本文记录一到叫做「区间和的个数」的问题。
来自 leetcode 327. 区间和的个数,描述如下:
给定一个整数数组,求其中区间和的值在一定范围内的区间个数。
区间
[i,j]上的区间和是位置i和j之间的元素之和,包括左右端点i和j。
笔记目的,行文从简。
包括四种解法:
初步分析 ¶
首先,可以先计算出来原数组的前缀和:
预处理前缀和数组 C++
using ll = long long;
ll sums[n];
sums[0] = nums[0];
for (int i = 1; i < n; i++)
sums[i] = sums[i - 1] + nums[i];
任何一个区间和,都可以表示为两个前缀和之差:
sum[i..j] ← sums[j] - sums[i-1]
特殊地,当 i=0 时认为 sums[i-1]=0。
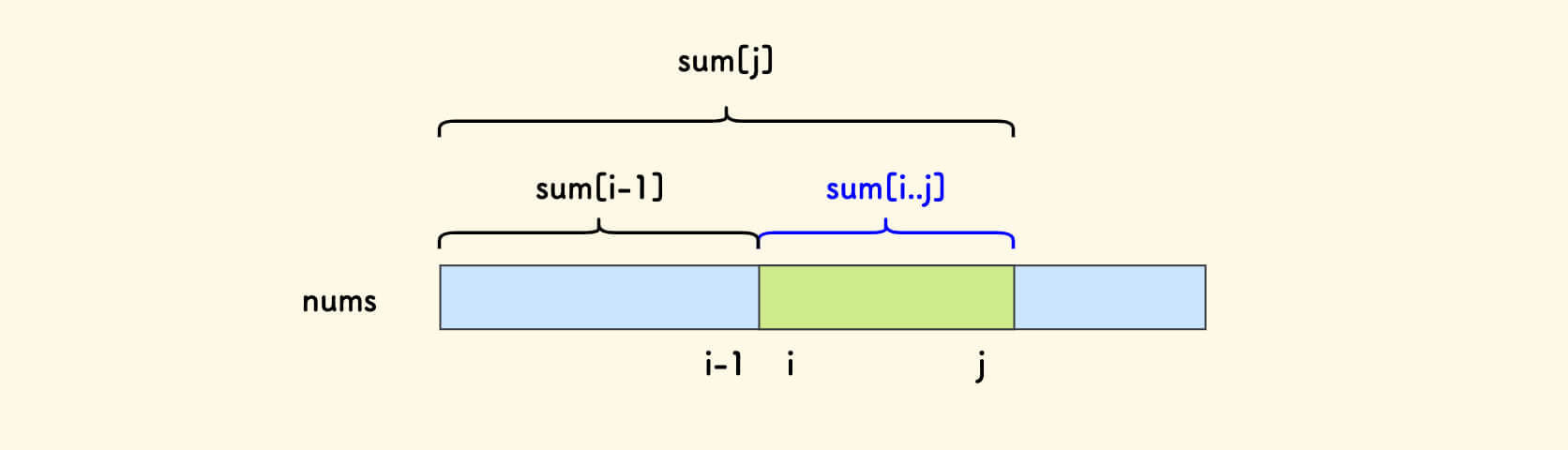
这样,问题即可以转化为:
在前缀和数组中找出差值在给定范围内、位置不同的两个元素的对数。
进一步地,转换为:
对于每个左端点
x,从其右边找 满足值在范围[lower+x, upper+x]内的右端点y的个数,进行累加。
找 y 的过程,有个左右界的限制, 所以考虑用「有序」结构来存储前缀和,以方便二分。
最初的想法是:从后向前扫描前缀和数组,枚举每一个左端点 x,用一个有序表对出现过的前缀和进行计数。 同时按上下界查询有序表,汇总符合条件的右端点 y 的个数。
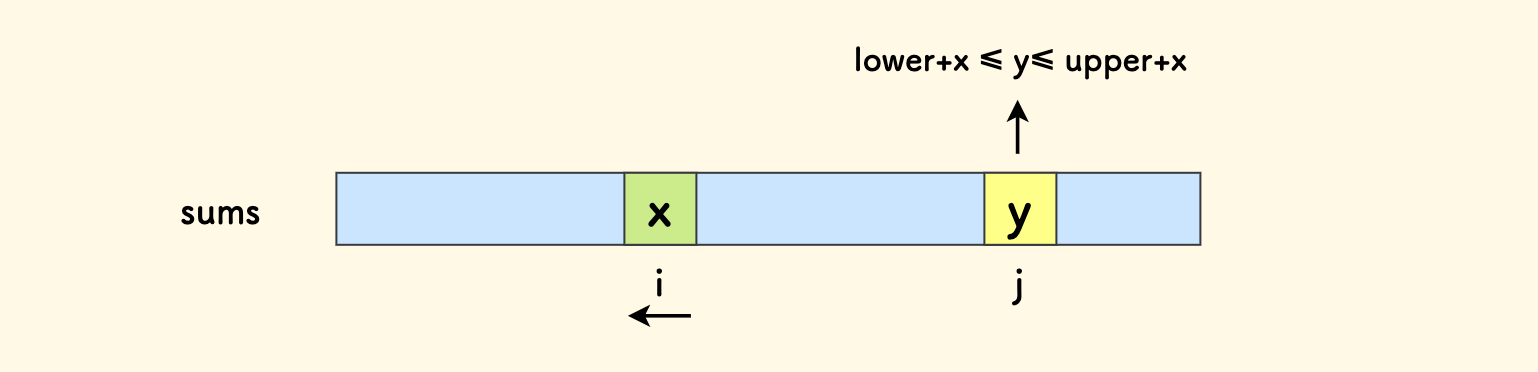
在 C++ 中有序表就是 map,代码如下:
初步分析 - 使用 C++ map 的 $O(n^2)$ 方案
map<ll, int> counts; // 统计: 前缀和 => 出现次数
int ans = 0;
// 对每个 x = sums[i],找右侧已经出现过的 y
for (int i = n - 1; i >= 0; i--) {
counts[sums[i]]++;
// 找出 y 的左右界
ll x = (i == 0 ? 0 : sums[i - 1]);
ll l = lower + x, r = upper + x;
auto left = counts.lower_bound(l),
right = counts.upper_bound(r);
// 汇总个数
while (left != right && left != counts.end()) {
ans += left->second;
left++;
}
}
注意,C++ map 中 iterator 不是一种 RandomAccessIterator, 左右界无法直接相减求数量,只好依次迭代,所以「汇总个数」的过程时间复杂度是 $O(n)$。
因此,此实现的时间复杂度只能是 $O(n^2)$,提交后发现会超时。
下面尝试优化这个时间复杂度。
树状数组解法 ¶
延续前面的思路框架,「汇总个数」的过程其实是一种「区间查询」,计数累加其实是一种「单点修改」, 那么第一种优化方案就呼之欲出了,即用树状数组来代替有序表来维护计数。
事实上,计数问题,可以理解为一种求和。
关于树状数组本身的原理,本文不再说明,可以参考文章 《树状数组的原理》。
考虑使用树状数组的时候,都要先理清其要维护的信息。 即 sums 数组中每一个值 s 的出现次数 count[s],所以要在其值域上建立树状数组。
先假定 s 的值都是正整数,以方便推进思路。
考虑其中不大于数字 val 的 s 的出现次数, 它实际上是 count 数组上的计数前缀和:
// sums 数组中 <= val 的元素个数
count[1, val] = count[1] + count[2] + ... + count[val]
进一步地,在值域范围 [l,r] 内的 s 的个数可以表达为两个计数前缀和之差:
// <= r 的个数 减去 <= l-1 的个数
count[l, r] = count[1, r] - count[1, l-1]
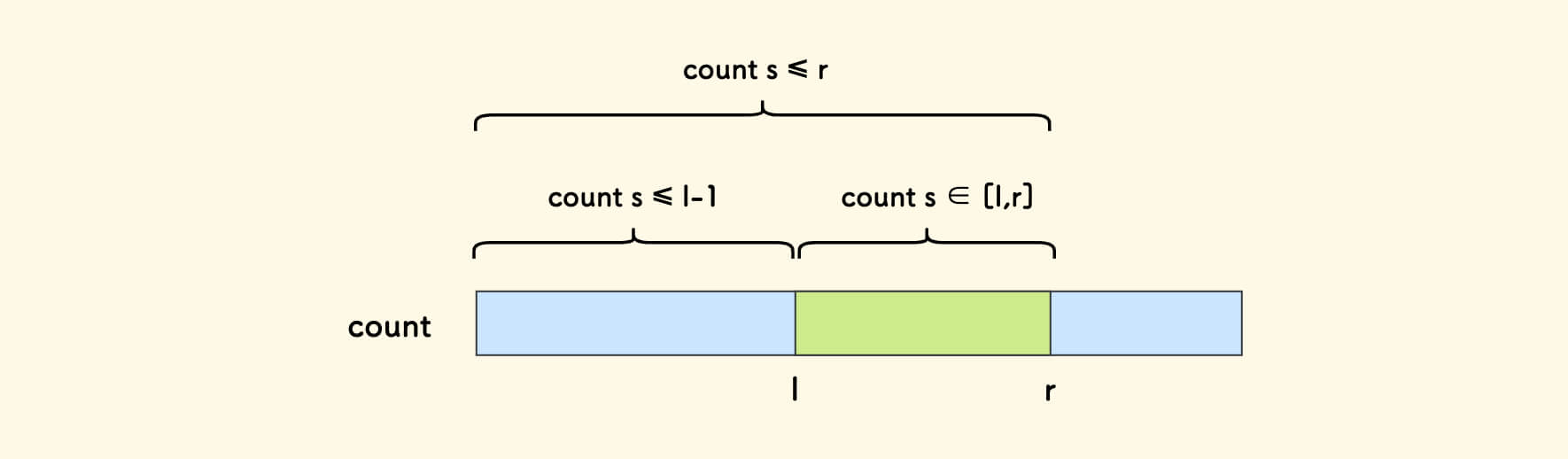
使用树状数组维护 count 数组,接 「初步分析」 中的思路:
- 仍然从后向前迭代前缀和数组
sums。 - 对于每一个前缀和
s,计数加一。 当前迭代的
s作为目标区间的左端点x。右端点
y的左右界应该是[lower+x, upper+x],两次查询树状数组, 求差值即是符合条件的y的个数。
用树状数组来维护 count 数组 - C++ 代码
BIT b(N); // 维护计数数组的树状数组
for (int i = n - 1; i >= 0; i--) { // 从后向前
b.add(sums[i], 1); // 单点增加, 计数
ll x = (i == 0 ? 0 : sums[i - 1]); // x
ll l = lower + x, r = upper + x; // y 的左右界
int c = b.ask(r) - b.ask(l - 1); // [l, r] 内的 y 的计数
ans += c;
}
但是还余下一个问题:需要先对 sums 数组进行离散化处理[1],树状数组要求下标是正整数。
其实只关心每个 s 的出现次数,而与其具体大小无关, 即 可以用一个正数来代表真实的 s 进行计数。 要注意的是,离散化的时候,不止要考虑每个 s,也要考虑左右界 lower+s 和 upper+s,因为它们也参与树状数组的询问。
对前缀和数组 sums 进行离散化处理 - C++ 代码
// sums 离散化,用离散化后的数据来代表计数
// 离散化技巧: 也要把 s+lower 和 s+upper 放进去
set<ll> st;
for (auto s : sums) {
st.insert(s);
st.insert(s + lower);
st.insert(s + upper);
}
st.insert(0 + lower);
st.insert(0 + upper);
// 离散化前的数据值 => 映射到具体的大小
// 用树状数组的话,映射到 1 起始的值域
unordered_map<ll, int> mp;
for (auto s : st) mp[s] = mp.size() + 1;
// 后面使用 mp[s] 来和树状数组交互即可
原来使用 map 计数的时候,单点修改的时间复杂度是 $O(1)$,但区间查询的时间复杂度是 $O(n)$。
换成树状数组后,单点修改 和 区间查询 的时间复杂度都是 $O(\log{n})$,降低了时间复杂度的瓶颈。 整体时间复杂度降低到了 $O(n\log{n})$ 。
最后,树状数组解法的完整实现见 GitHub 链接: 区间和计数问题 - 树状数组 - C++ 代码实现
平衡树解法 ¶
和树状数组一样,平衡树是一种使用数据结构来优化的手段,这里采用 fhq treap。
「初步分析」 说过采用 C++ 中 map 的问题在于,汇总范围内的前缀和数量的时候,复杂度是线性的 $O(n)$。 而 fhq treap 却很擅长「统计给定范围内的元素数量」的这种问题。
前置知识:fhq treap 本身的结构和原理 [3]。
fhq treap 的核心操作 split 会依据一个给定的数值 v,把树分成两个子树, 使得左子树中所有节点的权值全部不大于 v,右子树中所有节点的权值全部大于 v。
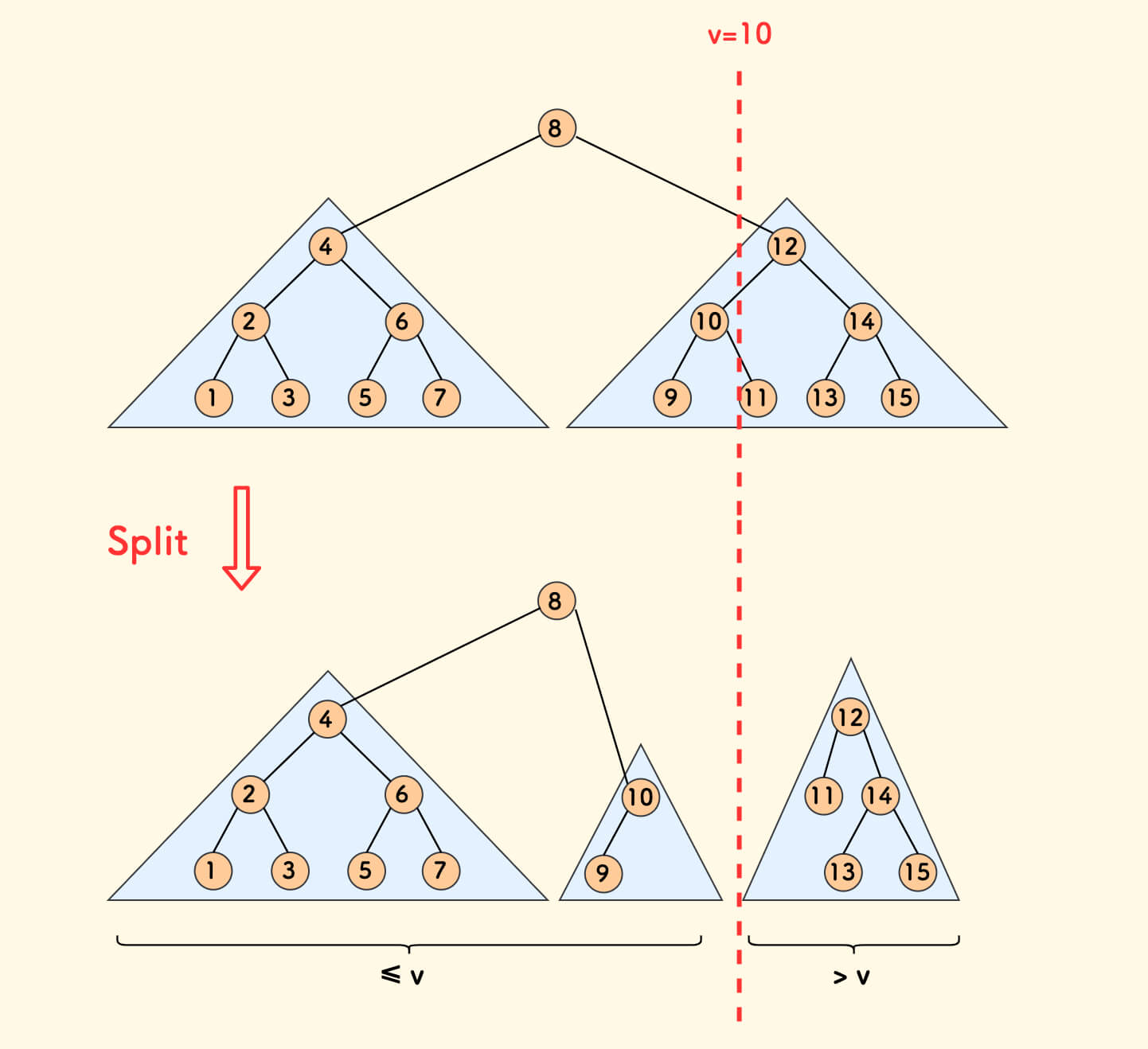
这其实就可以实现一个求右界的函数。
构造一个函数 leqthan(v):
负责统计树中权值
<= v的节点数量。
实际上,只需要按 v 进行分裂,左子树的节点数目就是此函数的答案。此外要注意分裂后把树再合并回去。
leqthan 函数的 C++ 实现
// 返回 <= v 的节点个数
int leqthan(ll v) {
int x, y;
split(root, v, x, y);
int ans = tr[x].size;
merge(x, y);
return ans;
}
要求在一个范围 [l, r] 内的节点数量的话,可以转化为:
leqthan(r) - leqthan(l-1)
接上 「初步分析」 中的思路,仍然从后向前扫描 sums 数组:
- 把当前的前缀和
x插入到 treap 中,并作为目标区间左端点。 - 考察在
[lower+x, upper+x]范围内的右端点y的个数,只需查询两次leqthan,求差。
时间复杂度是 $O(n\log{n})$。
fhq treap 解法的完整实现见 GitHub 链接: 区间和计数问题 - fhq treap - C++ 代码实现
CDQ 分治解法 ¶
首先,仍然同 「初步分析」 中一样,提前计算前缀和数组 sums。
考虑分治解法,先定义一个函数 cdq 来处理 sums 数组的一个区间上的计数,函数签名如下:
cdq 函数签名 - C++ 代码
// cdq 函数用来处理闭区间 [start, end] 上的计数,累加到 ans 上
void cdq(vector<ll>& sums, int start, int end,
int lower, int upper, int& ans) {
// TODO
}
// 分治的调用起点
int ans = 0;
cdq(sums, 0, n-1, lower, upper, ans);
把当前区间二分后,考察每个区间 [i,j],可以分为三种情况:
i和j都在左边。
i在左边、j在右边。
i和j都在右边。



那么,第 1 种情况、第 3 种情况,都可以递归解决。
第 2 种情况先留作后面考虑,现在的代码框架如下:
分治主函数 cdq 的大体框架 - C++ 代码
void cdq(vector<ll>& sums, int end,
int lower, int upper, int& ans) {
if (start >= end) return;
int mid = (start + end) >> 1;
// 第 1 种情况,都在左边
cdq(a, start, mid, lower, upper, ans);
// 第 2 种情况 TODO
// 第 3 种情况,都在右边
cdq(a, mid+1, end, lower, upper, ans);
}
这其实就是 CDQ 分治的一般性思路[2]。
重点是第 2 点,可以考虑提前对两边分别排序,将会看到这样做的好处。
不过,在处理第 3 点之前,要先恢复右半边的排序,所以考虑包装一个叫做 P 的结构体,以方便右边按下标恢复原来的秩序:
包含前缀和 和 原始下标的结构体 P 的定义 - C++ 代码
struct P {
int idx; // 下标
ll sum; // 前缀和
};
// 按前缀和排序
bool cmp_sum(const P& a, const P& b) { return a.sum < b.sum; }
// 恢复秩序时,按下标排序
bool cmp_idx(const P& a, const P& b) { return a.idx < b.idx; }
至此,cdq 函数的代码框架演变如下:
分治主函数 cdq 的代码框架 - C++
void cdq(vector<P>& a, int end,
int lower, int upper, int& ans) {
if (start >= end) return;
int mid = (start + end) >> 1;
// 两边分别排序
sort(a.begin() + start, a.begin() + mid + 1, cmp_sum);
sort(a.begin() + mid + 1, a.begin() + end + 1, cmp_sum);
// 处理左边
cdq(a, start, mid, lower, upper, ans);
// TODO: 计算左边对右边的贡献
// 恢复右边秩序,并处理右边
sort(a.begin() + mid + 1, a.begin() + end + 1, cmp_idx);
cdq(a, mid+1, end, lower, upper, ans);
}
已知:区间和可以表达为两个前缀和之差, 即可表达为 a 数组中两个元素的 sum 字段之差。
下面聚焦在第 2 点情况上,也就是:
数组
a的左右两边分别有序的情况下,从左边取一个x,右边取一个y,使得y-x的值在[lower, upper]范围内。计算这样的元素对的个数。
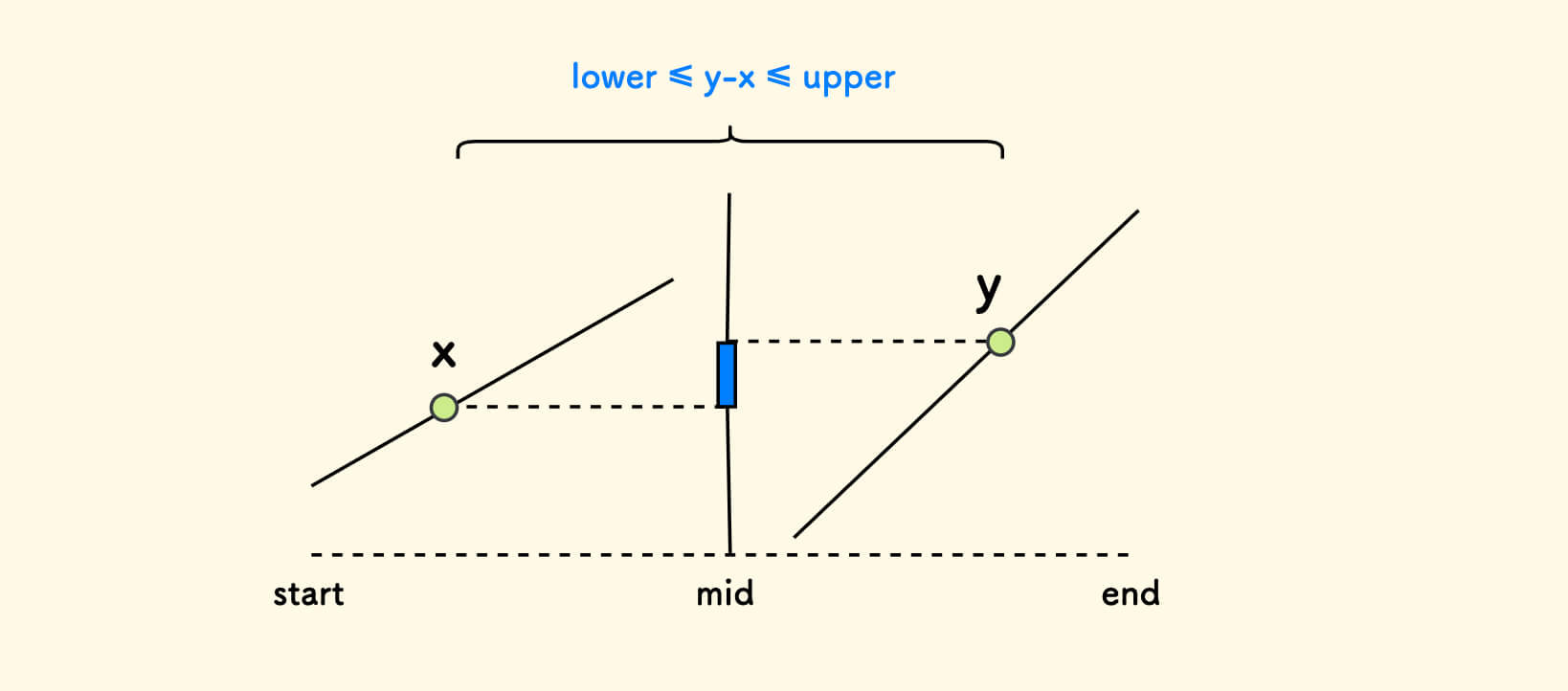
可以拆分成两个任务:
- 计算
y-x <= lower-1的数量cnt1。 - 计算
y-x <= upper的数量cnt2。
所求的就是二者之差 cnt2-cnt1。
这两个子任务都可以用 同一个子函数 来解决,构造一个函数 count(u):
对于给定的一个上界
u,计算满足y-x <= u的元素对的个数。
可以进一步转化问题:
对于每一个右边的
y,在左边找满足x >= y-u的x的个数,进行累加。
在有序的情况下,找下界的问题,可以说是「一眼二分」,线性枚举套二分的时间复杂度是 $O(n\log{n})$。
但是,存在 $O(n)$ 的方法,因为两边都是有序的。 思路是,对右边的每一个 y,枚举左边的 x,直到满足条件 x >= y-u,此时:
- 由于
x之后的所有元素都更大,肯定也满足条件,可以一并算进来,没必要继续迭代。 - 继续外层
y的迭代,会导致下界y-u变的更大,所以内层的x没必要回溯,可以继续前进。
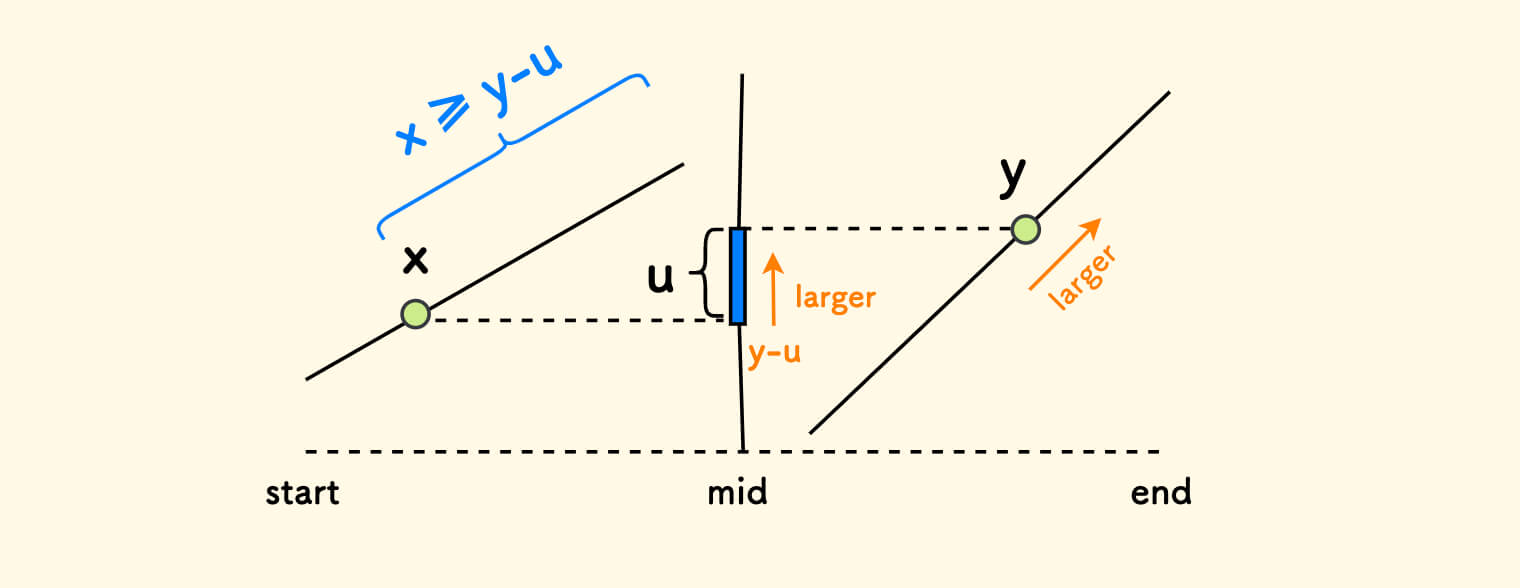
所以,虽然是两层循环,但时间复杂度却是线性的。 不妨直接看实现:
count 函数的 C++ 代码
// 计算左边的 x 和右边的 y,满足 y-x>=u 的元素对数
// 转化为:对于右边的每个 y, 找左边满足 x>=y-u 的 x 的个数
ll count(const vector<P>& a, int start, int end, int mid, ll u) {
int k = start, j = mid + 1;
ll cnt = 0;
while (j <= end) {
ll v = a[j].sum - u; // a[j].sum 是 y
while (k <= mid) {
if (a[k].sum >= v) { // a[k].sum 是 x
// [k,mid] 上的 x 都更大,所有满足
cnt += (mid - k + 1);
break;
}
k++;
}
j++;
}
return cnt;
}
目前为止,整个 cdq 函数算是构建完成了:
cdq 函数的完整实现 C++
void cdq(vector<P>& a, int start, int end,
int lower, int upper, int& ans) {
if (start >= end) return;
int mid = (start + end) >> 1;
// 先处理左边
cdq(a, start, mid, lower, upper, ans);
// 左边和右边分别排序
sort(a.begin() + start, a.begin() + mid + 1, cmp_sum);
sort(a.begin() + mid + 1, a.begin() + end + 1, cmp_sum);
// 计算左边对右边的贡献
int cnt1 = count(a, start, end, mid, lower - 1);
int cnt2 = count(a, start, end, mid, upper);
ans += cnt2 - cnt1;
// 恢复右边秩序, 处理右边
sort(a.begin() + mid + 1, a.begin() + end + 1, cmp_idx);
cdq(a, mid + 1, end, lower, upper, ans);
}
不过,cdq 函数缺失一种重要的情况,就是 区间左端点是 0 的情况。 可以直接特判:
for (ll s : sums)
if (s >= lower && s <= upper) ans++;
时间复杂度上,每一层平均来看,排序占 $O(n\log{n})$,子函数占 $O(n)$,递归深度一共 $\log{n}$ 层,所以总体时间复杂度是 $O(n\log^2{n})$。 在 leetcode 上可以压线提交通过。
CDQ 分治的解法完整代码见 GitHub 链接: 区间和计数问题 - cdq 分治 - C++ 代码实现
归并排序解法 ¶
受 CDQ 分治的启发,可以引出本题「不超纲的」归并解法。
回顾下,上面的 CDQ 中的处理顺序是:
- 两边分别排序。
- 先递归处理左边。
- 再计算左边对右边的贡献。
- 恢复右边秩序,最后递归处理右边。
在两边都有序的好处是,count 函数 可以达到 $O(n)$ 的时间复杂度。
但是,如果当前区间的左右两边已经分别有序了呢?,先排序、又恢复实在是耗费时间。
把 CDQ 分治的处理的顺序修改一下:
- 递归处理左边,并排序。
- 递归处理右边,并排序。
- 计算左边对右边的贡献(此时左右两边都有序)。
- 最后归并两边,使得整个区间有序。
第 4 点保证了子区间处理完毕后,向上递归回到母区间后、左右两边都已经是有序的。
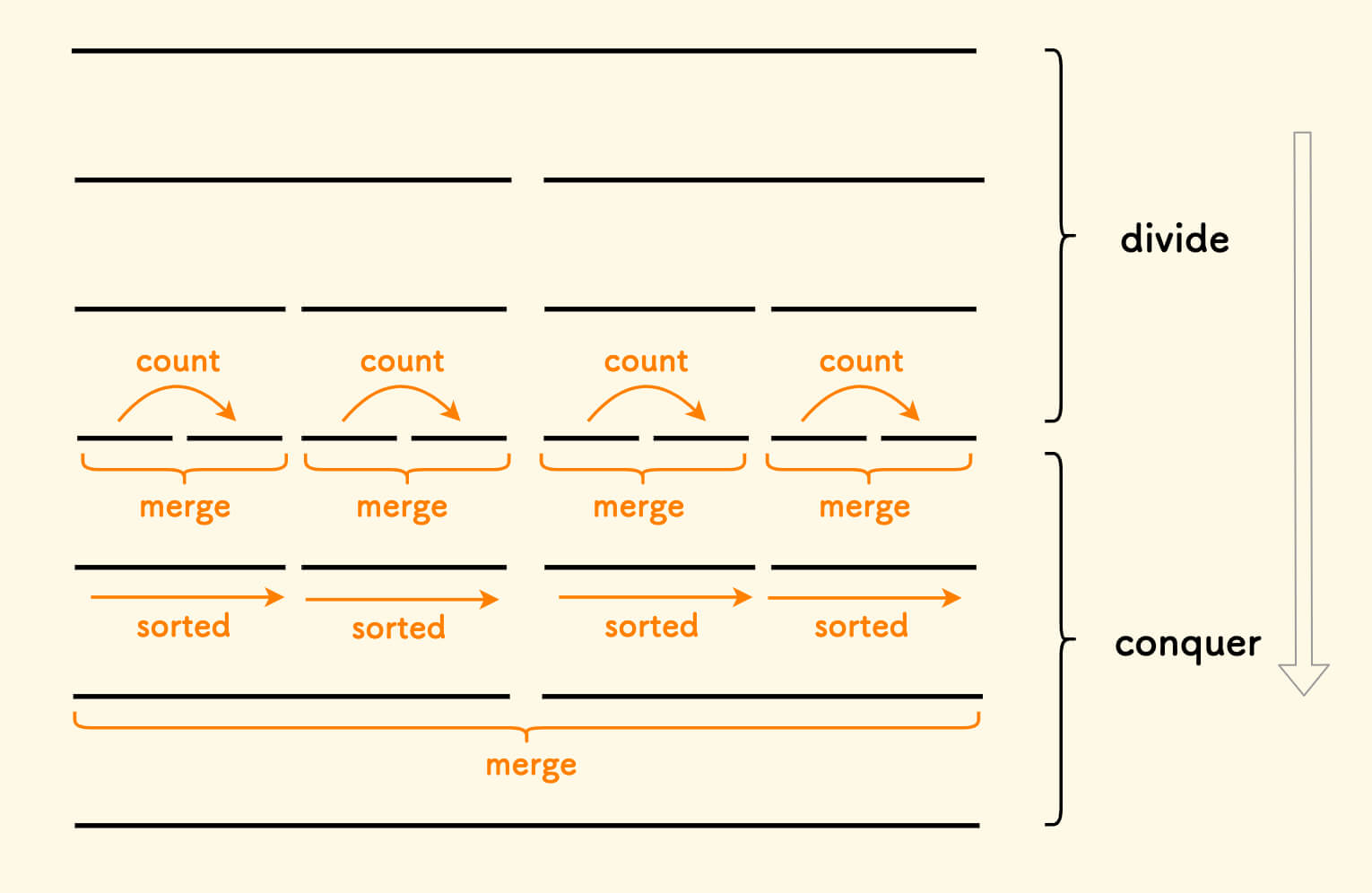
核心的「计算左边对右边的贡献」部分 和 CDQ 解法 中完全一样,只是排序的时机发生了变化。
容易看出,这其实就是一个归并排序过程,伪代码如下:
归并排序的伪代码 - C++
void dq(vector<ll>& a, int start, int end, int lower, int upper,
int& ans, vector<ll>& tmp) {
if (start >= end) return;
int mid = (start + end) >> 1;
// 先处理左边, 并排序
dq(a, start, mid, lower, upper, ans, tmp);
// 再处理右边, 并排序
dq(a, mid + 1, end, lower, upper, ans, tmp);
// 计算左边对右边的贡献, TODO: 和 CDQ 分治第 2 点的处理一样.
// 合并排序, 注意归并排序是依赖一个临时数组的
merge(a, start, mid, mid + 1, end, tmp, start);
}
其中 merge 函数和 归并排序 的合并两个有序数组完全一致。
现在也没有「恢复顺序」的必要了,所以也不必定义一个额外的结构体 P 了。
可以说,边处理,边排序。时间复杂度是 $O(n\log{n})$ 的,比 CDQ 解法 的更优,在 leetcode 上也可以超 94% C++ 提交了。
完整的代码实现在 GitHub 上: 区间和计数问题 - 归并排序 - C++ 代码实现
结尾语 ¶
这个题目还是非常有价值的,可以引出许多思路。
本文中给的四种种解法:
- 树状数组 和 平衡树 都是一种数据结构优化手段,当然用线段树也可以解决。
- CDQ 和 归并 是类似的,都是分治方法。
我认为最佳的,当属归并排序解法。
脚注 ¶
- 1. 《离散化处理》
CDQ 分治的一般性思路
- 先递归处理左边。
- 再计算左边对右边的贡献。
- 最后再递归处理右边。
(完)
更新记录:
- 2024/01/04:添加 fhq treap 解法
相关阅读:
本文原始链接地址: https://writings.sh/post/count-range-sum
