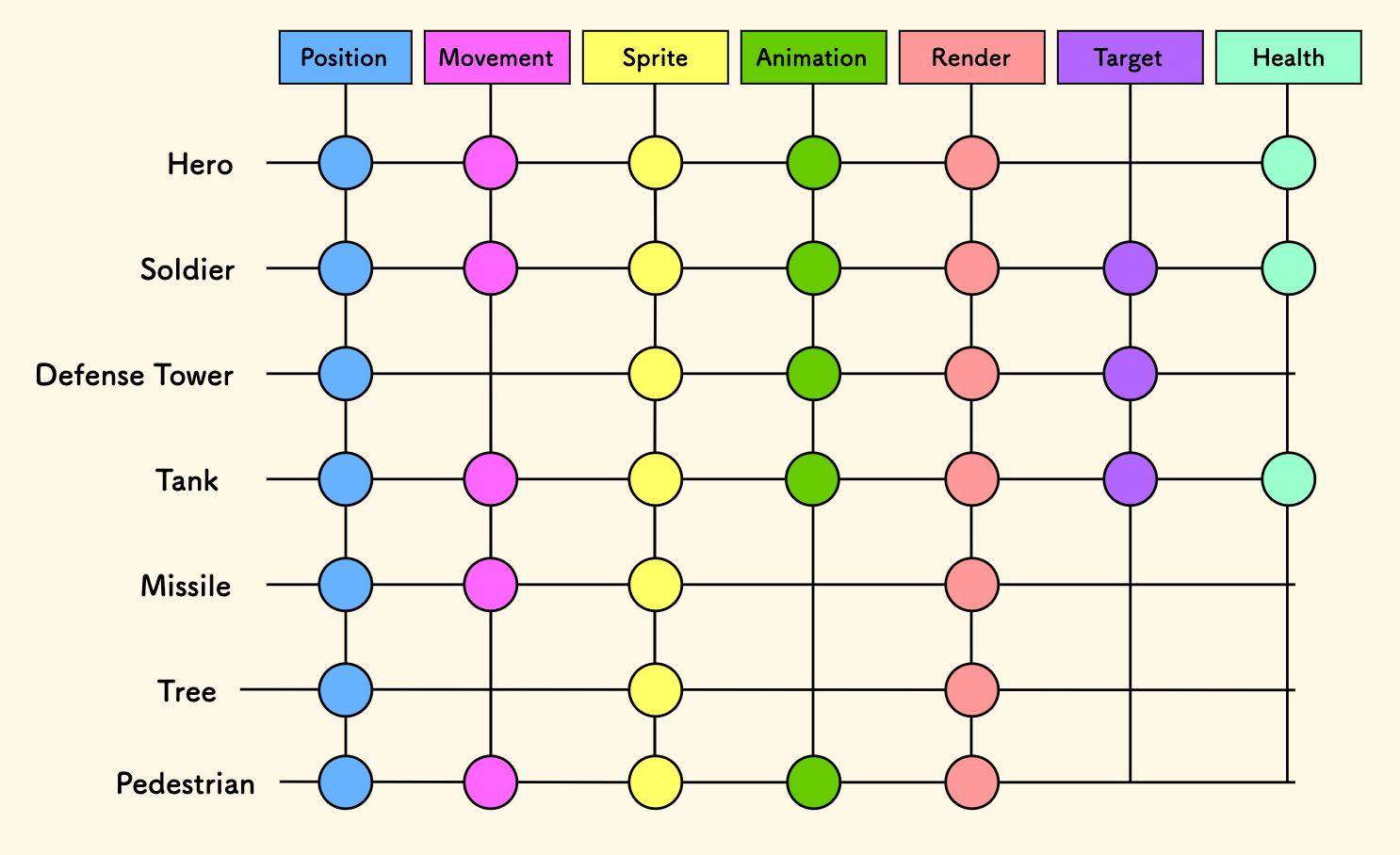
另一个例子,来自我前几天做的下推自动机的库 pdfsm,采用了数据和行为分离的设计。 主要考虑的场景是:
- 如果存在大量的实体、每个实体有自身的状态。
- 同一类的实体有同一套行为。
那么,实现一个具体的状态下的行为时,就不能将数据集中存储,而是要把实体的数据放在它的实体中。 状态机本身定义行为,并不存储实体相关的数据。
策略和模型分离
策略可以 干预 和 丰富 模型的能力,和模型分离的好处是 保持模型的简单和纯粹。
举例,想象一下设计外卖订单分配系统,它的算法和业务模型要尽量保持简单、面向主流 Case。 但是实际运营中可能会有一些场景化的策略,比如面临 雨雪天气、高峰期时段、活动爆单 等因素时,分单模型的表现应该会有差异, 这些策略要建设在上层,和模型本身分开。
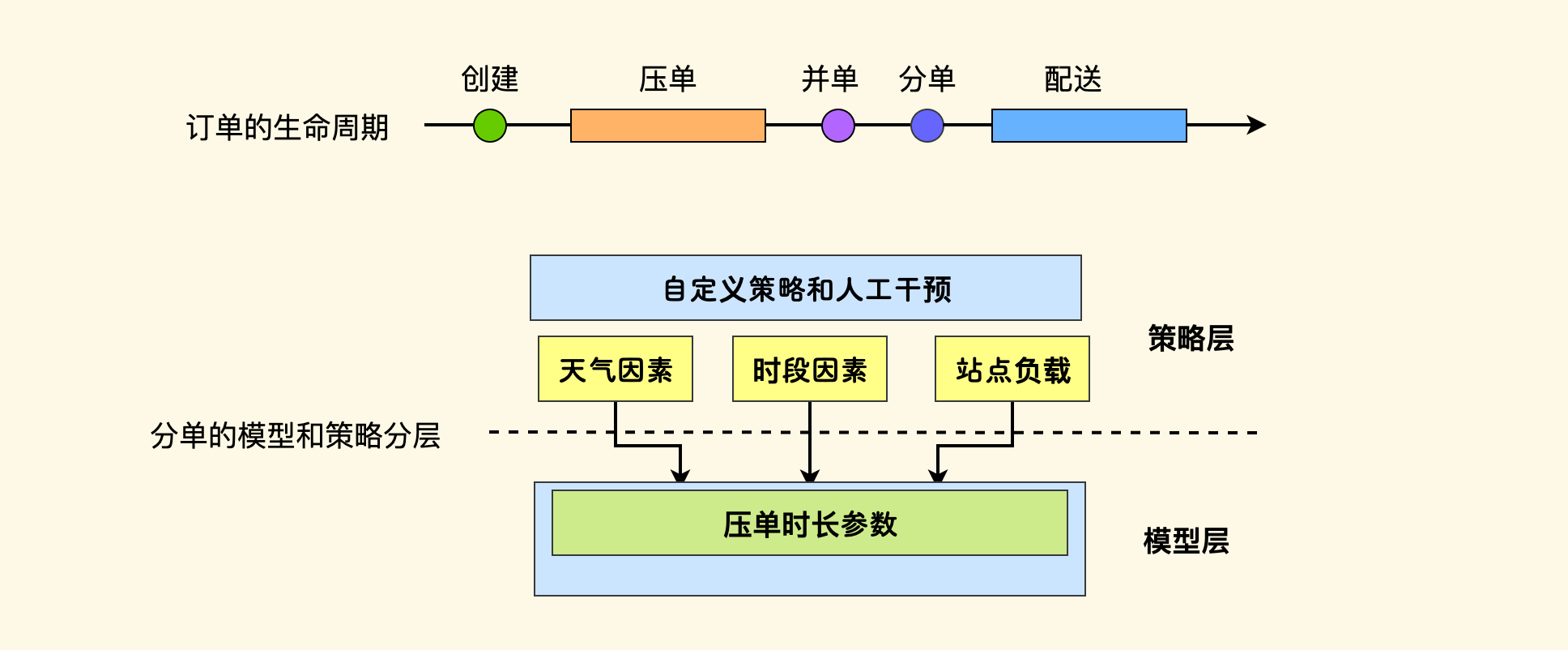
在策略应用时,转化成模型所理解的参数进行调用。 比如说,我们给分单模型定义了一个「压单时长」的参数,订单会延迟一段时间再进行分配,留出这个时间窗口来合并顺路订单,提高外卖骑手的单次配送的背单数。 当面临 雨雪天气、高峰时段 或者 爆单 时,配送压力增大,需要临时加大这个参数的值。对于模型来说,它不会理解具体的场景,只会理解这个参数。 对于上层的策略层而言,它会负责把具体策略 转化到这个模型支持的参数上去。
另一个例子,是客服 IM 系统的会话分配器,负责将客户的聊天分配给一个客服员工。 分配模型支持一个客服维度的优先级参数 priority,越大越优先,定义如下:
- 默认都是
q, 即所有客服之间都是平权的 - 可以采用
< q的数字,表示不推荐分配给此人 - 可以采用
> q的数字,表示推荐分配给此人
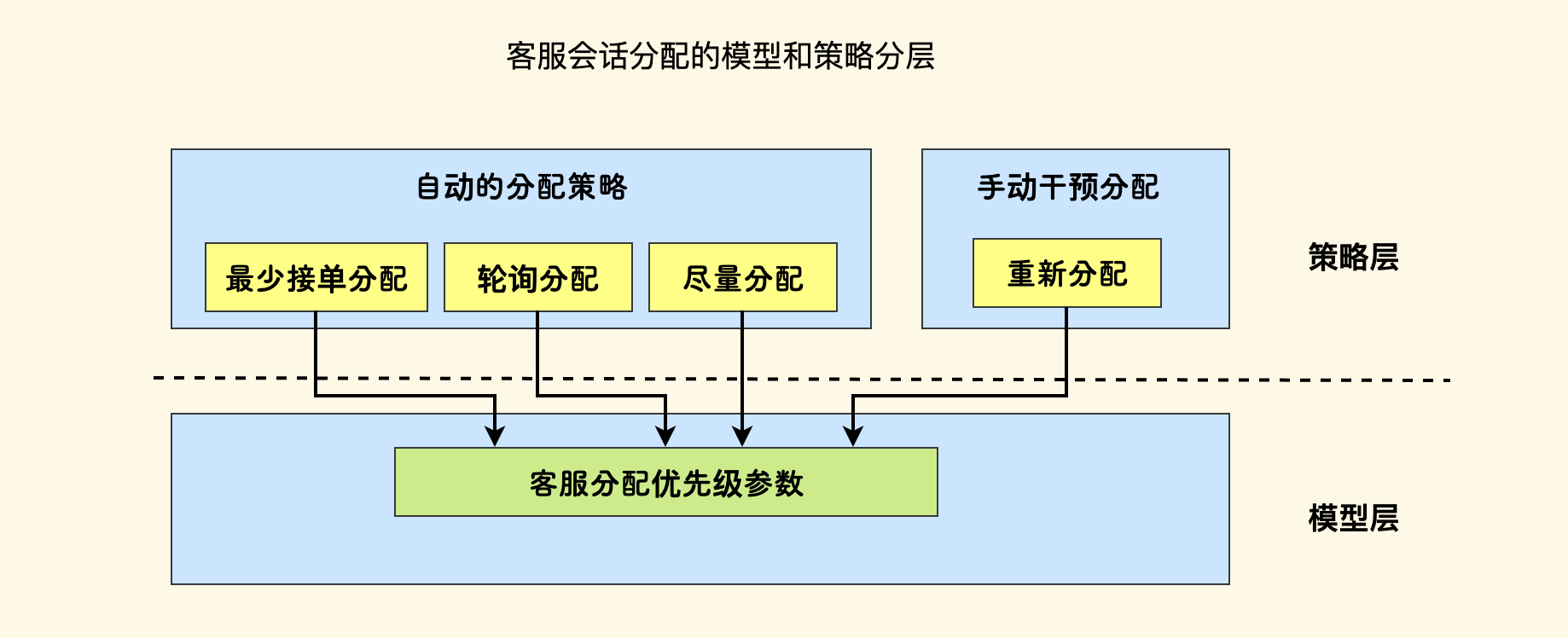
在业务的上层,会有几个策略和场景:
- 最少接单分配: 在所有空闲的客服中,挑选一个今天接单最少的员工进行分配。此时可以客服的按接单量
+ q作为其优先级。 - 轮询分配:对于所有空闲的客服,依次进行分配,此时可以按 一个大数 减去 客服上次接单时间 再
+ q来作为其优先级。 - 重新分配:当客户不满意当前客服时,主管可以把他的会话重新分配给其他客服。这时候期望尽量换一个新的客服来接待,对于原客服要输入一个小于
q的优先级。 - 尽量分配:当客户重新发起会话,继续对之前的事情展开聊天,这时候期望继续沿用上一次的客服,因为他对整个上下文更清楚。此时要给他设定一个大于
q的优先级。
上层场景和策略可能还有很多。这个例子要说明的是,上层的 自动化 和 临时干预 的策略,最终都会转化到同一种底层模型所支持的参数上去。
大多数情况下,我们要坚持一个模型的原则。如果当前模型不支持新功能,那么改造它,让它支持。 没有充分的理由,不要双开模型。
权限和功能分离
你是否遇到过这种代码?功能和权限检查揉在一起,这带来的最恼人的一个问题是,要想手动调用一个函数,必须要套入它设定的权限规则。 这对于临时排障简直是雪上加霜。如果又嵌套调用了另一个这样的函数,临时绕过都是个麻烦事。
确切地说,我提倡的是,权限和功能实现要分层。 先应用权限检查,过了这一步之后,功能函数就是自由的,任君调用。
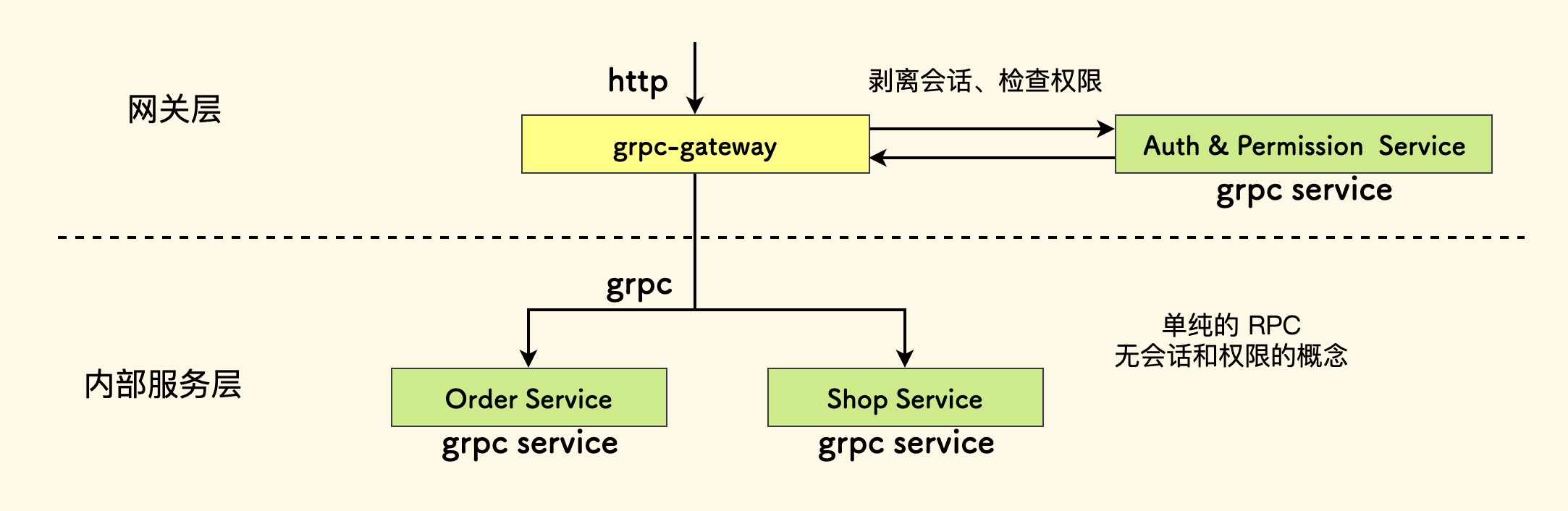
举例,在一个 SASS 系统中,请求流入到业务层的第一环,是权限检查和会话的剥离, 在下层的基础服务之间,不应存在任何和 权限、当前用户、当前会话 的概念。 一个功能函数应该是纯粹的、只关心它提供的能力。权限的事情,交给权限系统去负责。
具体一点,比方说这个系统内有一个 gateway 的服务把 http 请求转换到内部 grpc 协议, 而且 http 接口的定义、权限规则都会提前配置到这里:
- selector: order.v1.OrderService.UpdateOrderRemark
post: /v1/order/remark
body: "*"
auth:
token: true # 表示需要检查会话
permissions: order.update # 需要的 RBAC 权限码
set_field: # 注入 RPC 的字段
user_id: operator_id
请求流入后会交给权限系统,认证会话 和 权限检查,非法请求会直接拒绝掉。 过了这一层之后,就不存在会话和权限的概念了。
更进一步的讨论,权限一般分为两种:
- 功能权限:决定是否可以访问某个功能,能做什么。比如常采用的是 RBAC 模型。
- 数据权限:决定访问某个功能时涉及的数据范围。
对于前面的例子,我们可以做到功能权限的自动化。而对于「数据权限」,这通常很难,因为数据权限往往涉及业务理解。 比如,从数据范围上看,一个商家只可以访问自己门店的订单。但是这种检查并不可以简单地自动化完成,因为要先确认订单的门店、然后再确认门店归属的商家。 对于这种情况,仍然坚持和下层功能分离,一个做法是再加一层,手动剥离数据权限检查。
抽象归约 ¶
何为抽象?我认为,对于一批特征,定义一个概念的过程就是抽象。
编程语言都会有其自身的抽象机制,比如 C++ 中的虚方法和重载、Go 中的 interface 等。 其实就是定义一批抽象方法,后面再具体实现。
我认为抽象最大的好处在于,屏蔽实现细节,统一理解。
接下来,将分为几个部分:
抽象的一些例子
计算机中抽象无处不在,这里举几个经验性的例子。
第一个例子,是关于设计一个缓存机制中的存储容器的。比如我们要实现对一个函数的执行结果缓存一段时间的机制。
我们前面所说的「幂等」的概念,实现可以分为两种:
- 白盒实现:按业务逻辑去实现幂等。通过业务数据本身去检查行为是否发生过。
- 黑盒实现:不理解具体业务。比如,将上一次的执行结果存下来,下次访问时直接返回此结果。
第二种,也即一种「无脑幂等」效果,就是这个缓存机制可以做的事情:
@cacher.cache(3600)
def func(*args): ...
那么结果要存在哪里呢?可以是 threadinglocal、共享内存、Redis 等。现定义一个抽象容器,它要求实现者必须提供三个方法:
class CacheStorageContainer:
def set(key, value, expiration): ...
def get(key): ...
def expire(key): ...
缓存机制位于这个抽象容器的上层:
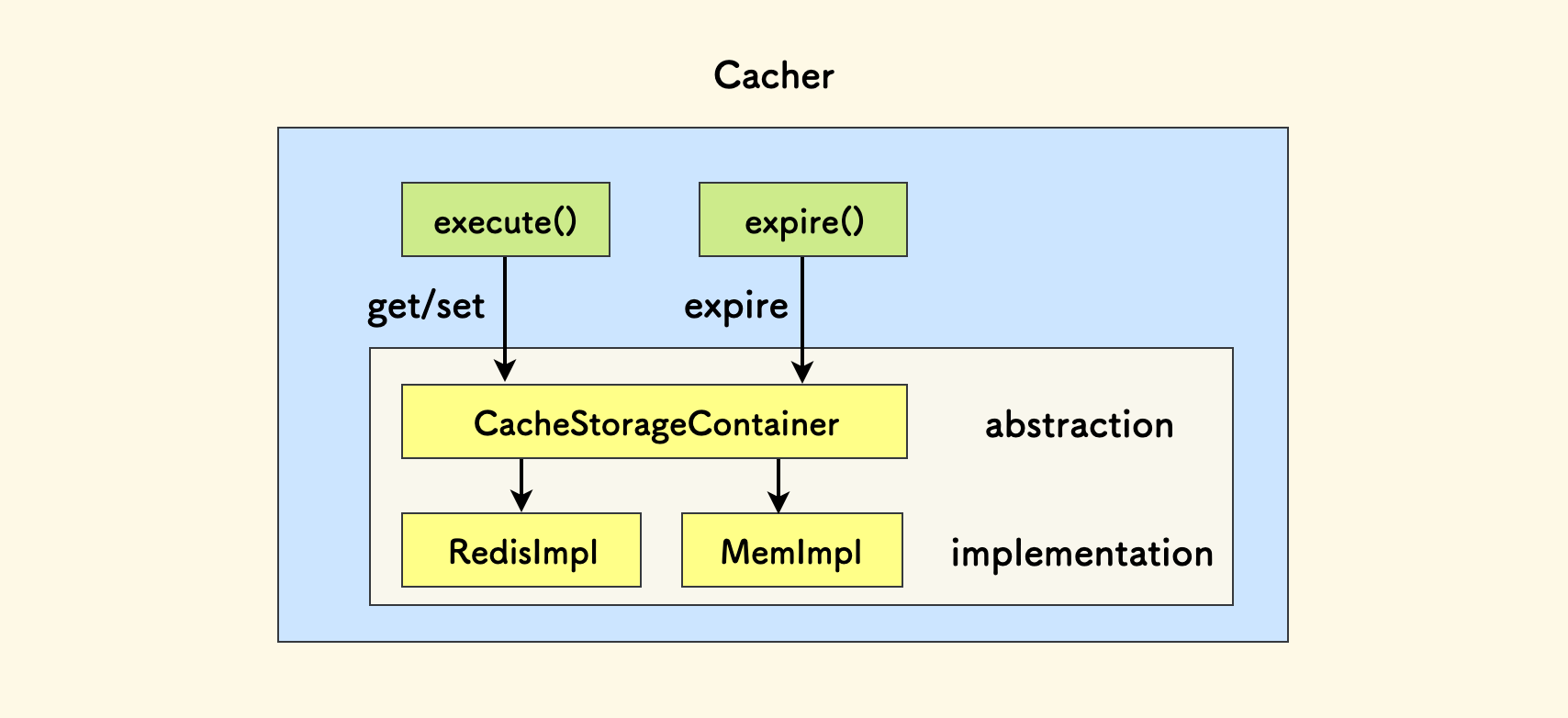
这样当实现上层缓存机制时,可以直接面向这个抽象的容器,而不用关心它具体的实现。调用者也可以自定义存储容器。
class Cacher:
def execute(self, func, args, expiration):
# 省略 encode func + args => key
return container.get(key) or
container.set(key, value, expiration)
cacher = Cacher(RedisCacheStorageContainer(redis_url))
另一个简单的例子,是关于一个通知系统的。它可以支持多种通道,短信、邮件 和 站内信。 这个通知系统还会实现 通知模板、通知订阅、广播 等上层能力,那么有必要对「通道」做一个抽象:
class Channel:
def send(self, to: str, message: str):
pass
不论上层如何施展,通道所提供的能力就是发送一段消息到一个目标。这个目标可以是一个 Email 邮件、也可以是一个电话号码、也可以是一个系统内用户的 ID 标识。 这个参数的具体含义需要通道实现方自己去解释。
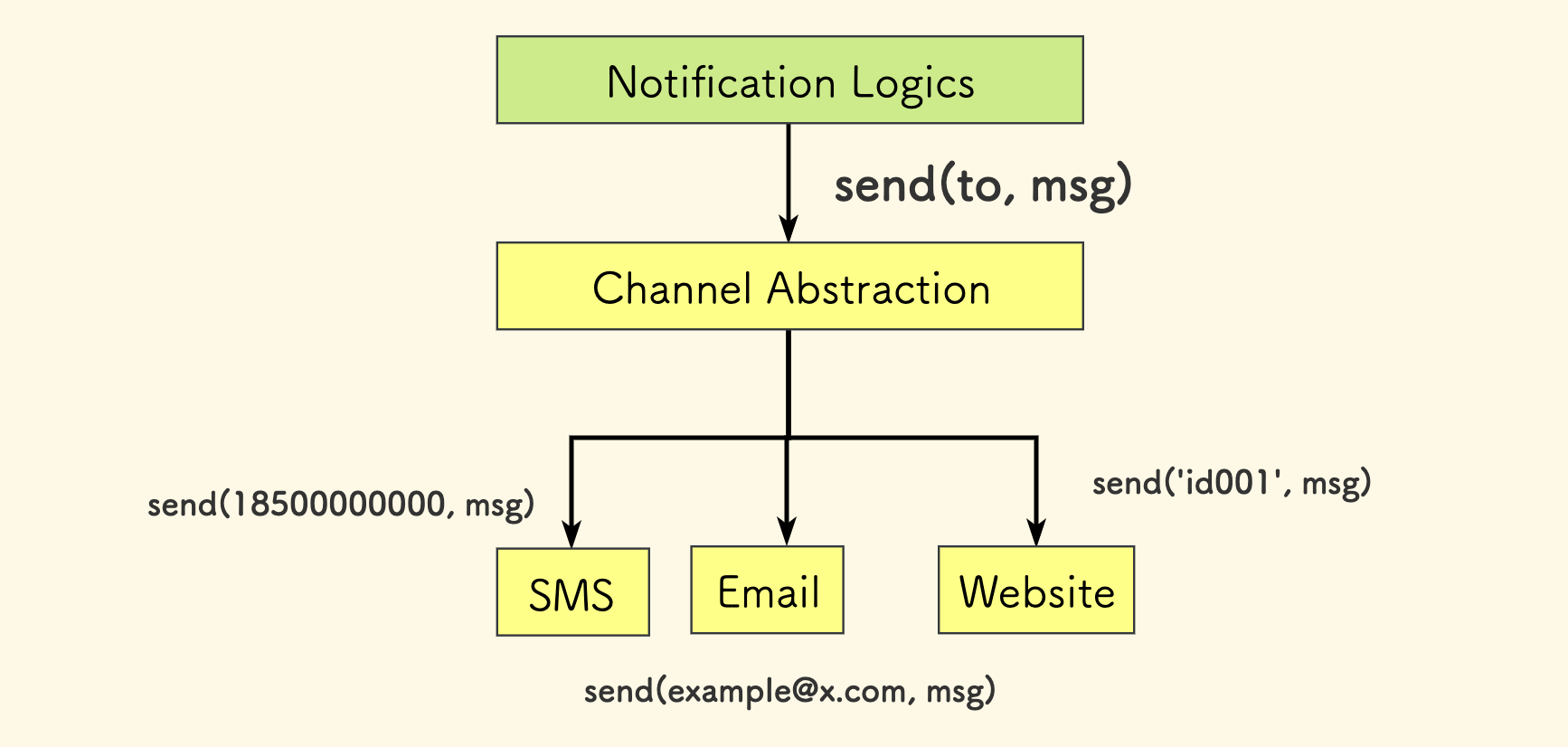
相比前一个例子的特别之处在于,抽象方法中的参数是具象的。这可能难以避免,但是必须坚持抽象。 解决具象参数的方法可以是,设计一个方法,它支持通过一个用户 ID 获取到其某个通道的通信地址:
def get_target(uid: int, channel_id: int) -> str: ...
这样,主过程代码仍然是面向抽象的。如果新增一个通道,除了要实现 Channel 这个抽象类之外,还要在这个方法这里注册一下。
再一个例子,来自我们开发的一个零售 SASS 系统。它对接了很多家零售平台的开放接口,比如说 饿了么、美团、抖音 等,但是业务流都是统一的。
我们肯定不会期望对各家都实现一遍代码,但是各家的开放接口又不一样。所以我们中间做了一层抽象,叫做 clientx,这个 x 字母的含义就是「未知」、「抽象」之意。 它定义了一套通用的抽象方法,然后对于各家平台,再去实现这些方法。
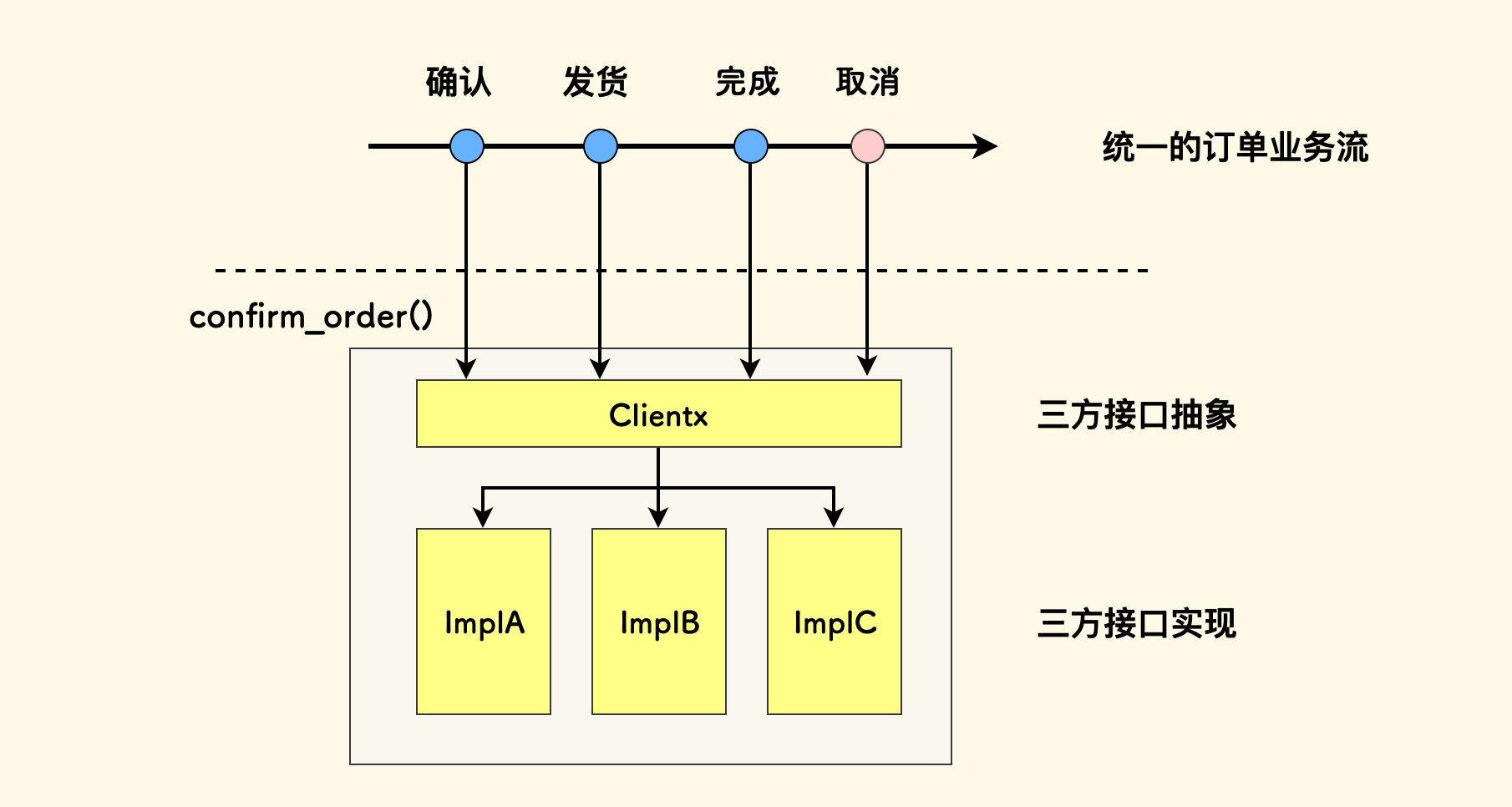
这样,每次新增一个平台的接入、修改一家平台的具体接口,都只会止步于这个抽象模块之下,上层业务流程则不受影响。 这种抽象机制在我们的系统中起了重要作用。每次我们修改具体平台的对接代码时,总会庆幸做了这样一层抽象。
有的时候,抽象的对象不是接口,也可能是其他的概念,比如说 状态机、事件节点、数据字段、通信协议 等。
举一个例子,仍然来自我们的这个零售 SASS 系统,它对接了多家零售/电商平台的售后业务,而各家的售后状态机设计地都不一样。 但其中不外乎三种对象:售后单据、货流、款流。再结合其中主流场景和功能(极速退款、审核、仲裁等),就可以设计出三个统一的状态机: 售后单主状态机、货流子状态机、款流子状态机。下图是一个示意性的说明:
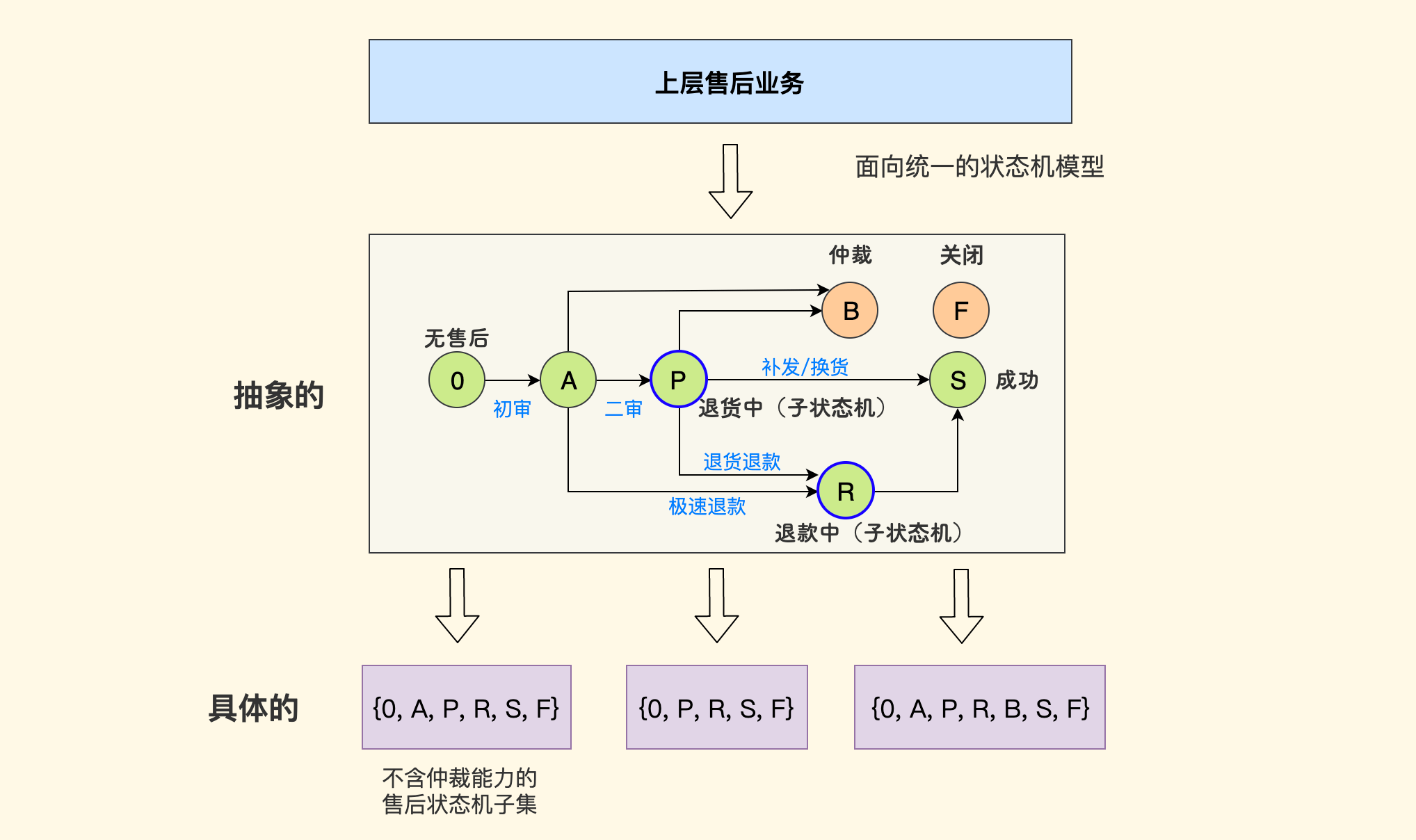
对于具体每一家平台的售后状态机,是这个统一状态机的一种子集。 对于上层业务模块而言,它们只需面向统一的状态模型即可,大大降低了复杂性。
总而言之,抽象就是要对不同的场景、不同的类型设计一个统一的模型,并且要让主流情况的适配尽可能地简单。
我的前老板说过一句让我记忆深刻的话,我觉得放在这里挺应景的:
避免体力活,现实场景和业务过多,所以不以场景进行划分。
如果我们关注的重点是上层的功能、而下层却存在 多种场景、多种类型 时,那么对其抽象就势在必行,不能恐惧多样化的具体复杂性。 通俗地说,避免把同一套代码写多遍。
维度归约
这一部分主要讲的思想是 降维。
一类例子是「效用/评分函数」,相反的方向叫做「代价函数」。简单来说,就是用一个数学表达式把多种维度的贡献综合到同一个维度上去。 最直接的就是 加权,然后 求和 或者 取最值:
Utility = Sum ( Utility_i * Weight_i )
比如说,游戏开发中的 效用 AI 决策, 一个 NPC 选择 治愈、攻击 还是 逃跑,可以先评估每种技能的贡献 再乘以 成功的概率,然后取最高者。
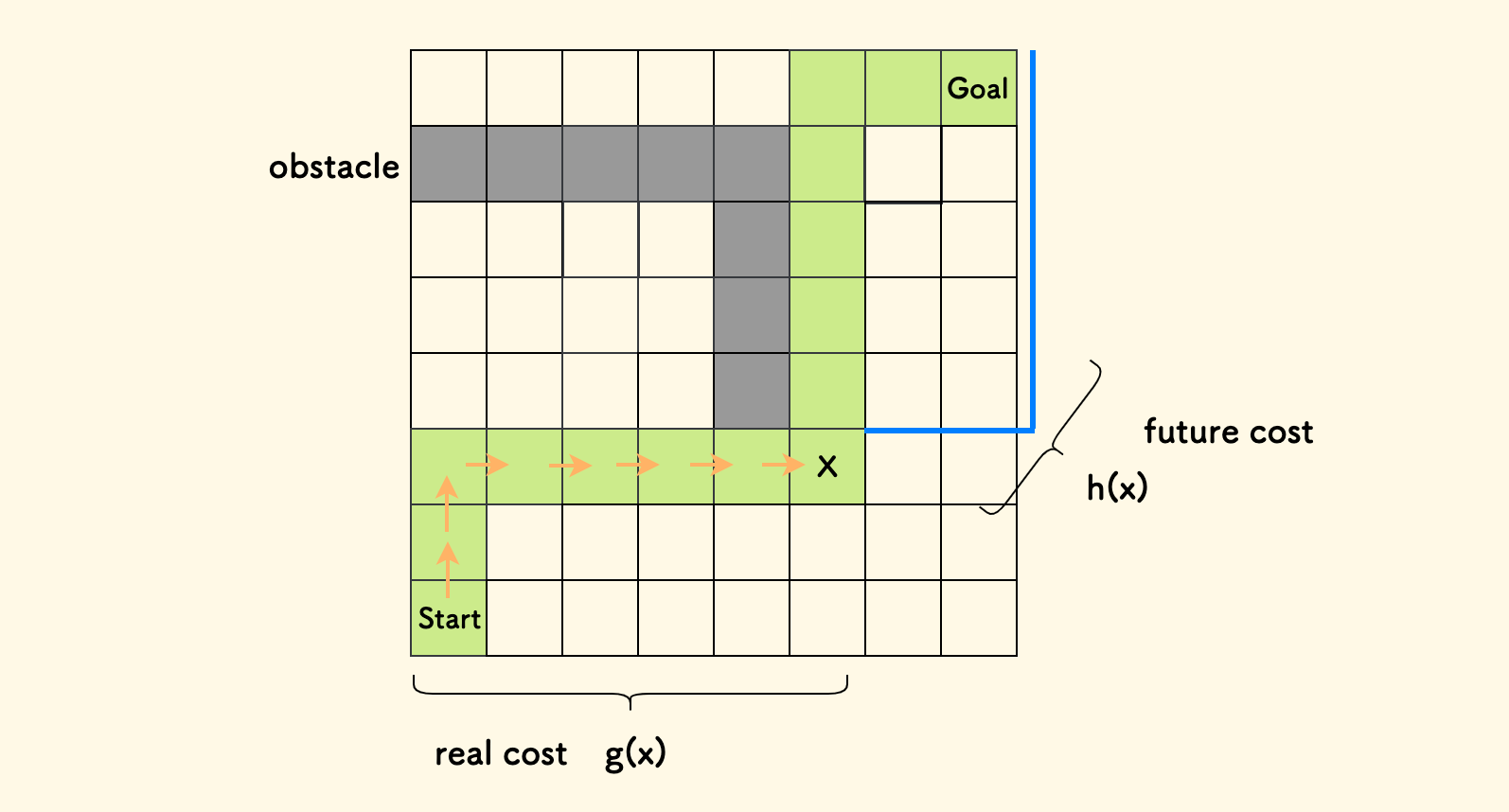
在启发式算法中,这种评价函数很常用,比如说,A-Star 寻路算法 中, 代价函数定义为,当前实际代价 g 和 未来估价函数 h 之和:
f(x) = g(x) + h(x)
这其中,实际代价是已经确定的、走到当前位置的路程,未来估价则是一种开放设计的启发式函数,估算当前点和目标之间的距离,你可以采用曼哈顿距离、也可以采用欧式距离。 f(x) 函数最终将二者统一,是一种平权求和,作为搜索队列的优先级。下图是一个采用曼哈顿距离作为未来估价函数的 A* 示意图:
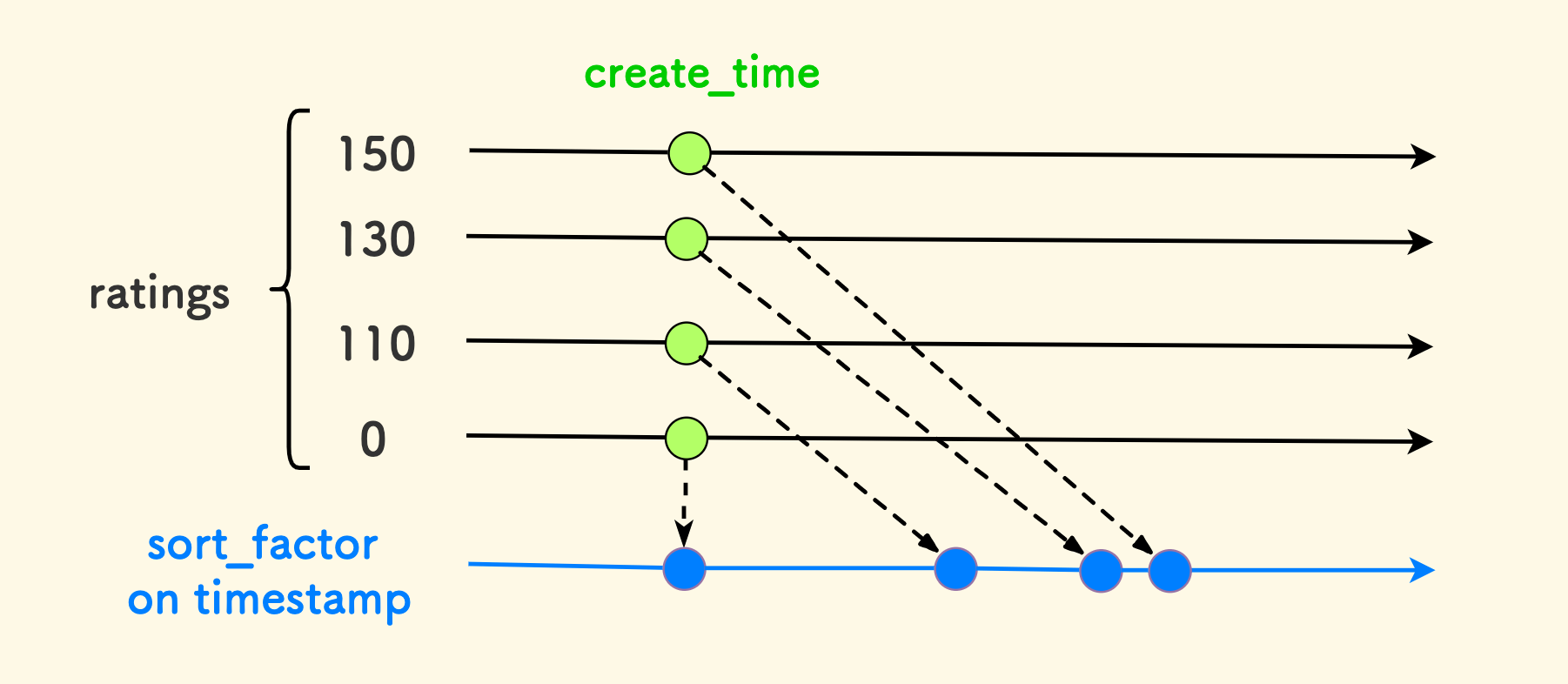
下面的例子更具体一些,关于 多维度排序, 比如,现在有一些文章,每篇文章有一个 点赞数 和 创建时间。我们希望点赞多的排在前面,但是对于高赞文章也不能长期霸占榜单, 时间长了要沉下去给新文章腾出来得到关注的空间。这里面有两种排序维度,我们可以把它们归约到一个维度上,可行方案有很多种。 比如可以设计这样一个字段:
delta_30days = 30*24*3600
k = delta_30days * 2.0
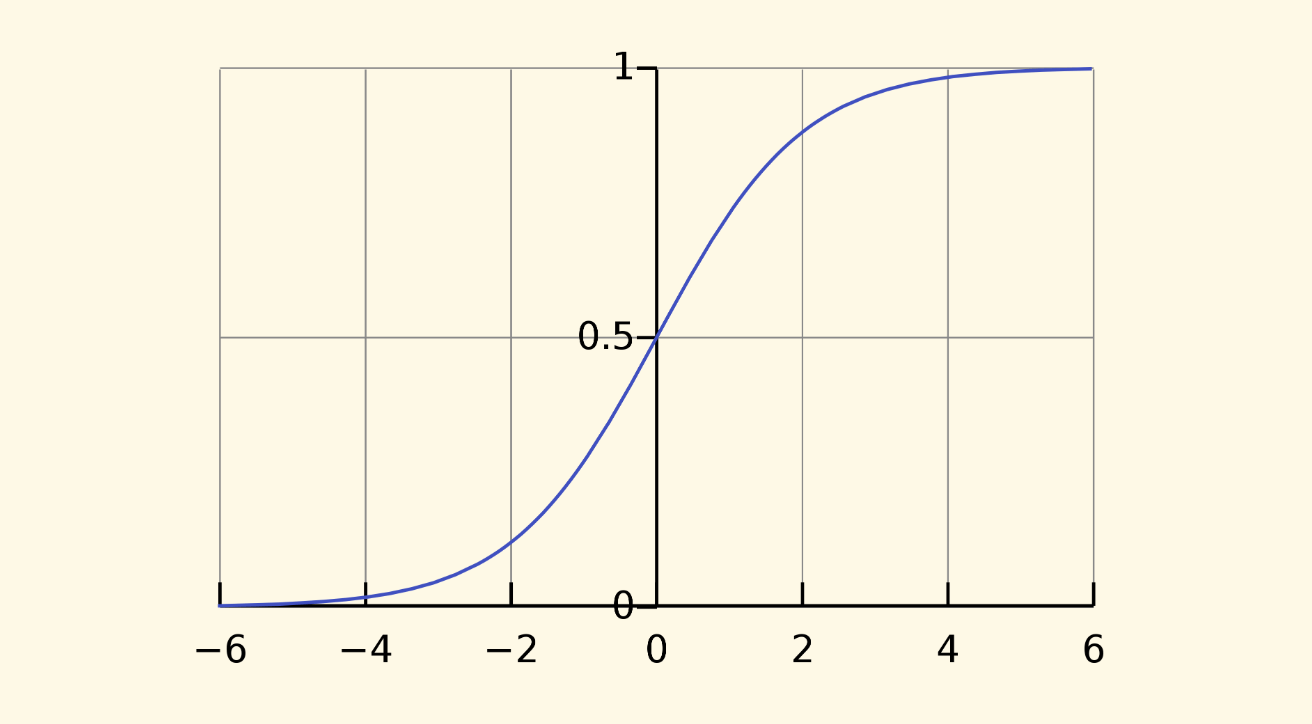
sort_factor = logistics(1000, ratings) * k + create_time
其中 logistics 是 逻辑斯谛函数, 当变量 ratings 越大时,它的函数值越接近 1000,但是增长速率会越来越缓慢。 如果你希望限制某个维度无休止放大的贡献,可以考虑这种函数。
这实际上是把点赞数这个维度的影响投射到了时间维度上:
- 如果一个文章的点赞数是
0,那么排序标准就是创建时间本身。 - 如果点赞数为
100,那么在一定天数之后,它对排序的影响等效于一篇新创建的无赞文章。 - 如果点赞数非常高,那么
logistics函数会刚性限制其影响的上限,并且点赞数越高,其对排序贡献的增长越缓慢。
同时,计算式中唯一的自变量是 ratings,也避免了使用 now() 函数,就是说,除非文章被点赞,否则这个字段不需要更新。 意味着你可以放心地把它存储到数据库中,它的值不随时间而变化,排序也不需要引入实时计算。更具体地说,可以用它来建立一个数据库的索引来排序。
从这个例子中,对于计算表达式类型的多维度归一设计,有几个总结点:
明确函数关于每个维度的变化趋势、线性 和 非线性 变化。
为限制贡一个维度贡献的速率,一种方式是对它应用 logistics 函数。
- 函数的因变量有几个。函数值是否跟随时间而变化,这关乎它的固化存储策略。
选择一个有意义的维度进行投射。
方式之一是选择一个维度,然后把其他维度投射到这个维度。
本文中 维度归约 的概念并非专指上面数学表达式的方式。下面是一个例子,在我们的仓库管理系统中,库存有多种维度,最常用的是这两种:
- 效期:有效期内、临期、过期
- 品相:良品、残次品、以及具体的品相等级
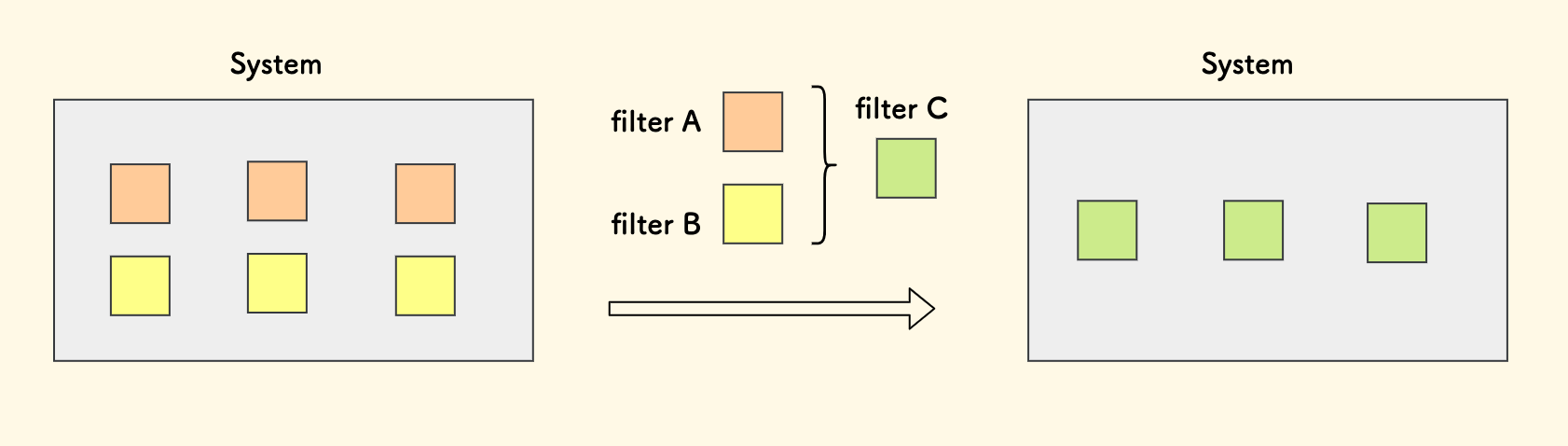
当然具体的还有其他维度,比如说 批次、易碎品 等。 那么,在前端售卖时,不同类型的库存,会定义不同的商品链接 和 售卖价格,在 实际出库、库存计算、补货计划 时,会对应不同的库存条目。 这造成的问题是,在系统的不同模块中,都会有一些多种维度来筛选库存的逻辑。说白了就是,一大堆相似的筛选条件,散落在系统的各种函数中。
但是这其中大多数是高频筛选,比如说「良品正常效期」、「良品临期」等。这意味着实际中用到的筛选组合并没那么多。 因此我们设计了一个叫做「库存筛子」的概念, 把多种筛选条件的组合定义为一个新的维度「筛子」、实际就是一个字符串。 系统中所有涉及这些筛选条件的地方,都可以替换成一个「筛子」,前端表格、后端参数 都变得简单起来,统一了理解,也避免了繁琐的重复代码。
抽象是有成本的
抽象是有成本的,这是指要把抽象的概念解释到具体的实现时,往往会引入额外的中间调用、格式转换等开销。 我们更关注的是运行时的开销。 你或许听说过「零成本抽象」的说法,它强调 在进行抽象设计时不应该引入额外的开销。 确切地说应该是无运行时开销,因为对于编译型语言,可以把抽象开销尽可能地向编译期转移。 C++ 是强调零成本抽象的典范,比如说 inline 内联机制、C++ 模板 等, 使用 vector<int> 和直接实现一个整型的 vector 在运行时没有什么区别。代价则是,编译时间的延长。
抽象的核心总结
在本章节的最后,总结一句话: 面临 多场景、多类型、多维度 的情况,考虑抽象,统一理解。
冗余设计 ¶
冗余是指 为抵抗可以预料到的错误而设计的多副本机制。
核心理解:
- 可靠性依赖的是冗余。
- 冗余只能处理可以预先料到的错误。
- 冗余可能会引入竞争。
计算冗余也可以说是「时序冗余」,典型例子是 补偿机制,即 「晚点再试一次」。 比如说,某个任务处理失败,当前不想立即重试,那么可以提前准备一个补偿时序, 对 失败 或者 长期未处理 的任务进行 重试 或者 降级处理。 补偿机制在后端中用的非常多。 此外,正如前面 时序的概念 章节中所说过的,补偿也可以设计多阶梯时效。
如果一个补偿机制设计的很简单,比如说每五分钟跑一次所有待处理的任务,那么它可能会和主处理时序竞争。 多阶梯的补偿时序之间如果没有合理划分处理对象、也可能有竞争:
- 首先,重试务必考虑幂等。
- 其次,必要时可以 加锁 或者 用队列来分发。
存储冗余就是说把数据存储多份副本、来预防数据损坏的故障。 一个典型的例子是分布式系统中的 故障转移策略 (failover) 。 比如说,在一个采用 哈希环算法 的分布式存储服务中, 一份数据不仅会写到它的目标节点上,还会在下一个邻居节点中存储一份副本。那么,一旦原节点发生故障,对于此数据的请求可以直接沿哈希环转移到下一个节点继续服务。
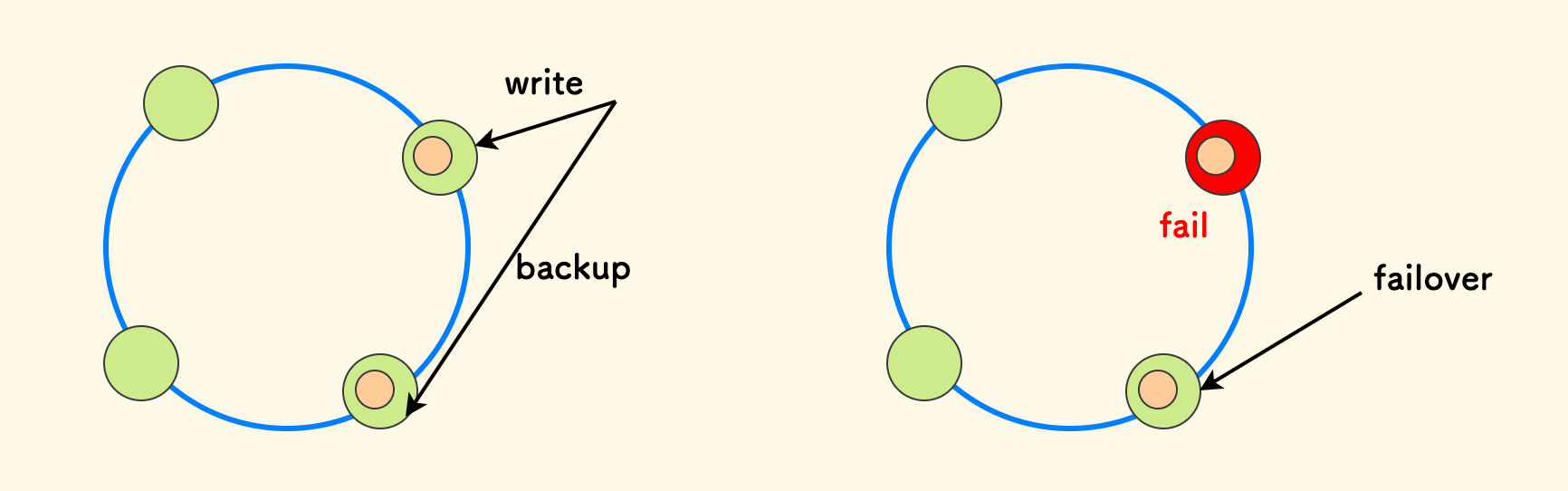
数据存多份会带来的问题就是,多写的一致性问题,这无法根本避免,引用 CAP 原理:
在实际的分布式系统设计中,我们无法同时达成强一致性和高可用性。
这其中主要是说一致性和响应时长之间的关系:
- 同步写多份副本,才会有更好的一致性。但代价就是更长的响应时长。
- 如果改用异步写,一致性就会减弱,好处是响应更快了。
存储冗余带来的另一个的问题是 数据迁移。试想,一个损失的节点要想恢复回来,那么它要追赶上这期间错过的数据写,要从备份节点迁移数据,直到对齐了, 再执行切换,变为原本的主备关系,恢复如初。
另一个例子是 通信协议中的 Checksum 校验码,常用的是 CRC 算法。 比如把校验码放在一个数据包的末尾,在解码协议主体内容之前,先计算其 CRC 是否和传输来校验码一致。 如果不一致,说明数据包发生了损坏。

上面说的校验码只具有错误检测能力,没有数据校正能力。 有一种很巧妙的数据校正方法,即采用所有字节的异或值,如果我们知道具体哪个字节损坏了,就可以恢复回来。 因为异或有一个神奇的性质,比如说下面的示例中,如果知道 B 是损坏的,只需要用校正码 S 和其他字节的异或值来恢复它:
S = A ^ B^ .... ^ X
B = S ^ A ^ ... ^ X
除此之外,我认为 有的场景,冗余设计还会把问题变简单。 比方说在数据表中冗余其他表/其他系统内的字段,这样会使得查询更简单。 尤其是,要做一个数据统计型的系统时,它要汇总各个子系统中的数据,这种情况下把数据冗余到一个大宽表中是个不错的选择。 当然,此时也需要关注随之而来的一致性问题。
总之,冗余设计的主要目的是容错。它的思想很简单,多副本策略,鸡蛋不要放在一个篮子里。
算法的纯粹性 ¶
对于具有一定复杂性的逻辑,我觉得都可以叫做算法。在技术方案中,如何表达一个算法是没有固定形式的,只要讲的清楚就好。
三个注意点:
- 清晰地定义问题。
- 清楚算法的最好和最差情形的发生条件和表现。
- 建议把算法单独放在一个模块中,和数据、IO 和 其他业务逻辑分开。 它的改动频率应该会很低,而且这样方便测试。
其中第三点,就是本章节所讲的,即 保持算法模块的纯粹性。
延续前面拆单的例子,如何把一张订单拆分为最多 K 张子单到不同仓库,使得总配送距离最低。 这是一个组合爆炸问题,可能的优化是,先排除完全没有相关库存的仓库, 然后我们再做一个评价函数:
Score = 库存缺口率 ShortageRate X 距离 Distance
取出得分最优的前 Q 个仓库,最后再做暴力组合, 也就是从 Q 个仓库中选出最多 K 个仓库,依次尝试后取最优。
在这个例子中,整个实现可以放入一个单独的模块中,只需暴露一个接口。 它不会查询依赖数据(比如说订单数据、仓库数据、查询地图等),这些需要调用者来输入, 它只负责做计算。这个算法模块会非常纯粹,也方便对正确性和性能做测试。
批量化 ¶
当我们要处理一批任务时,存在两个维度:任务的步骤 和 任务的规模。 下面我们把步骤作为纵向维度、规模作为横向维度,那么有两种分解方式:
横向切分:每个步骤分别有一个函数来批量处理,再串联起来。

用代码来描述这个方式就是:
def step1(): for task in tasks: ... # handle step 1 step1() step2() step3()纵向切分:做一个函数处理一个完整的任务,然后批量调用。

用代码来描述这个方式就是:
def func(task): ... # handle step 1 ... # handle step 2 ... # handle step 3 for task in tasks: func(task)


我的理解是:
- 如果某一步骤的集中处理可以提升性能,选用横切。
- 否则,都应该选用纵切,因为它更简单。尤其对于步骤很多的情况下。
- 并非绝对地选择一种,可以混用。
在带有 IO 的情况下,横切更合理。比如说,要处理一批订单,先把订单批量查出来、然后再做计算比较好。 如果在处理单个订单的函数中一个一个去查,会很慢。我优化过很多类似的代码,bad case 大概是这种样子:
def func(task):
query_sth() # 单个条目的 IO 查询
for task in tasks:
func(task)
但是,如果处理的步骤比较多,我们可以应用前面说的 计算 和 IO 分离 的设计方法,先把依赖数据都准备好, 然后集中在一个函数中处理:
def prepare():
batch_query() # IO 查询
def calculate(task): # 计算单个任务
... # step1, step2, step3
prepare()
for task in tasks:
calculate(task)
在纯计算的处理中,选用纵切的方式更简单。如果任务数据在内存中是有序排布的,这种方式还会更有利于缓存。
如果加入并行的因素,横切的方式就是流水线模式,一类处理器只处理一个环节。这依赖于高度的协调。
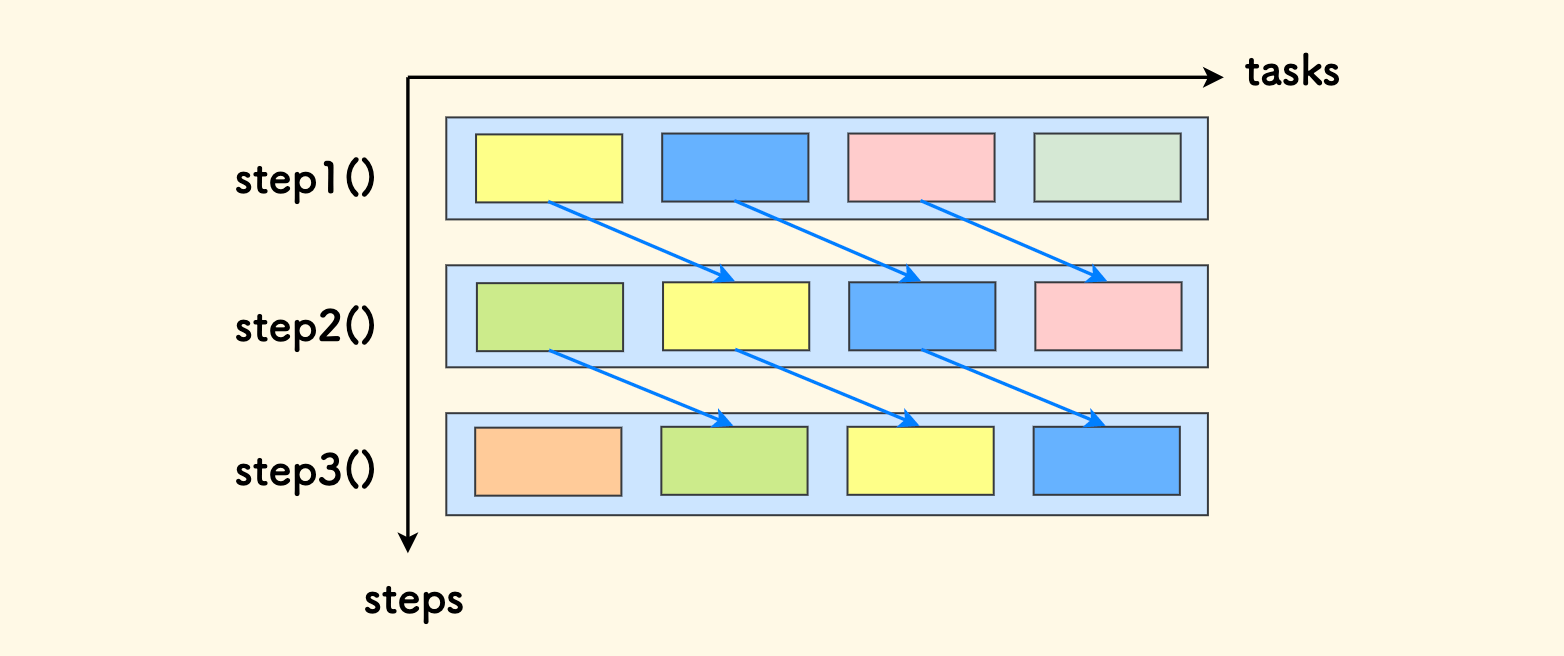
而纵切的方式下,所有处理器都具有相同的能力,各自互不依赖,架构模型可以设计的很简单,方便扩展。 《通灵芯片》 中也更推崇这种方式,叫做「数据的并行分解」:
现在我已明白,安达尔论证中的缺陷在于其假设:整个计算中的一个固定的部分,哪怕只有10%,必定是顺序执行的。 这一假设貌似有理,但对于大多数大型计算机来说却是站不住脚的。安达尔的这种错觉源于对如何使用并行处理器的误解。 比如,一组人一起漆栅栏,让一人开漆罐,一人清洁表面,一人油漆,另一人洗漆刷。这种功能划分需要高度的协调。 这种协调达到一定程度后,再加入更多的人也无助于加快施工的进度。 使用并行计算机,一种更为有效的方法是使每个处理器执行相似的工作,但使用不同部分的数据,这种方式称为任务的数据并行分解。 好比漆栅栏,每人各管一段。这样,速度的提升几乎与处理器的数量成正比。
通信 ¶
我对通信的理解相对有限,只能给出一些感悟。
大部分情况下,Web/RPC 后端方向是不需关心这一章节的。
通信的可靠性代价极高。
TCP 是极其复杂的,原因在于网络通信中的三个万恶之源:丢包、乱序 和 延时。 我曾写过一篇文章 《TCP 协议原理总结》。
可靠性的代价有:更大的运行时开销、等待 和 重传,所以在通信设计时,选用 TCP 还是 UDP 并不是一成不变的。 在一些实时系统中(游戏、机器人、视频),低延迟更重要,在一些场景下 丢包是可接受的,此时可以选用 UDP。
通信的方式是否双工。
双工通信是说,允许通信的双方同时发送和接收消息。我们知道 TCP 和 UDP 都是双工的,但是 关键在于应用层的设计是否利用了双工机制。 我曾经在帧同步的通信设计中,经常采用 Ping-Pong 模式,就是 「一问一答」的方式,一方发给另一方一个数据包,然后另一方回复一个数据包。但是这种方式是低效的, 因为每一方都在等待对方:

而采用全双工的方式是说,发送 和 接收 不要互相依赖,避免等待。 一方面,如前面的 读写分离 章节中所提到的,全双工通信机制的充分利用是要分离收发时序的; 另一方面,也不要等待对方的收发。每一方都按时间帧尽情发送,数据的发送不去要去等待对方的数据包。

数据包不要过大。
对于实时通信应用而言,在满足协议功能的要求下,尽量让数据包设计的小。因为:
- 数据量少、传输时间短。
避开 IP 层拆包,数据包的大小尽量小于 MTU。
按 MTU 拆分后的任何一个小包丢了之后,整个数据包都会被舍弃。
- 小包避免拥塞优于大包。
通信会拉低系统性能、共识优于通信。
这句话的意思是说,要避免在 多个子系统、或者 多个智能体 之间做过多的通信来实时地协调决策, 依赖事先设计好的共识性的规则的方式更好。简而言之,不要过多地依赖通信来协调决策。 这好比几个人在玩游戏一样,每一方都了解自己要执行的规则,而无需在运行时再去沟通协调。
在计算机中,有一个叫做 鸟群模型 (boids) 的例子, 用来对一群智能体来模拟鸟群的行为,每一个智能体都遵守相同的几个规则:
- 分离:避免和附近的个体碰撞。如果离的太近了,就远离。
- 对齐:和附近的个体保持相同的平均速度和方向。
- 聚合:朝附近的个体的中心移动。

图片来自 https://lib.rs/crates/bevoids 具体的规则可以更多、也可以修改,比如说可以添加几只领头鸟进去。 但是基本思想就是这样的,每个智能体应用局部的规则,而无需实时的协调通信。就可以实现类似鸟群的运动效果。
在我做过的多个机器人之间的协作也是这个道理。不会去选择一个全局决策者,因为通信的不可靠性质,这个决策者的视角不一定准确, 而单点决策出错会影响全局。另外更不可能让 N 个智能体互相协调,那会是 N^2 平方级的复杂度。 如果每个智能体都遵守事先定好的规则,观察其他个体来做决策,每个智能体的通信仅限于观察周围的环境信息,整个群体会自然涌现出来效果。 又因为每个智能体只会决定自身的行为,整体出错的风险大大降低。总而言之,这样做更简单、也更健壮。



错误 ¶
错误也是设计中的一环。几点理解简述如下:
尽可能避免抛出错误。
Exceptions adds complexity.
错误是增加复杂性的。
-- 《A Philosophy of Software Design》 因为底层模块每抛出一个错误,意味着上层调用者可能要增加一个处理此错误的逻辑。
Define errors out of existence.
错误最好不要存在。
-- 《A Philosophy of Software Design》 定义一个错误时,可以重新思考,是否可以通过修改实现的方式,规避掉原本要抛出的错误。或者是否可以在实现中处理掉这种错误。 背后的意思是一种向内闭环的思维,函数的实现者应尽其所能把错误消灭掉,而不要向上把问题都抛给调用者。
包装并转发错误没有实质意义,处理不了的错误就让它抛出。
定义一个新错误,然后把底层发生的错误包装一下,透明抛给上层,这和透明转发接口是一样的,没有实质意义。 因为这个新的错误不属于你要实现的功能,而是来源于下层。
如果来自下层的错误,我们无法处理,那么不要管它,让它自然的向上抛。不要去包装它,画蛇添足,尤其对于致命错误:
Let it crash.
比如说,如果申请一块内存时,遇到了
bad_alloc错 误,但是这个对象的创建又是必须要进行的,此时就只好让它抛错(崩溃)。知乎上有一个有趣的问题:为什么还是有很多 C++ 程序员在 new 之后判断 null?
把一个模块的错误分类。
我比较推崇最好把异常的类整理成一颗继承树,方便上层调用者按类来捕获。比如说:
class Error(Exception): ... class UserError(Error): ... class SystemError(Error): ... class UnknownError(Error): ... class TimeoutError(SystemError): ... class NotFoundError(UserError): ...在没有异常机制的语言中,比如说 C 语言,严格来说 Golang 也是一种(它的
panic只代表致命错误),是采用返回错误码的方式来报告错误的。 不过,我认为异常+捕获的设计表达力更强。在 C++ 中,由于异常抛出涉及资源清理问题,有一个异常安全的说法,在 C++ 领域用不用异常机制是一个有争议的话题。 知乎 - 对使用 C++ 异常处理应具有怎样的态度?错误是否值得重试的考虑。
错误处理的方式无外乎三种:抛出、处理(或忽略)、重试。
前两点已经说明了,能处理的要处理,不能处理的直接抛出。
那么何时重试呢?对于应用级别的程序(相对于 库、底层框架 而言),重试策略是很常用的。 如果错误有希望在短时间内得到解决,比如一些系统性错误(网络超时之类的),重试是有意义的。 但是对于一些业务错误,比如资源不存在,重试大概率是没有意义的。
结尾语 ¶
终于写到了最后。 这个话题、我其实有思考过写多篇,还是写一大长篇。 选择后者,是因为不想把文章铺的太开,内聚而紧凑的方式应该是写一篇文章。
设计一个系统要关心这么多概念吗?当然不。这只是一篇我个人的经验和感悟的总结。
系统设计要因地制宜,看具体的 领域、功能 和 场景。简单的可以很简单、复杂的也可以很复杂。 系统设计是一个庞杂的话题,而且其中的原则并非是绝对的,要看情况。
仁者见仁、智者见智。最终还是实践出真知。
(完)
相关阅读:系统设计中的心态和意识。
本文原始链接地址: https://writings.sh/post/system-design
