This article records the structure and principle of a concise and elegant non-rotating balanced tree: fhq treap.
Its greatest advantage is: the code is relatively short, but the function is very powerful.
Because all its capabilities are ultimately based on two basic operations: split and merge.
The article is long and contains many pictures.
Preliminary Notes ¶
First, review the properties of Binary Search Trees and Heaps, then Treap is a combination of the two.
Binary Search Tree (BST) ¶
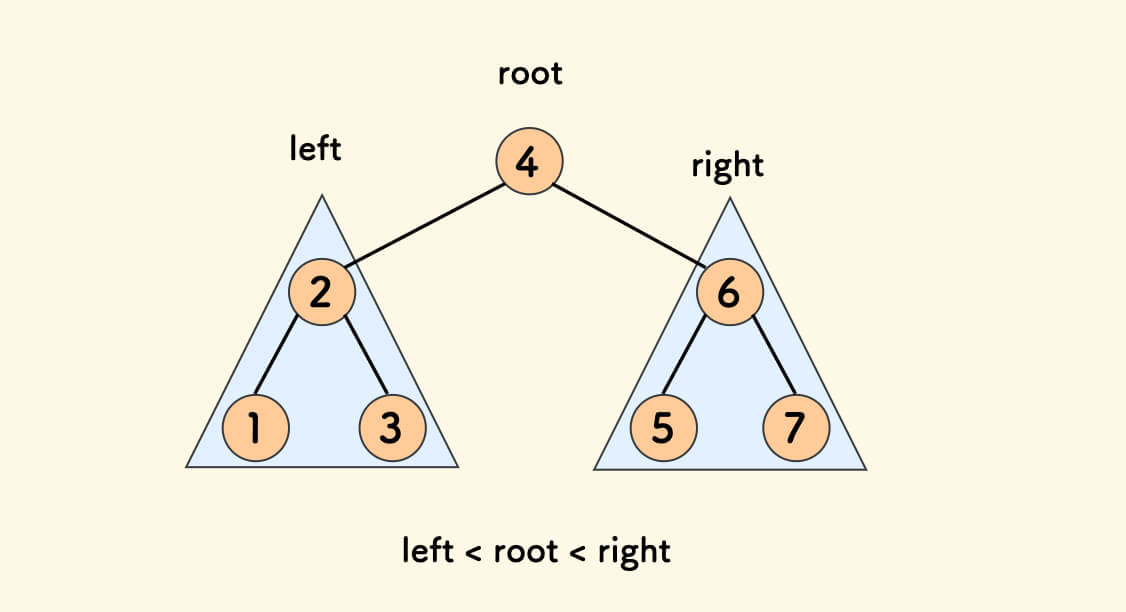
The properties of a Binary Search Tree (BST) [1]:
- The value of any node in the left subtree is less than the value of its root node.
- The value of any node in the right subtree is greater than the value of its root node.
In short: left < root < right.
Heap ¶
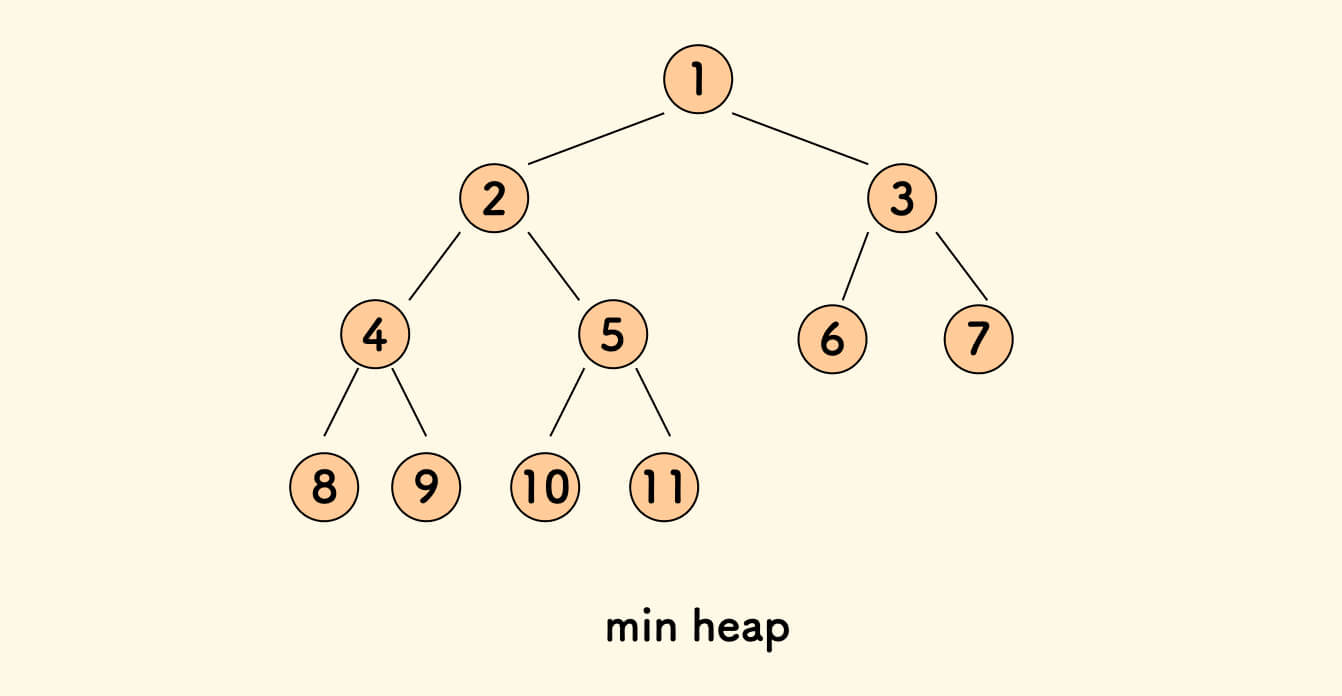
The properties of a Heap [2]: A complete binary tree in which the value of all parent nodes is not greater than the value of their child nodes.
In short: root <= left and root <= right.
Treap ¶
Treap = Binary Search Tree (BST) + Heap.
Nodes in a Treap [3] maintain two pieces of information:
val- The value used to form the BST.rnd- The random value used to form the Heap, to achieve random balancing (weak balancing).
FHQ Treap is a most commonly used non-rotating Treap. It has only two core operations:
- split: Split by value
val, recursive process. - merge: Merge by random value
rnd, recursive process.
All other functions are based on these two basic operations.
Core Operations ¶
Structure Definition ¶
Statically allocate an array to store the nodes:
const int N = 10005;
struct {
int l, r; // Indices of left and right children
int val; // BST value
int rnd; // Heap random value
int size; // Size of the tree
} tr[N];
int root = 0, n = 0; // Root node, index of the latest node
pushup Function ¶
During the recursion process, post-order integrate information from the left and right subtrees, and maintain information for the parent tree.
The pushup function that only maintains subtree size size information is as follows:
// The number of nodes in the parent tree = the number of nodes in the left subtree + the number of nodes in the right subtree + 1 (the root node itself)
void pushup(int p) {
tr[p].size = tr[tr[p].l].size + tr[tr[p].r].size + 1;
}
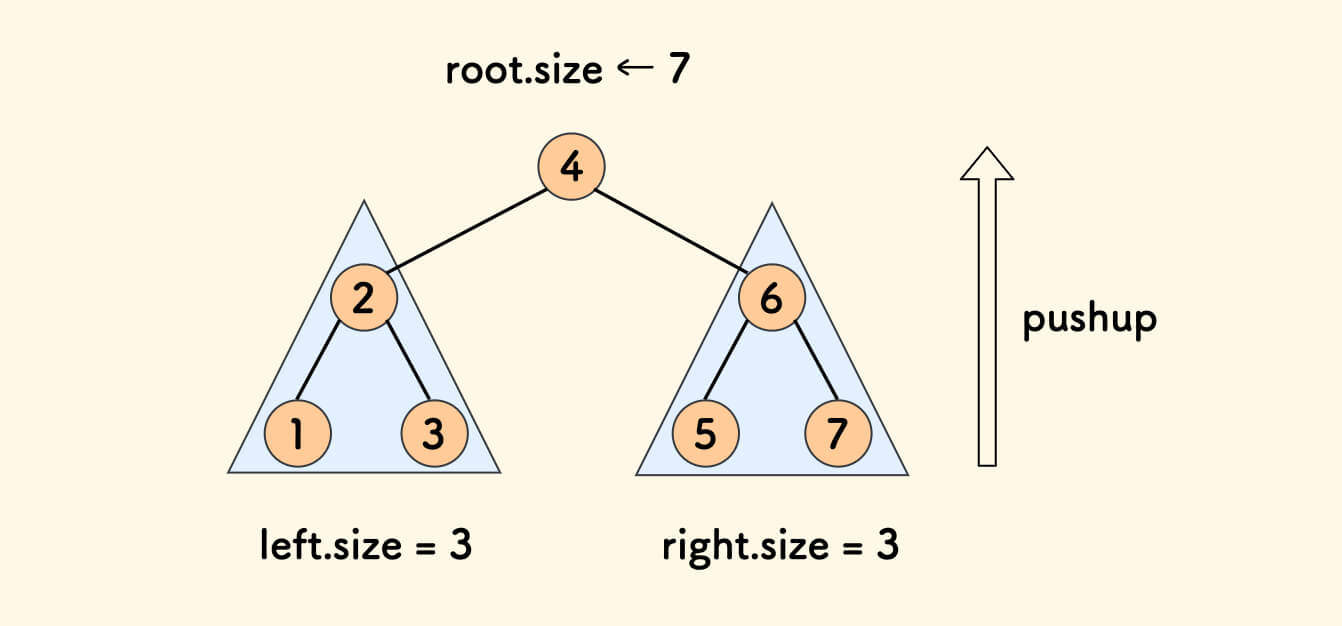
pushup follows after recursion and is performed from bottom to top. It is called during split and merge.
A pseudo-code illustration is as follows:
void dfs(...) {
dfs(...);
// Because the subtree structure may change, maintain the information of tree p after recursion.
pushup(p);
}In actual scenarios, you can also use the pushup function to maintain other information. For example, when using treap to optimize DP transitions, it often involves maintaining information such as the maximum or sum of a certain value range.
split ¶
The meaning of the split function split(p, v, &x, &y) is:
- Split tree
pinto two subtrees by valuev:xon the left andyon the right. - Make all values in subtree
xafter splitting not greater thanv, and all values in subtreeygreater thanv.
First, look at the code implementation, note that the parameters x and y are passed by reference:
C++ Implementation of the split function
void split(int p, int v, int &x, int &y) {
if (!p) { x = y = 0; return; }
if (tr[p].val <= v) {
x = p;
split(tr[p].r, v, tr[p].r, y);
} else {
y = p;
split(tr[p].l, v, x, tr[p].l);
}
pushup(p);
}
Simply analyze the first case in the code. The second case is similar and can be understood with the following diagram.
If the given value v is not less than the value of the current node p, then:
- All values in the left subtree of
pare definitely less thanv, and belong toxafter splitting. At this point,xcan be determined to bep. - You only need to continue to recursively split the right subtree of
p. However,yis not yet determined and needs to be passed down.
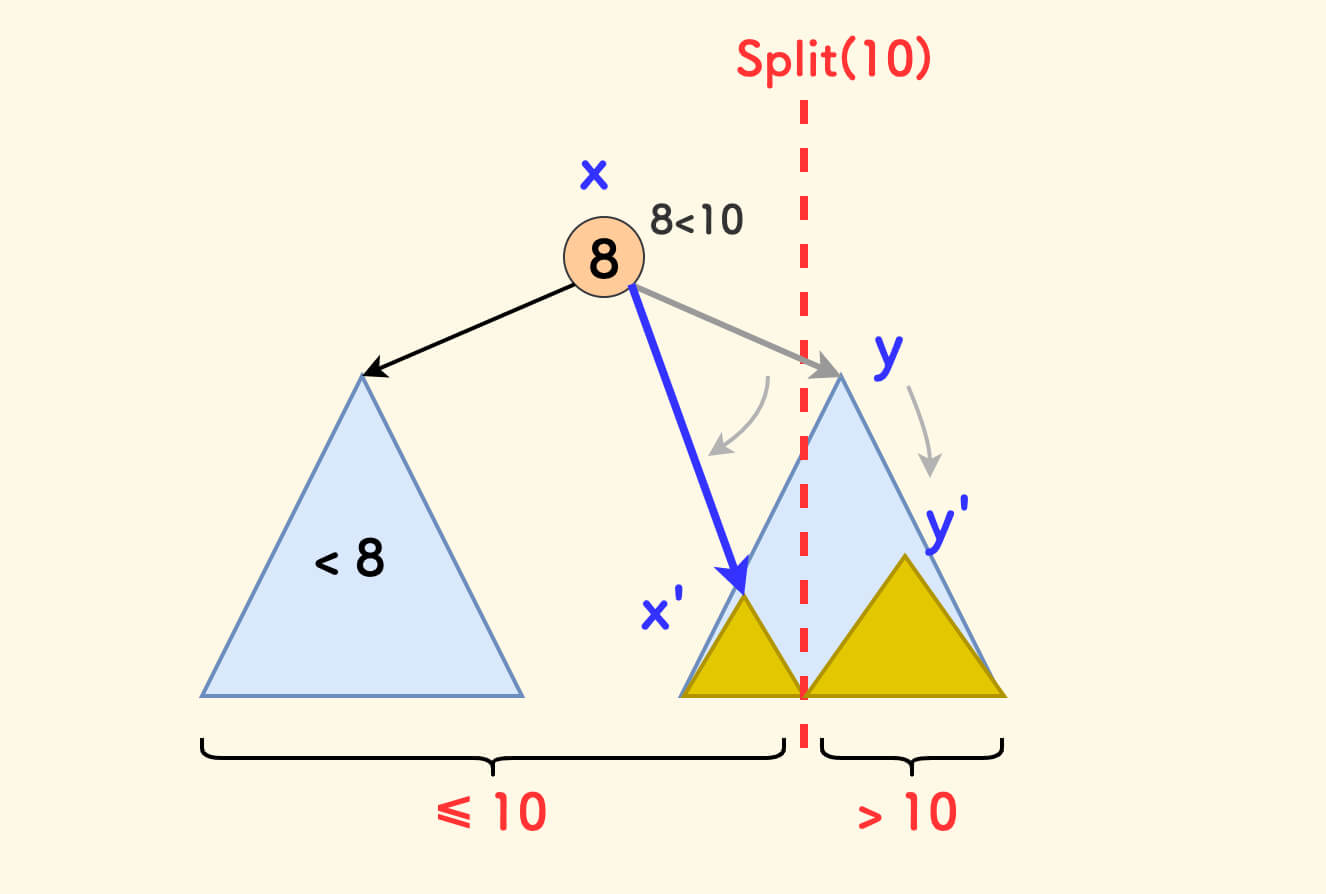
Assuming that the left and right subtrees after the next level of recursive splitting are x' and y', then:
yshould point toy'x'should be the right subtree ofxbecause they are all≤ v
In short, at this time you need to recursively split the right subtree, and the resulting left subtree becomes the right subtree of the current node.
Therefore, the recursive code in this case is as follows, note that the 3rd and 4th parameters are references:
if (tr[p].val <= v) {
// x can be determined to be p
x = p;
// Continue to recursively split the right subtree
// y needs to point to y'
// The right child of x needs to point to x'
split(tr[p].r, v, tr[p].r, y);
}
The other case is similar, and will not be repeated.
Obviously, the two subtrees after splitting are also treaps.
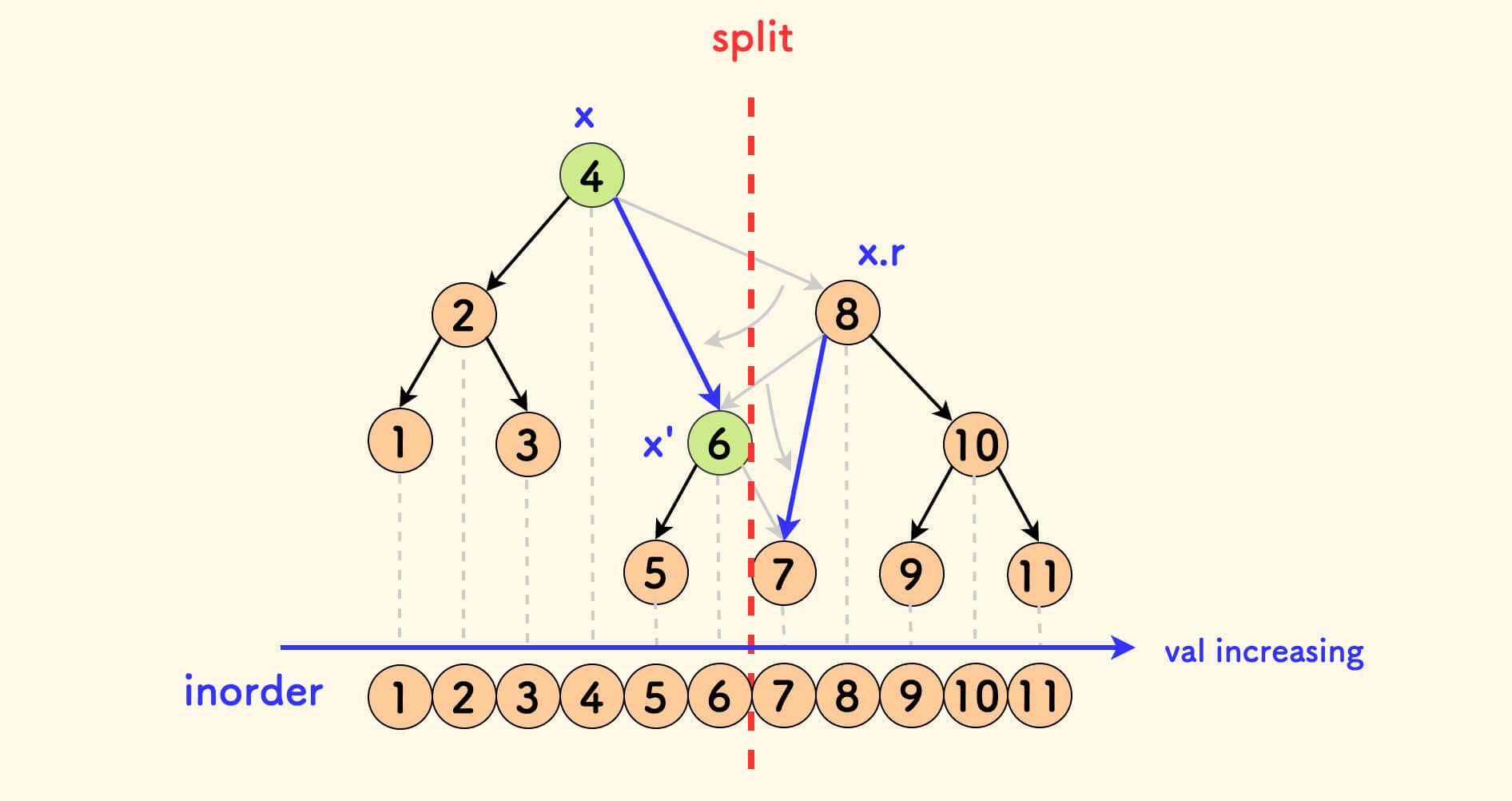
The dynamic diagram of the split operation is as follows:
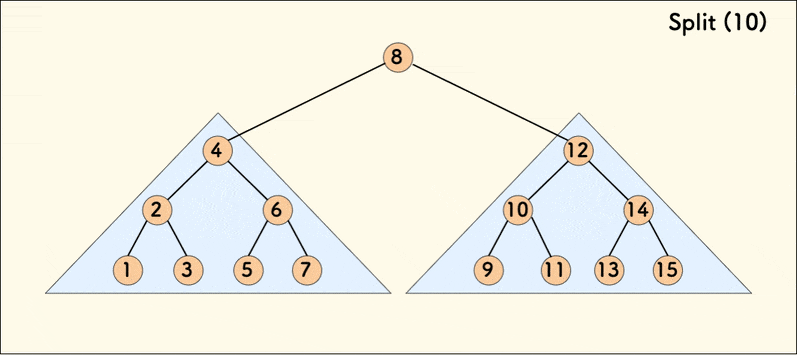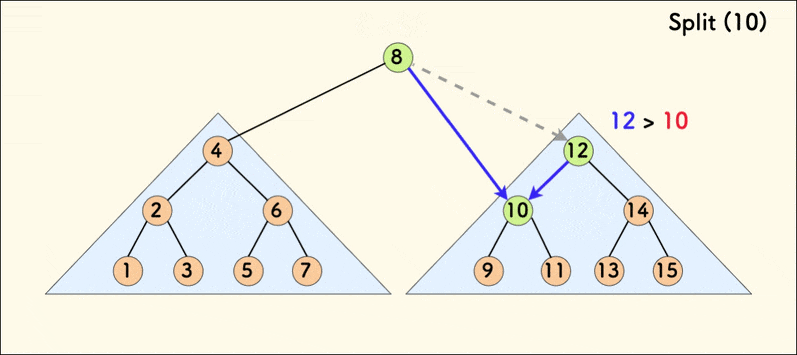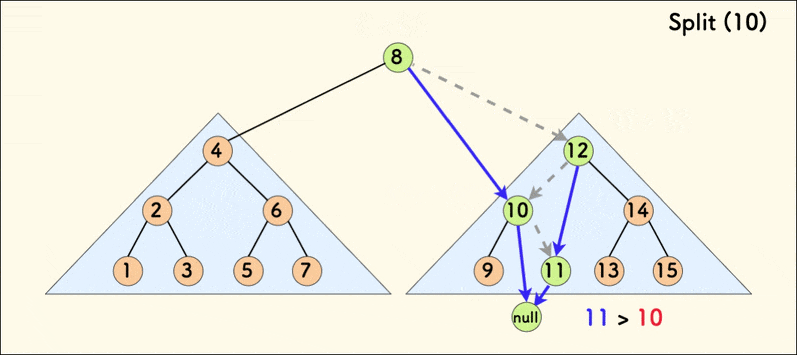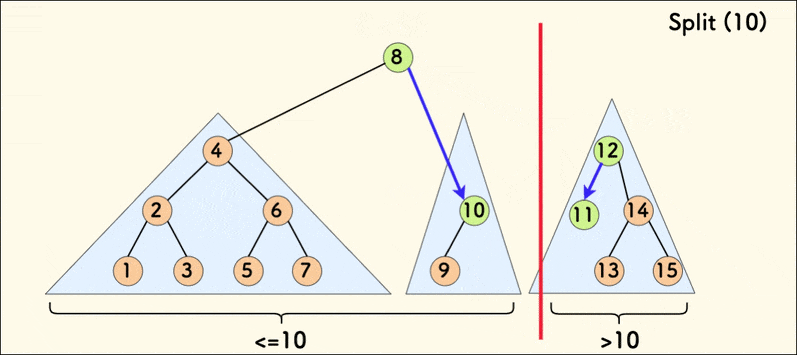
When the tree is relatively balanced, the average time complexity of splitting is $O(\log{n})$.
It can be seen that the split operation only uses the properties of the binary search tree.
An important property is that splitting does not change the inorder traversal. In more detail, splitting does not change the relative order of any two nodes in the inorder traversal.
In the figure below, the result of the inorder traversal can be mapped to a number axis. It can be seen that splitting does not affect the inorder traversal.
Detailed Explanation of How the split Operation Does Not Affect the Inorder Order
Strictly analyzing, still look at the first case, i.e., the logic branch of tr[p].val <= v.
In the figure below, after splitting, the x node points to x', but x' must come from the original right subtree of x, so x' must still be located after x in the inorder traversal.
The same analysis can be applied to the other case.
There are only these two cases on the split path, so the relative order of the nodes involved in the inorder traversal will not change.
merge ¶
The meaning of the merge function merge(x, y) is:
- Merge the two treaps
xandyaccording to the heap random valuernd, so that the merged result becomes a new treap. - Input requirements: The values of all nodes in
xmust be all not greater than the values of all nodes iny.
Obviously, the two subtrees obtained by splitting by the split function satisfy the input requirements of merge.
In fact, most of the higher-level functionalities of fhq treap follow a “split-then-merge” pattern..
The core logic of merging is to compare the sizes of the random values rnd of x and y, put the one with the smaller rnd on top.
First, look at the code implementation:
C++ Implementation of the merge Function
int merge(int x, int y) {
if (!x || !y) return x + y;
if (tr[x].rnd < tr[y].rnd) {
tr[x].r = merge(tr[x].r, y);
pushup(x);
return x;
} else {
tr[y].l = merge(x, tr[y].l);
pushup(y);
return y;
}
}
Only discuss the first case, the other case is similar.
If x.rnd is smaller, then:
- The
xnode should be placed above, that is,xshould be selected as the root of the new tree. - Because all the values in
xare less than all ofy,yshould be placed in the (new) right subtree ofx. - First merge the original right subtree
x.rofxandyto get the new treey', which becomes the new right subtree ofx.
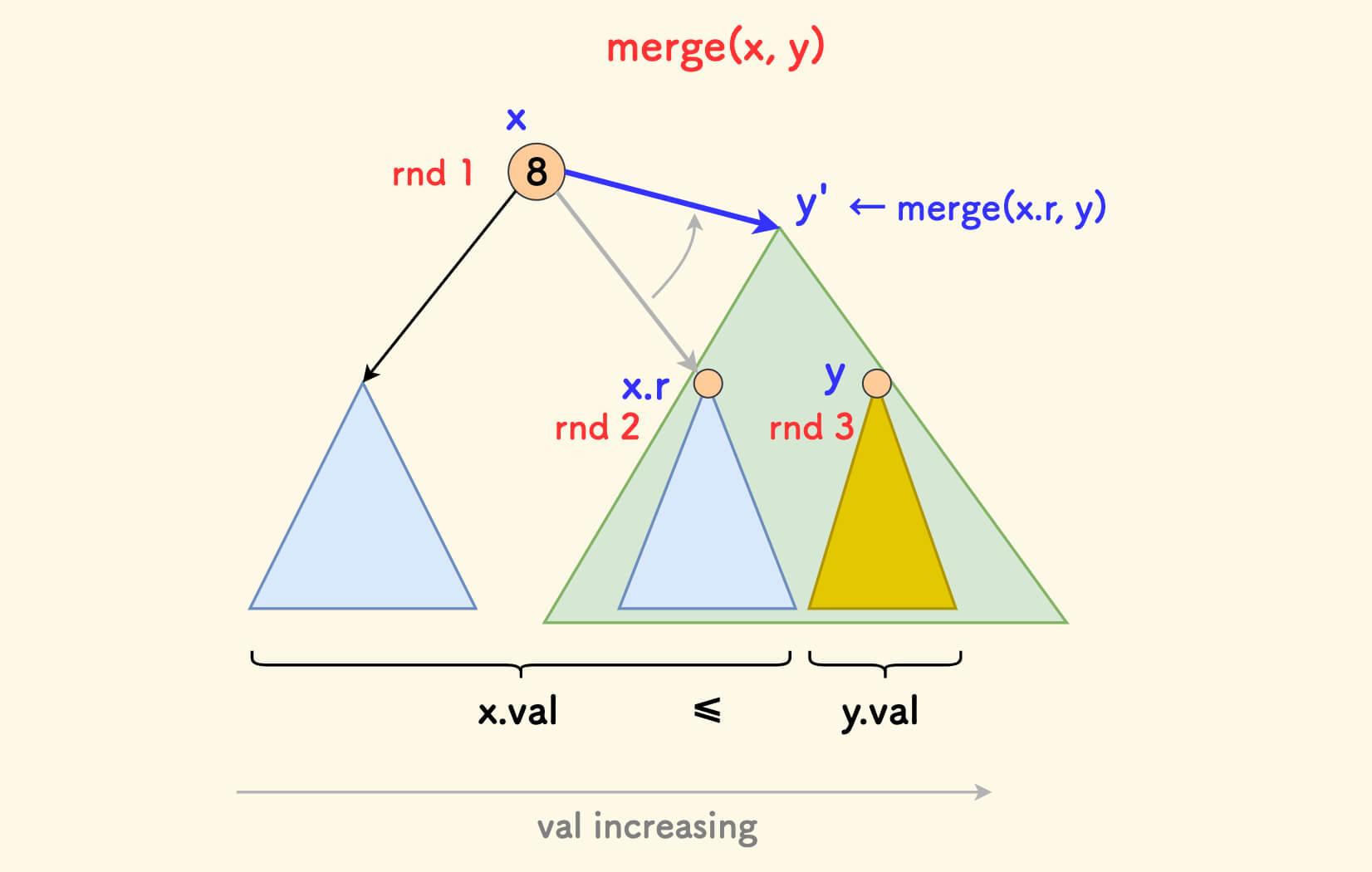
In short, at this time you need to recursively merge the right subtree of x and y, and then become the new right subtree of x.
The code annotation for this case is as follows:
if (tr[x].rnd < tr[y].rnd) {
// Recursively merge the original right subtree of x and y, denoted as y'
// y' becomes the new right subtree of x
tr[x].r = merge(tr[x].r, y);
// Because the structure within the x tree has changed, the information of x must be maintained in a post-order manner.
pushup(x);
return x;
}
A detail is that all the values of the original right subtree x.r are not greater than all the values of y, and the input requirements of merge are met during the recursive call.
The other case is similar, and will not be repeated.
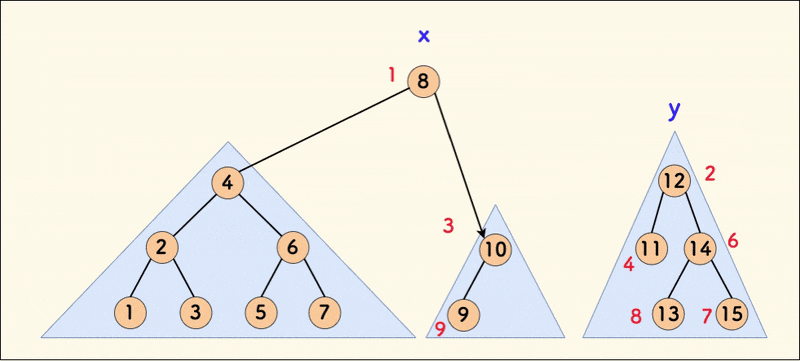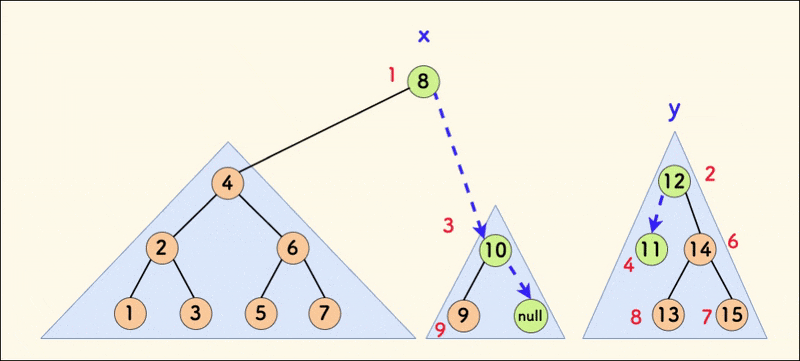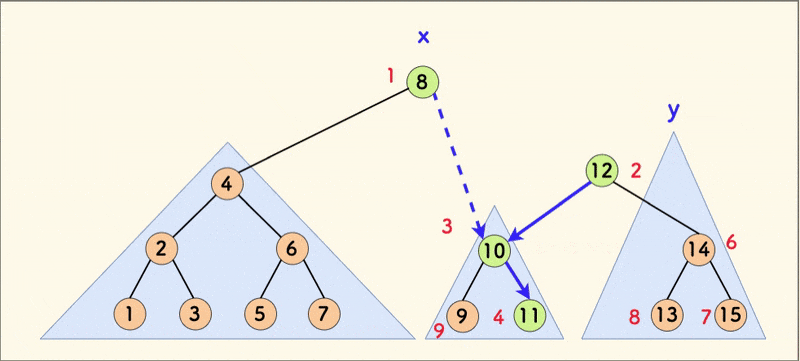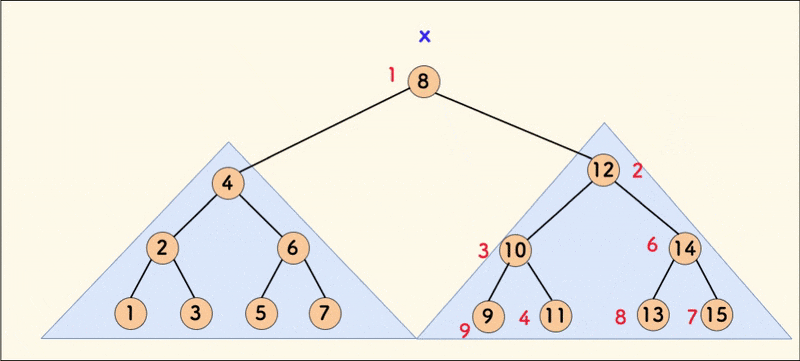
The dynamic diagram of the merge operation is as follows:
When the tree is relatively balanced, the average time complexity of merging is $O(\log{n})$.
It can be seen that the merge operation guarantees the properties of the heap, thereby balancing the treap (in most cases).
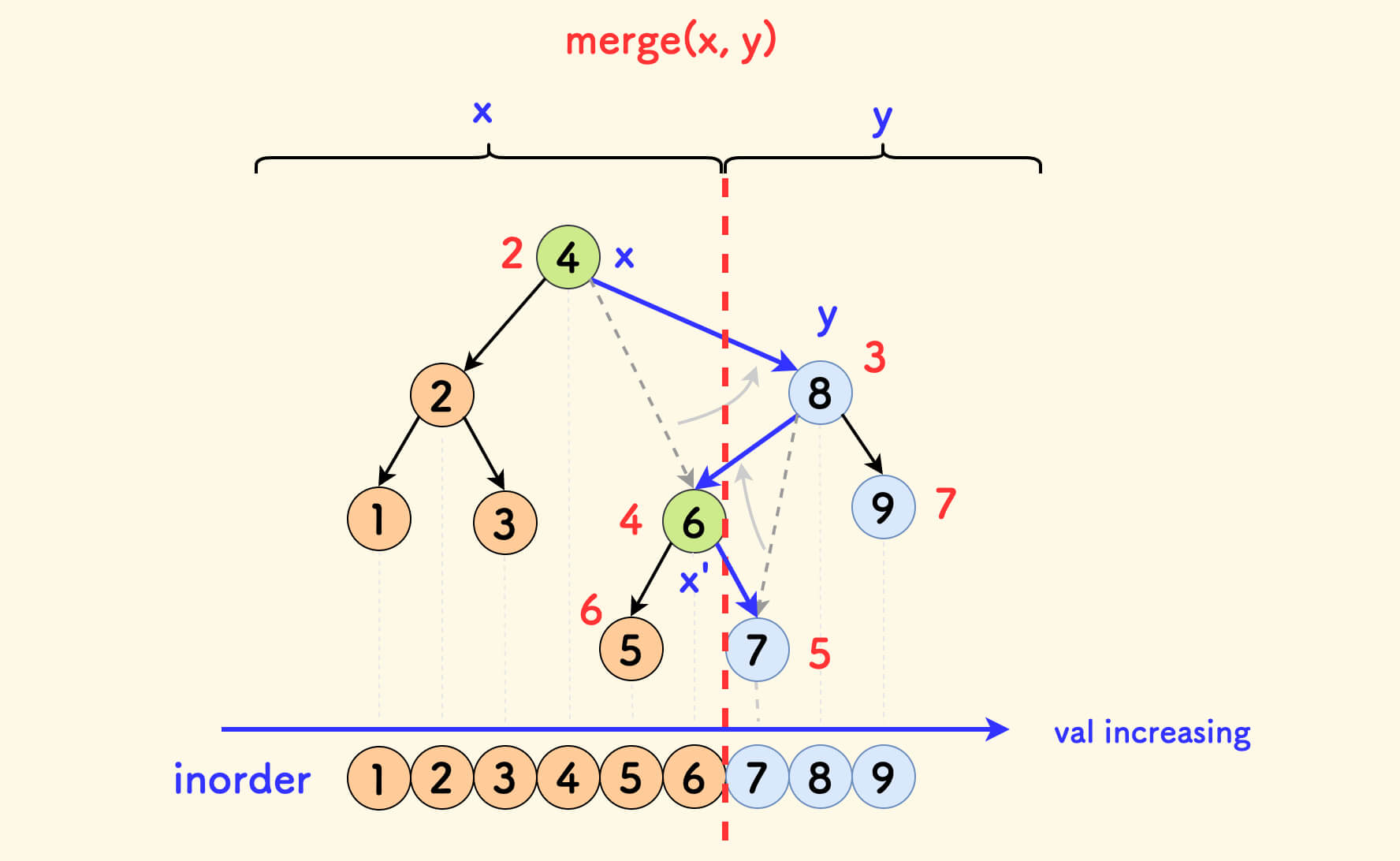
Similarly, an important property is that merging does not change the inorder traversal.
In the figure below, the result of the inorder traversal is mapped to a number axis. When the values of x are all not greater than the values of y, the merge operation does not affect the inorder traversal (where the red numbers next to the nodes are random values).
Detailed Explanation of How the merge Operation Does Not Affect the Inorder Order
Strictly analyzing, still look at the first case, that is, the logic branch where x is placed above. Then the right child of x must point to y in the end.
In the figure below, assume that the right child of x originally pointed to x' before merging. Then x' must exist in the subtree of y after merging. You can look at the code below to help understand this.
if (tr[x].rnd < tr[y].rnd) {
// x is placed above, so first recursively merge the right subtree of x and y, and then use it as the right subtree of x.
tr[x].r = merge(tr[x].r, y);
pushup(x);
return x;
}
That is to say, x' was originally the right child node of x, and after merging, it will be in the right subtree of x. Then x' is still located after x in the inorder traversal.
Therefore, for this case, the merge operation will not affect the relative order of the nodes in the inorder traversal.
The other case can be analyzed similarly.
The nodes on the merge path that may change the order are only these two cases, so the conclusion is proved.
Common Operations ¶
Most of them are “split-then-merge”. The entry point is how to carve out the target subtree.
insert ¶
To insert a new node with a value of v:
- First split into two subtrees
xandybyv. - Create a new node
zwith a value ofv. - First merge
xandz, then mergey.
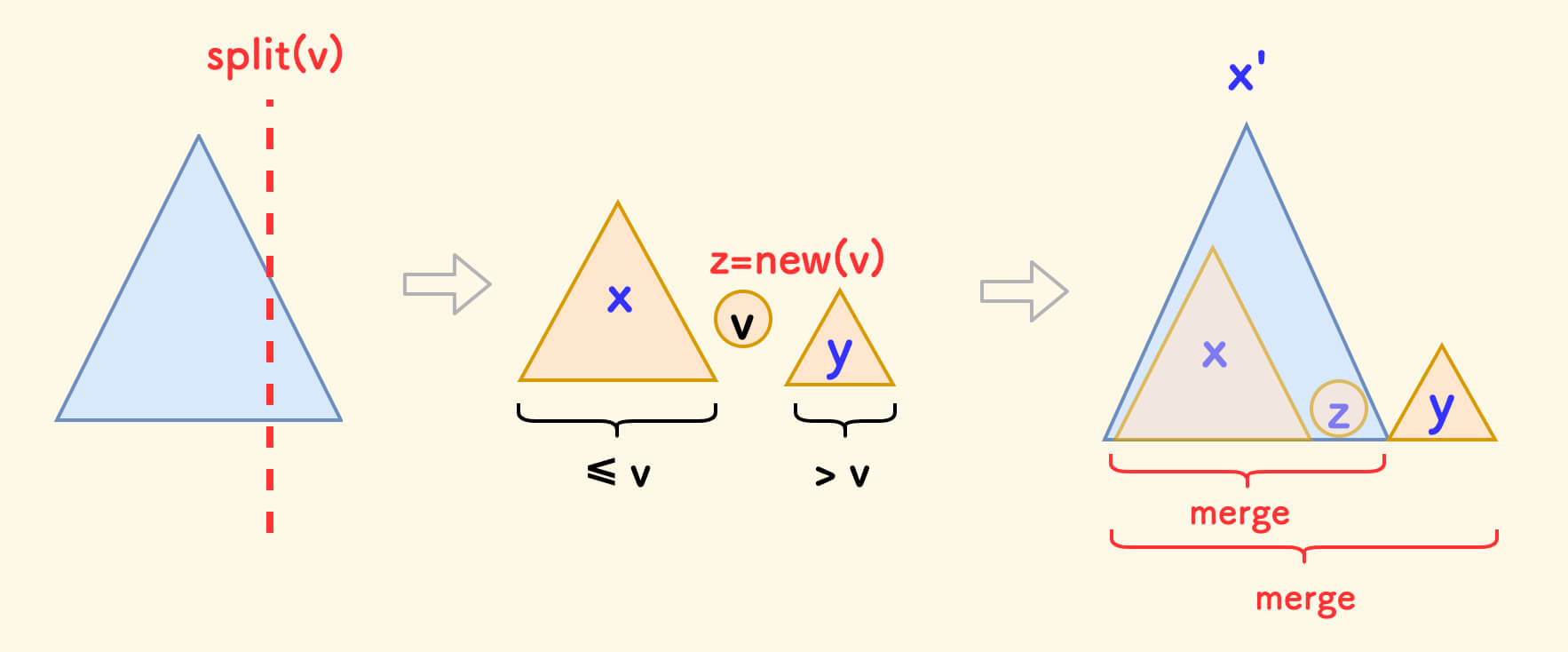
One detail is that the order of merging satisfies the input requirements of the merge function.
C++ Implementation of the insert Function
// Insert a new node with a value of v
void insert(int v) {
// Split by v, find the insertion point x <=v < y
int x, y;
split(root, v, x, y);
// Create a new node
int z = newnode(v);
// Merge x, z and y in order (the value val also satisfies this order)
root = merge(merge(x, z), y);
}
del ¶
The del(v) function is responsible for deleting a node with a value of v in the tree.
Like the insert function, the key is how to carve out the target subtree:
- First split the left and right subtrees
xandzby the valuev. - Then split the subtree
xby the valuev-1, intoxandy.
Now, all the nodes in the subtree y have a value of v.
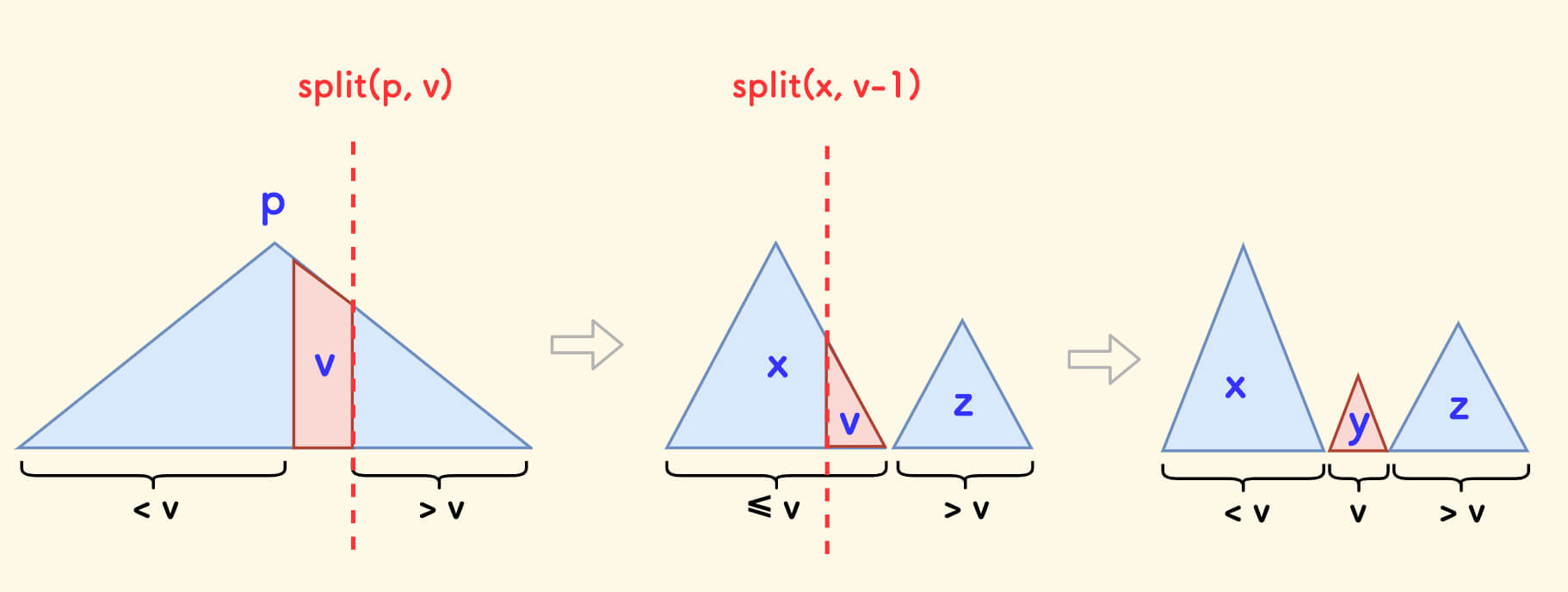
If all the nodes with a value of v are deleted, then only merge(x, z) is needed.
Now, we only delete one node with a value of v. To delete the root of y, you only need to merge its left and right subtrees:
y = merge(tr[y].l, tr[y].r);
Finally, merge x, y, z in order.
What if y is an empty tree? That is, the case where v does not exist.
In the above code implementation, merging the two subtrees of an empty tree also results in an empty tree. Therefore, if v is not found, it is equivalent to not deleting any nodes, which is in line with expectations.
C++ Implementation of the del Function
// Delete a node with a value of v
void del(int v) {
int x, y, z;
// First find the split point of v => x <= v < z
split(root, v, x, z);
// Then split the x tree by v-1 => x <= v-1 < y <= v
split(x, v - 1, x, y);
// y is the node whose value is equal to v, delete it
// If v is not found, y is an empty tree, and its left and right children are both 0, which does not affect the result.
y = merge(tr[y].l, tr[y].r);
// Then merge x, y, z
root = merge(merge(x, y), z);
}
rank ¶
The meaning of the rank function is to return the rank of the value v in the tree.
For example, if the values of the nodes in the tree are 3,5,2,1,3, then the rank of 3 is 3.
The rank is actually the number of nodes less than v plus one.
Split out the left subtree x by v-1, the answer is x.size + 1.
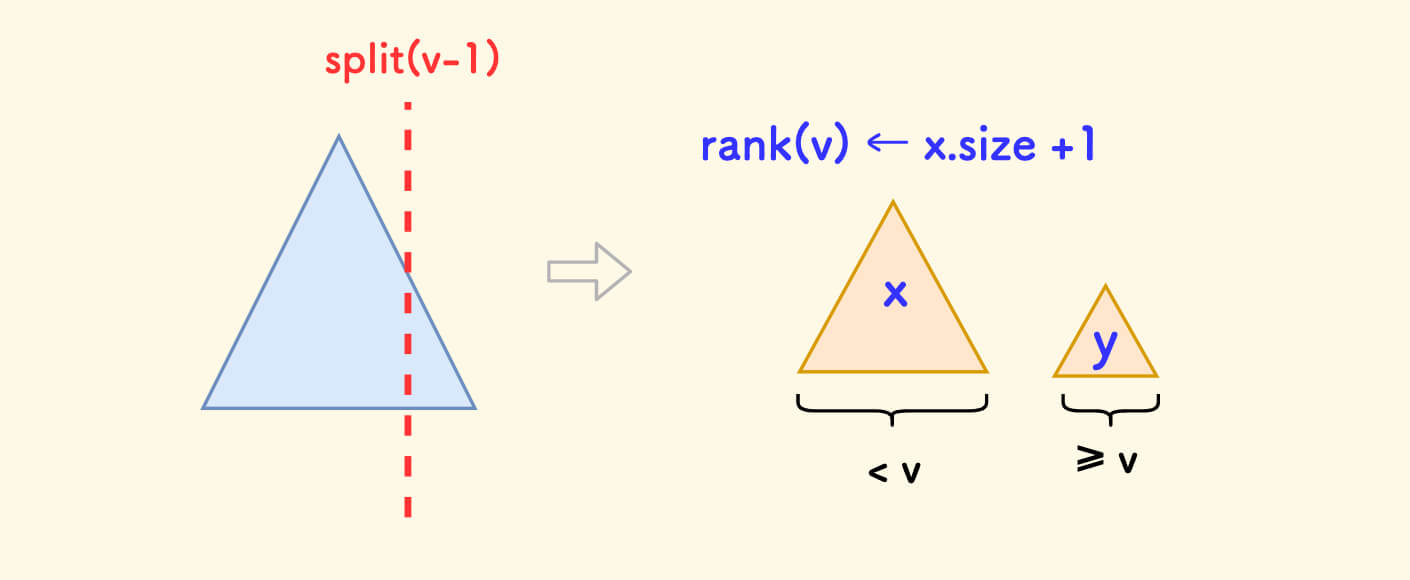
After finishing, remember to merge back.
C++ Implementation of the rank Function
// Find the rank, satisfying the number of elements < v + 1
int rank(int v) {
int x, y;
split(root, v - 1, x, y);
int ans = tr[x].size + 1;
root = merge(x, y);
return ans;
}
topk (k-th Smallest) ¶
The meaning of the topk function is: to find the k-th smallest value in the tree.
For example, if the values of the nodes in the tree are 3,5,2,1,3, then the value of topk(4) is 3.
Just use the binary search tree property of the treap.
Assume that the size of the left subtree of the current node is lsz, discuss the following cases:
- If
lsz+1happens to bek, then the value of the current node is the k-th smallest. - If
k<lsz+1, because all the values of the left subtree are less than the root node, you need to continue to recursively find the k-th smallest in the left subtree. - If
k>lsz+1, because the left subtree has already occupiedlsz, excluding the root node, you need to continue to find the (k-lsz-1)-th smallest in the right subtree.
The following figure is a schematic diagram of the 3rd case. The other two cases are also obvious.
Mapping the inorder traversal result of the binary search tree to a number axis, the conclusion will be very obvious.
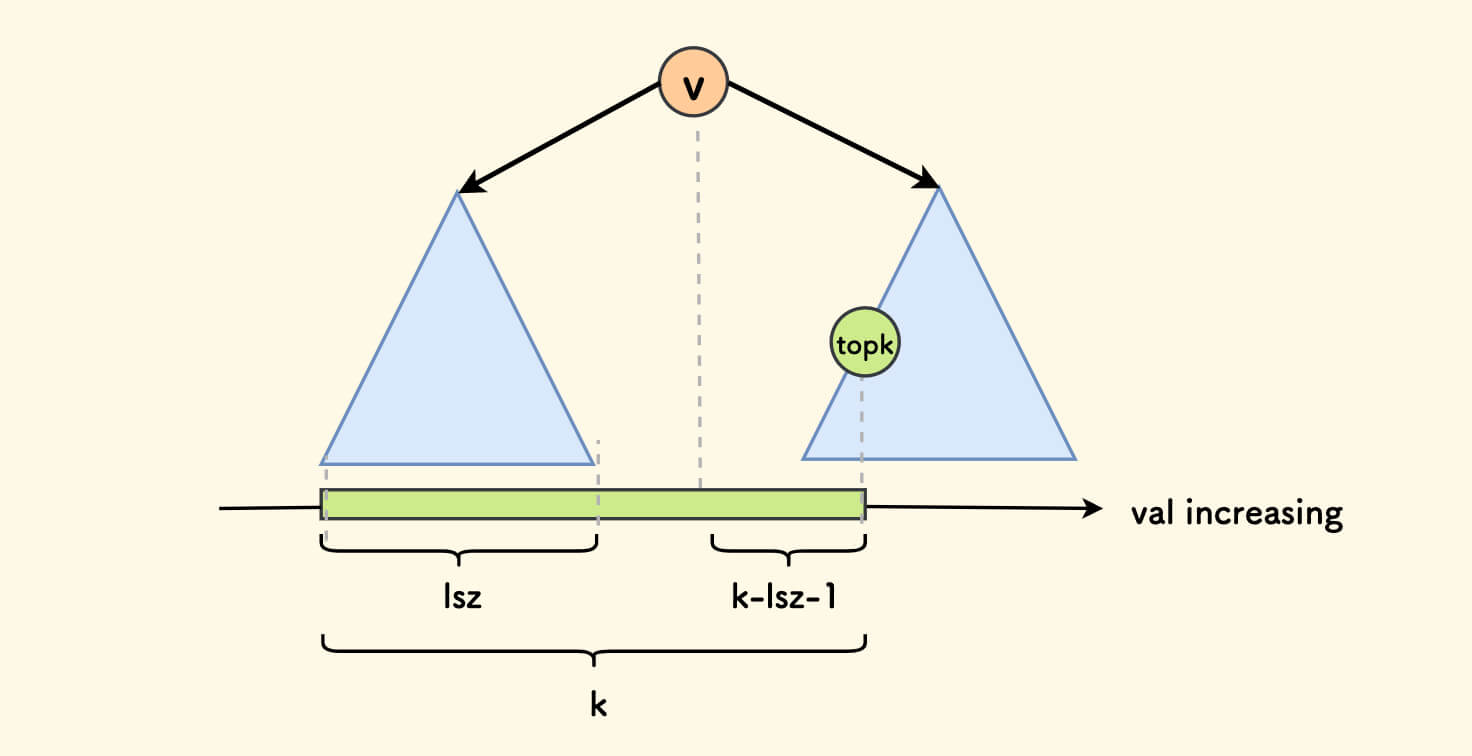
C++ Implementation of the topk Function
int topk(int p, int k) {
int lsz = tr[tr[p].l].size;
if (k == lsz + 1) return tr[p].val;
if (k <= lsz) return topk(tr[p].l, k);
return topk(tr[p].r, k - lsz - 1);
}
Predecessor and Successor ¶
The meaning of the predecessor function get_pre(v) is: to find the closest value in the tree that is strictly less than v.
The meaning of the successor function get_suc(v) is: to find the closest value in the tree that is strictly greater than v.
The ideas of the two functions are similar, only the implementation of the predecessor function is explained:
- First split by
v-1, carve out the subtreexthat is less thanv, and then return the maximum value of it. - The process of finding the maximum value of the subtree
xcan use thetopkfunction, that is,topk(x.size).
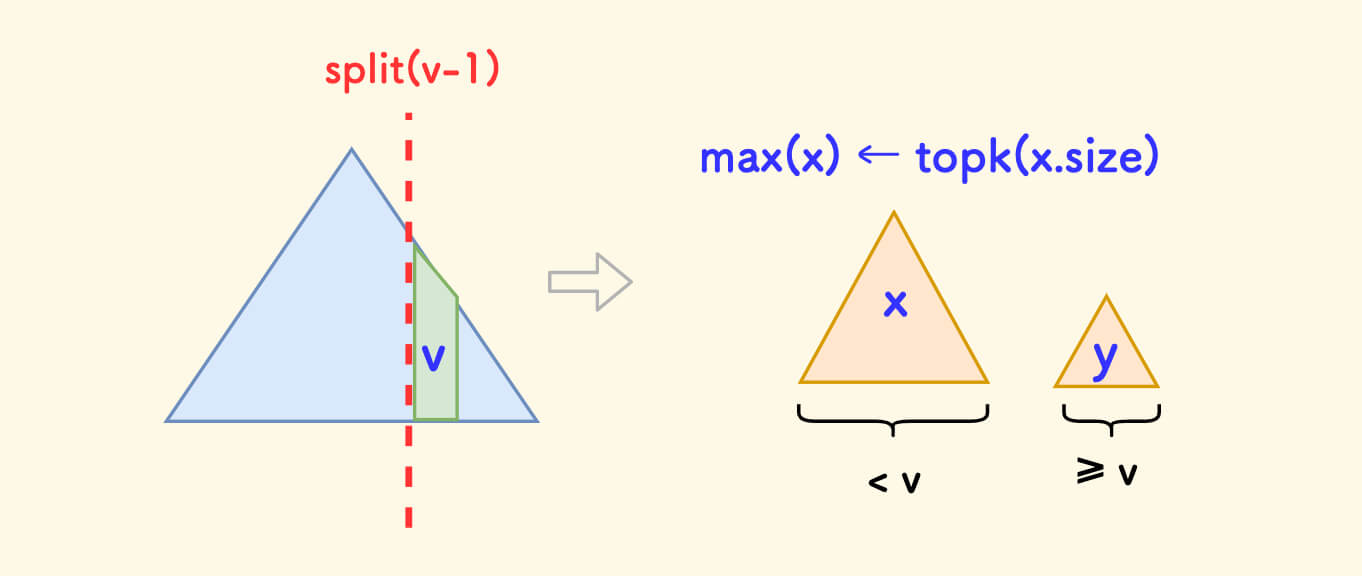
C++ Implementation of the Predecessor Function pre and Successor Function suc
// Predecessor, the value strictly < v
int get_pre(int v) {
int x, y;
split(root, v - 1, x, y);
int ans = topk(x, tr[x].size);
root = merge(x, y);
return ans;
}
// Successor, the value strictly > v
int get_suc(int v) {
int x, y;
split(root, v, x, y);
int ans = topk(y, 1);
root = merge(x, y);
return ans;
}
Template Code ¶
The above operations are generally called “Ordinary Balanced Tree”: Problem P6136, Code
Interval Operations ¶
The following part is slightly more difficult than the ordinary fhq treap.
To support interval operations on an array, there are two main points to modify:
- Originally split by value, now split by position.
- To implement “interval update”, a lazy propagation mechanism is needed for optimization.
These will be discussed separately.
Split by Position ¶
Basis for Splitting
It has been said before that the split and merge operations do not affect the inorder traversal result [4] [5].
Now, abandon the property of treap forming a binary search tree by value, and change to forming a binary search tree by index.
For example, the array [3,5,2,8,1,4,3], organize it into a tree, as shown in the figure below, where the black numbers inside the nodes represent the index, and the red numbers next to them represent the element value. Because the indices are strictly ordered, the inorder traversal of this tree by index is the increasing sequence of indices.
Splitting this tree by position k will not change the inorder order of the indices after splitting, that is, splitting will not disrupt the index order.
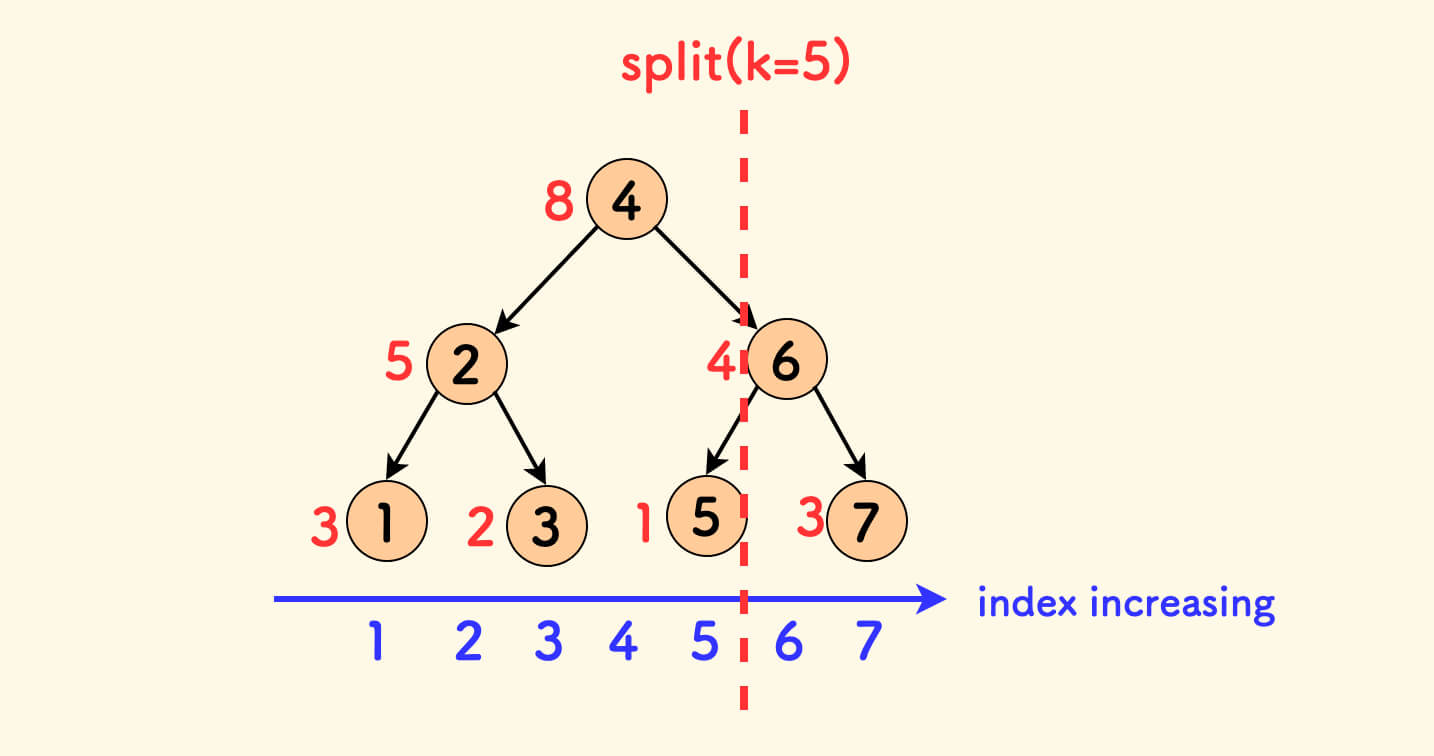
For the merge operation, because merging only uses random values and is unrelated to values, it can continue to be used and the code does not need to change. Similarly, the merge operation does not affect the inorder order of the indices.
In summary, splitting and merging by index do not change the order of the indices, which is the fundamental reason why it can maintain intervals.
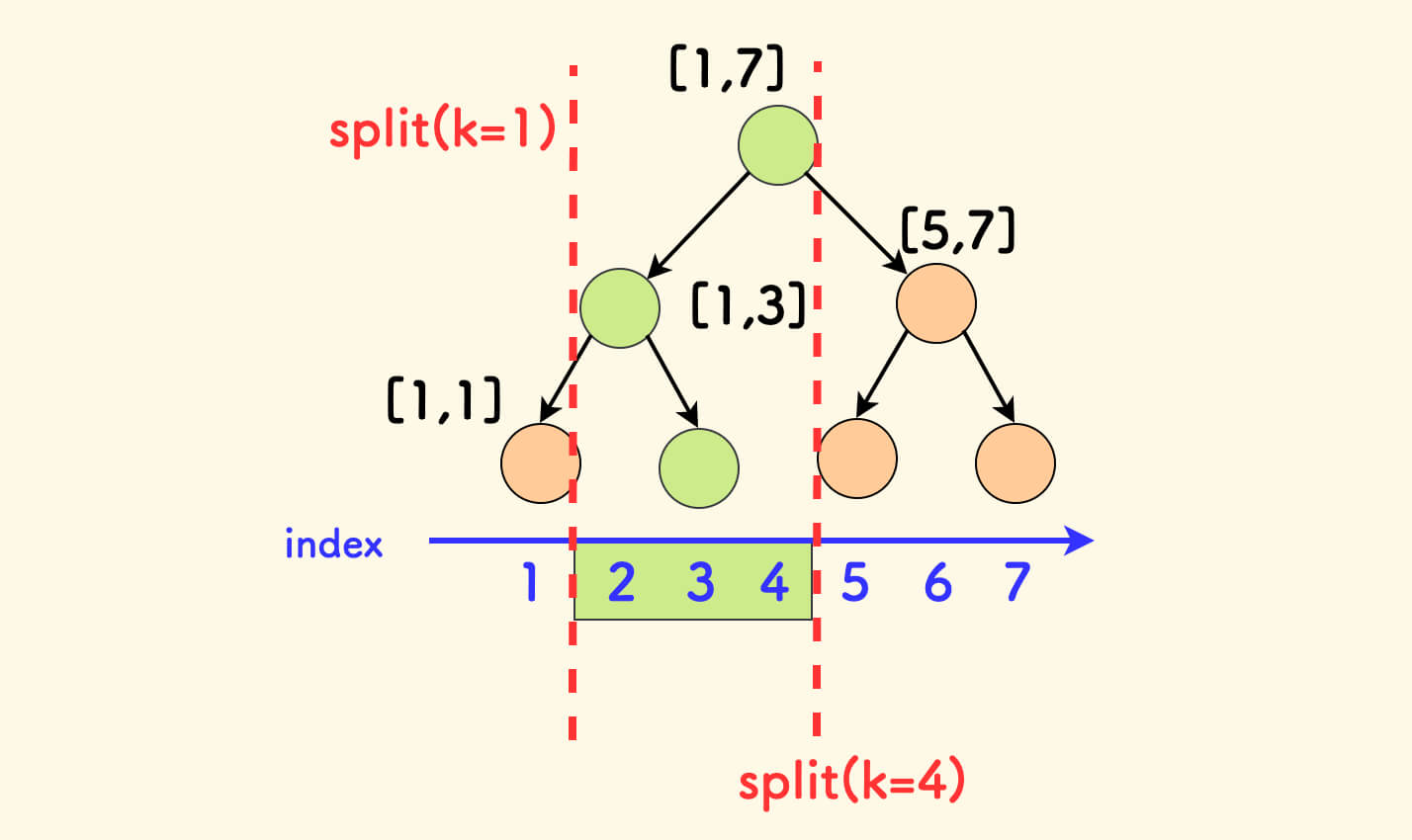
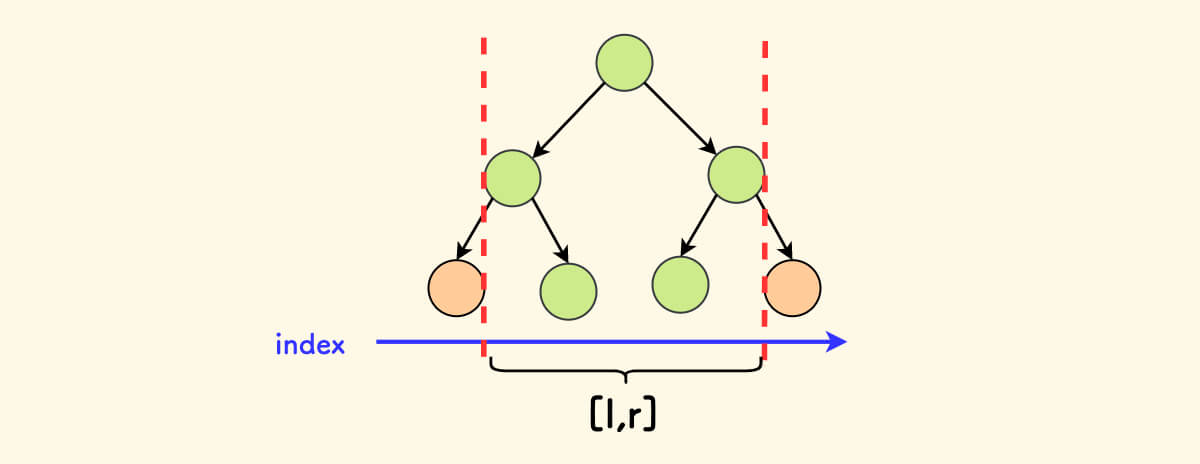
Viewing it as an “Interval Tree”
In fact, the modified treap can be regarded as an “interval tree”, which is similar to a segment tree:
- Each node represents a segment of the original array.
- The parent node’s interval = the left child’s interval + the parent node itself + the right child’s interval.
- Not every segment has a node to represent it.
- But a subtree can always be carved out to represent any segment.
For example, in the figure below, you can split twice to get the green subtree, which corresponds to the green interval [2,4]:
New Split Function
Now the meaning of the split function split(p, k, &x, &y) is:
- Split the tree
pinto two subtreesxandyat positionk. - Such that:
- The positions of the nodes in the left tree
xin the original array are all not greater thank. - The positions of the nodes in the right tree
yin the original array are all greater thank.
- The positions of the nodes in the left tree
The definition of the node structure does not require the addition of new fields. “Splitting by position” can be converted into “splitting by subtree size”.
You can directly look at the code implementation, which is only slightly different from the original split function.
split Function for Splitting by Position - C++ Code
#define ls tr[p].l
#define rs tr[p].r
void split(int p, int k, int &x, int &y) {
if (!p) { x = y = 0; return; }
pushdown(p); // pushdown function will be explained in lazy propagation
if (tr[ls].size < k) {
x = p;
k -= tr[ls].size + 1;
split(rs, k, rs, y);
} else {
y = p;
split(ls, k, x, ls);
}
pushup(p);
}
If you do not fully understand, you can click on the detailed explanation below.
Detailed Explanation of the New split Function
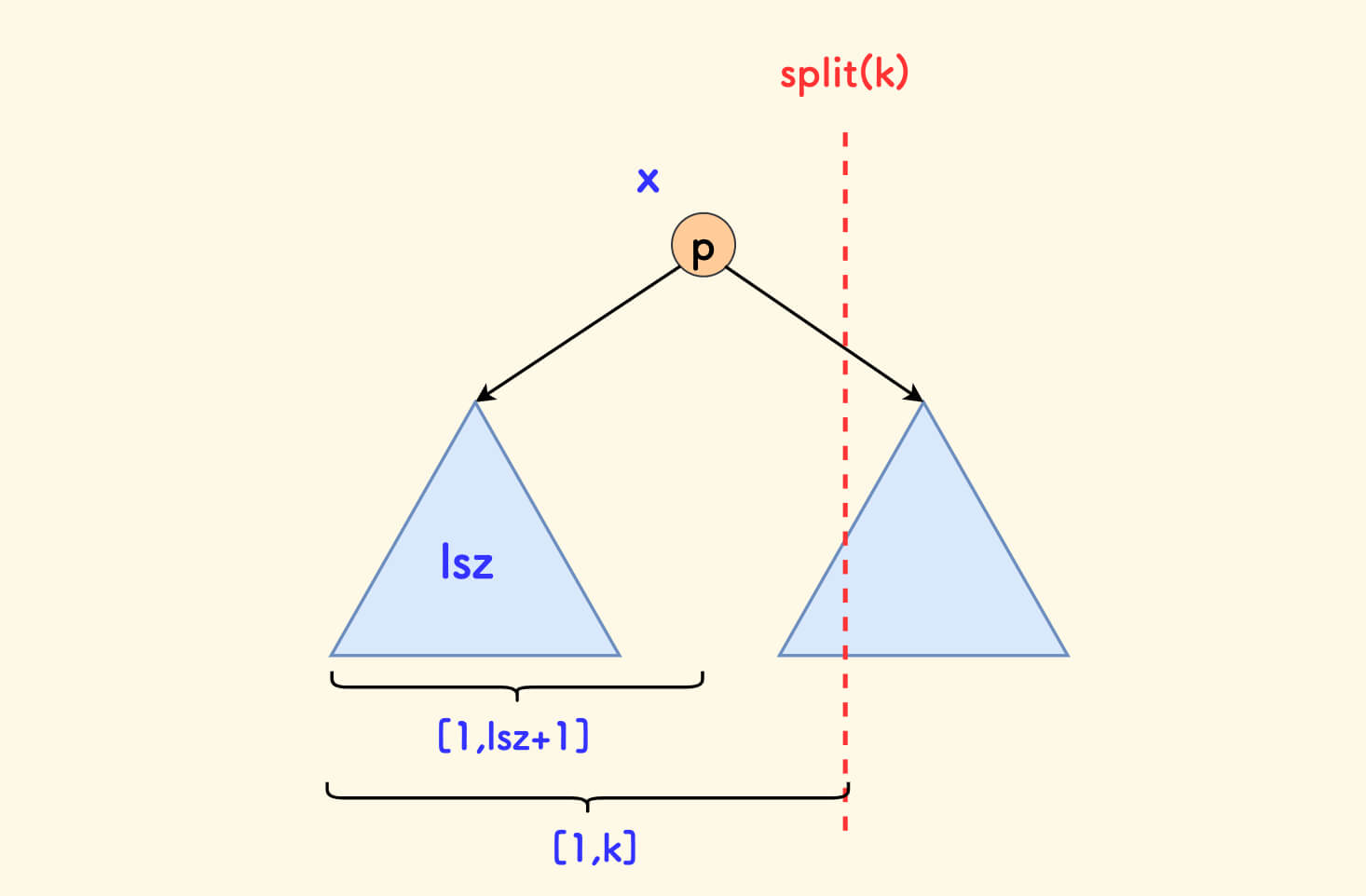
Assume that the size of the left subtree of the current node is lsz, discuss the following cases:
- If
lsz ≥ k, it means that positionkis in the left subtree, recursively split the left subtree, at this timeycan be determined to bep. - If
lsz+1 < k, it means that positionkis in the right subtree, as shown in the figure below:
However, note that the meaning of k is: the inorder position in the current tree, but it must be compared with the size of the tree, so when entering the right subtree recursively, you must exclude the left subtree and the root node, and look for position k-(lsz+1) in the right subtree.
At this time x can be determined to be p.
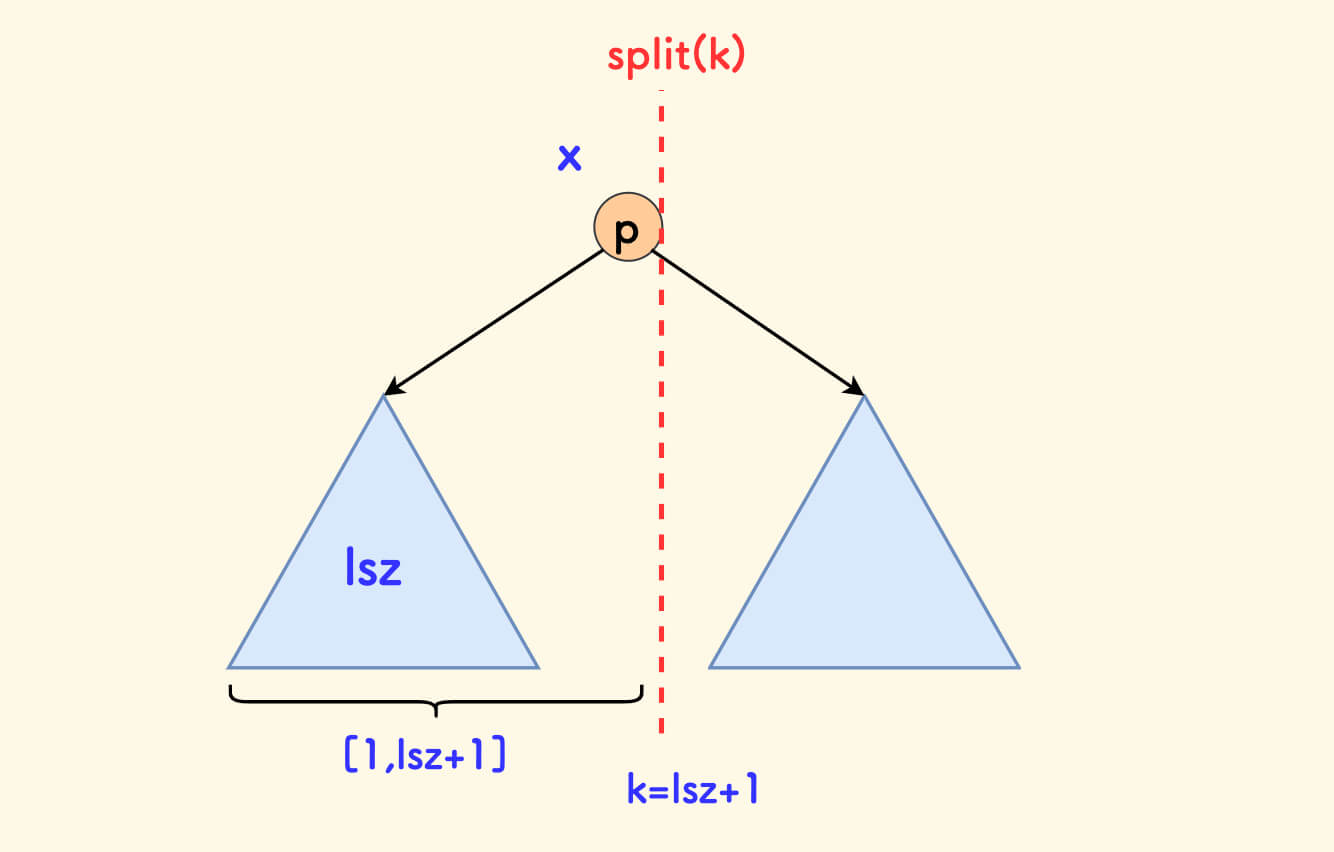
- If
lsz+1happens to be equal tok, it means that the splitting can be completed directly atp.
At this time x is determined to be p to ensure that the positions of the nodes in the x subtree in the original array do not exceed k.
That is to say, the exact splitting point is immediately to the right of the p node.
At this time, the same as the second point, recursively go to the right subtree, x can be determined to be p.
The 2nd and 3rd points can actually be unified into the case of lsz+1<=k which is lsz < k, so there are a total of two cases.
The way the split function maintains the relationship with the child nodes is completely consistent with the ordinary split function [Go to, the explanation is complete.
Decomposition of Intervals ¶
Carve out a subtree to represent a given interval
[l,r].
First carve out the interval [1,r], and then carve out [l,r] from it.
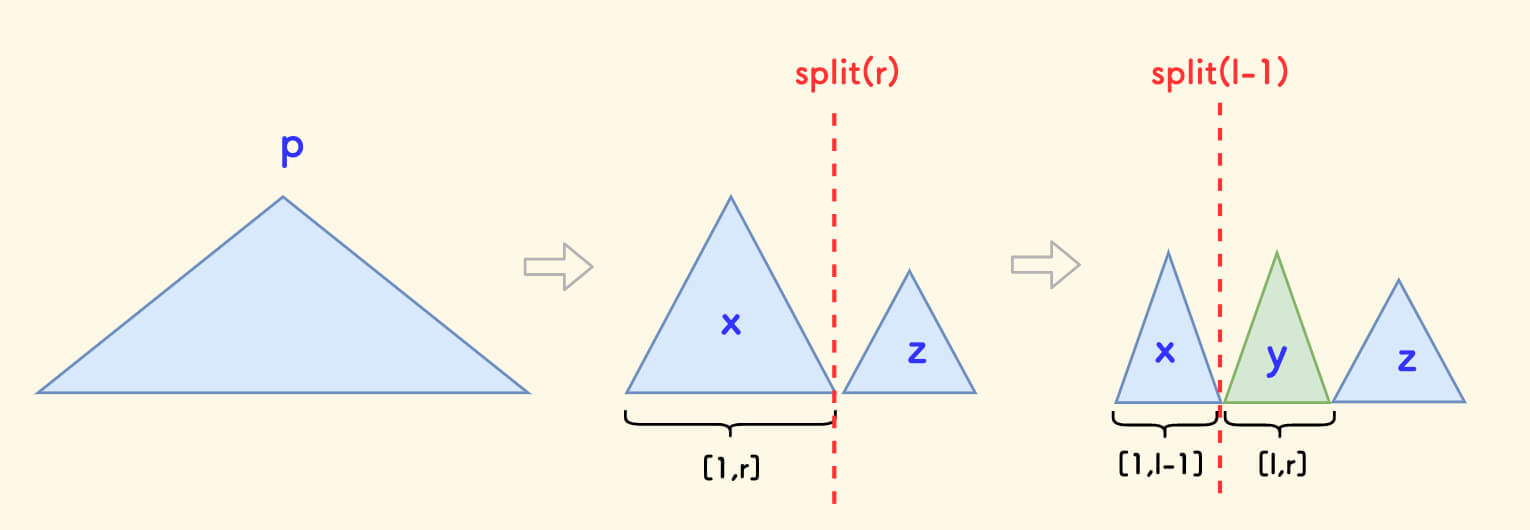
The code implementation is as follows:
int x, y, z;
split(root, r, x, z);
split(x, l - 1, x, y);
// At this time y represents the interval [l,r]
Lazy Propagation ¶
Some people also call this mechanism “lazy tags”, which is also used in segment trees.
The main optimization scenario is interval updates.
The “interval update” mentioned here is different from “single-point update”. For example, interval reversal and interval assignment are considered interval updates, emphasizing the write operation on the entire target interval.
Taking interval assignment as an example:
Change all element values in the interval
[l,r]toc.
The naive approach is to first carve out the subtree of the target interval, and then update the value of each node to c in turn.
As shown in the figure below, all green nodes need to be operated on, and the time complexity is at worst $O(n\log{n})$:
The idea of lazy propagation is:
- Don’t update first, but put a tag first.
- Update when you visit it next time, and pass the tag down to the next level of children.
The so-called “lazy update” is that no matter whether the next operation is “read” or “write”, the update is only executed and the tag is passed down when the node with the tag is visited next time.
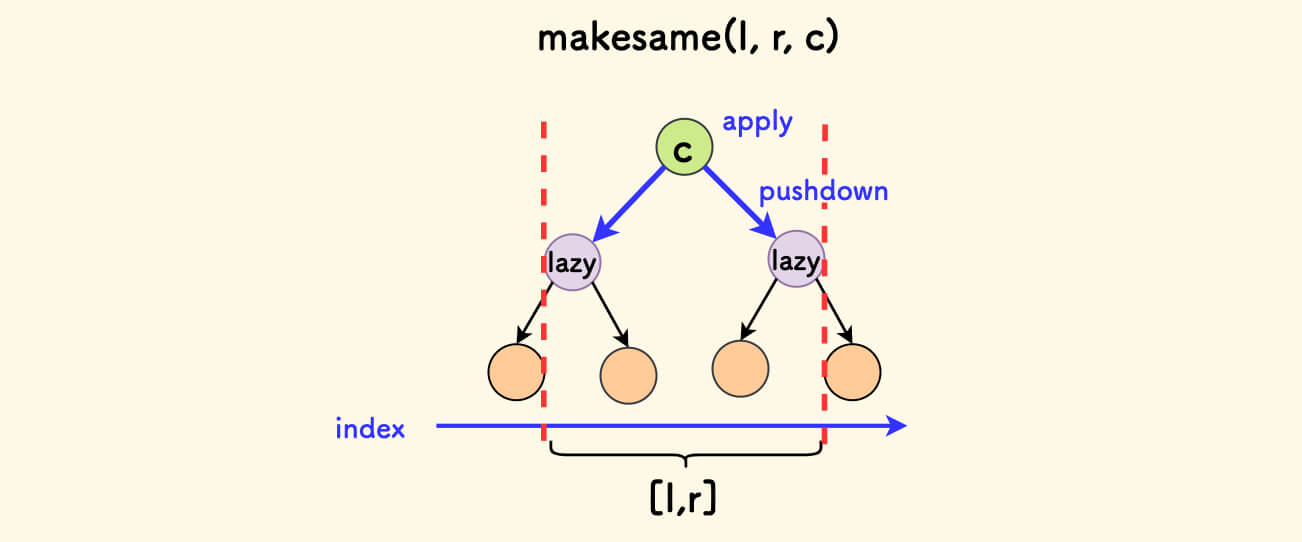
The core operations of fhq treap are only two: split and merge. Then you only need to bury the lazy update logic in it, which is the pushdown function.
First, still taking “interval assignment” as an example, two new fields must be added to the structure definition of the node:
Two New Fields Added to the Node - C++ Code
struct {
int l, r; // Left and right children
int val; // Node value
int rnd; // Random value
int size; // Subtree size
int cov_tag; // Cover lazy tag
int cov_val; // Value of the cover update
} tr[N];Then, make a pushdown function, if there is a tag, execute the update, and then pass down the tag:
pushdown Function - C++ Code
void do_cover(int p) {
if (!tr[p].cov_tag) return;
// Modify the value of the current node
int c = tr[p].val = tr[p].cov_val;
// Pass the tag down to the child nodes
tr[ls].cov_tag = 1, tr[ls].cov_val = c;
tr[rs].cov_tag = 1, tr[rs].cov_val = c;
// Clear the tag of the current node
tr[p].cov_tag = 0;
tr[p].cov_val = 0;
}
void pushdown(int p) {
if (!p) return;
do_cover(p);
}
Finally, add pushdown to the recursive descent process of split and merge:
split and merge Functions Add pushdown Function - C++ Code
void split(int p, int k, int &x, int &y) {
if (!p) { x = y = 0; return; }
pushdown(p);
if (tr[ls].size < k) {
x = p;
k -= tr[ls].size + 1;
split(rs, k, rs, y);
} else {
y = p;
split(ls, k, x, ls);
}
pushup(p);
}
int merge(int x, int y) {
if (!x || !y) return x + y;
if (tr[x].rnd < tr[y].rnd) {
pushdown(x);
tr[x].r = merge(tr[x].r, y);
pushup(x);
return x;
} else {
pushdown(y);
tr[y].l = merge(x, tr[y].l);
pushup(y);
return y;
}
}Essentially, the lazy propagation mechanism is to update layer by layer on demand in a delayed manner.
The lazy propagation part is explained.
Problem: Maintaining a Sequence ¶
All the following operations revolve around the problem Luogu P2042 - Maintaining a Sequence:
Maintain a sequence, supporting the following 6 operations:
- INSERT: Insert
totnumbers after thek-th number in the sequence.tot=0means inserting at the beginning of the sequence.- DELETE: Delete
totconsecutive numbers starting from thek-th number in the sequence.- MAKE-SAME: Change all
totconsecutive numbers starting from thek-th number in the sequence toc.- REVERSE: Reverse the
totconsecutive numbers starting from thek-th number in the sequence.- GET-SUM: Calculate the sum of
totconsecutive numbers starting from thek-th number in the sequence.- MAX-SUM: Find the sum of the sub-sequence with the largest sum in the current sequence.
This problem has many pitfalls.
First, the definition of the node will be enriched as follows. The specific meaning of the new fields will be introduced later in turn:
Definition of the Node - Added New Fields - C++ Code
struct {
int l, r; // Left and right children
int val; // Node value
int rnd; // Random value
int size; // Subtree size
int rev_tag; // Reverse lazy tag
int cov_tag; // Cover lazy tag
int cov_val; // Value of the cover update
int sum; // Sum of the interval represented by the subtree
int mpre; // Maximum prefix sum of the interval
int msuf; // Maximum suffix sum of the interval
int msum; // Maximum subsegment sum within the subtree
} tr[N];
In addition, the most common description in the problem is “from the k-th starting tot numbers”, so first encapsulate an auxiliary function help_split to do the interval splitting:
Auxiliary Function help_split - C++ Code
// Carve out subtrees x, y, z
// y is the interval of tot numbers starting from the k-th
void help_split(int &x, int &y, int &z, int k, int tot) {
int l = k, r = k + tot - 1;
split(root, r, x, z);
split(x, l - 1, x, y);
}
Batch Insertion ¶
Insert
totnumbers after thek-th number in the sequence.tot=0means inserting at the beginning of the sequence.
The naive approach is to first carve out the subtree [1,k], and then merge each new node in turn.
Naive Approach to Batch Insertion - C++ Code
void insert(int k, int tot) {
int x, y;
split(root, k, x, y);
for (int i = 1; i <= tot; i++)
x = merge(x, newnode(to_inserts[i]));
root = merge(x, y);
}
Doing this takes $O(m\log({n+m}))$ time, where m represents the number of elements to insert tot.
A better approach is to first divide and conquer to build the tree for tot numbers, and then merge it in.
Specifically, keep dividing the array to_inserts to be inserted into two, and then merge them in pairs.
The process is the same as merge sort:
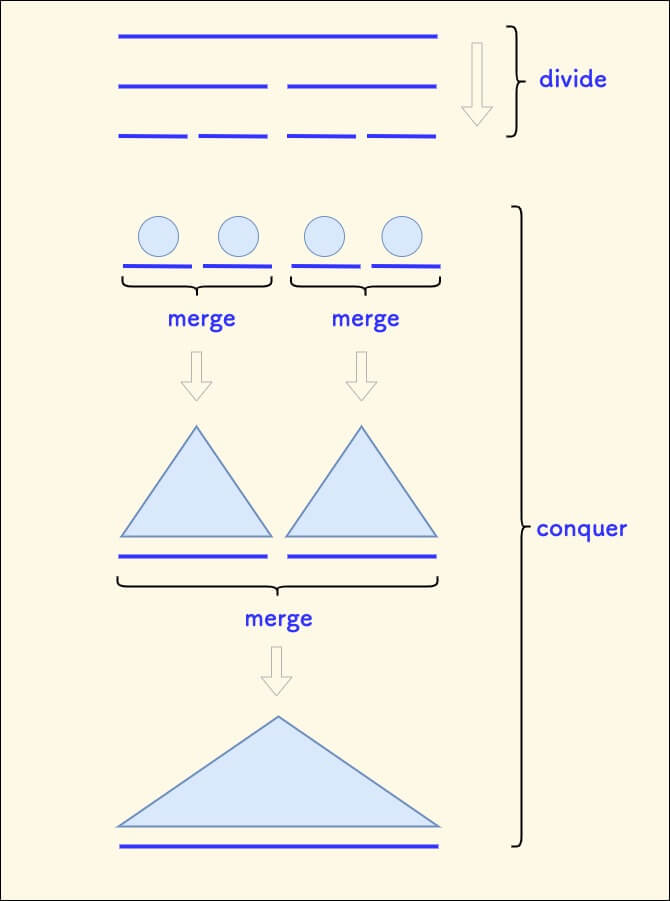
Divide and Conquer Tree Building Approach to Batch Insertion - C++ Code
int build(int l, int r) {
if (l == r) return newnode(to_inserts[l]);
int mid = (l + r) >> 1;
return merge(build(l, mid), build(mid + 1, r));
}
void insert(int k, int tot) {
int x, y;
split(root, k, x, y);
int z = build(1, tot);
root = merge(merge(x, z), y);
}
The time complexity of the divide and conquer tree building is equivalent to merge sort, which is $O(m\log{m})$. The final time complexity of batch insertion is $O(m\log{m} + \log{n})$ or $O(m\log{m} + \log{m})$, which is smaller than the naive approach.
There is an even better linear time complexity approach to building a tree, using a monotonic stack [6].
Batch Deletion ¶
Delete
totconsecutive numbers starting from thek-th number in the sequence.
This is relatively simple:
- First carve out three trees
x,y,z, whereyrepresents the target interval. - Then merge
x,z, discarding the middle intervalyto be deleted.
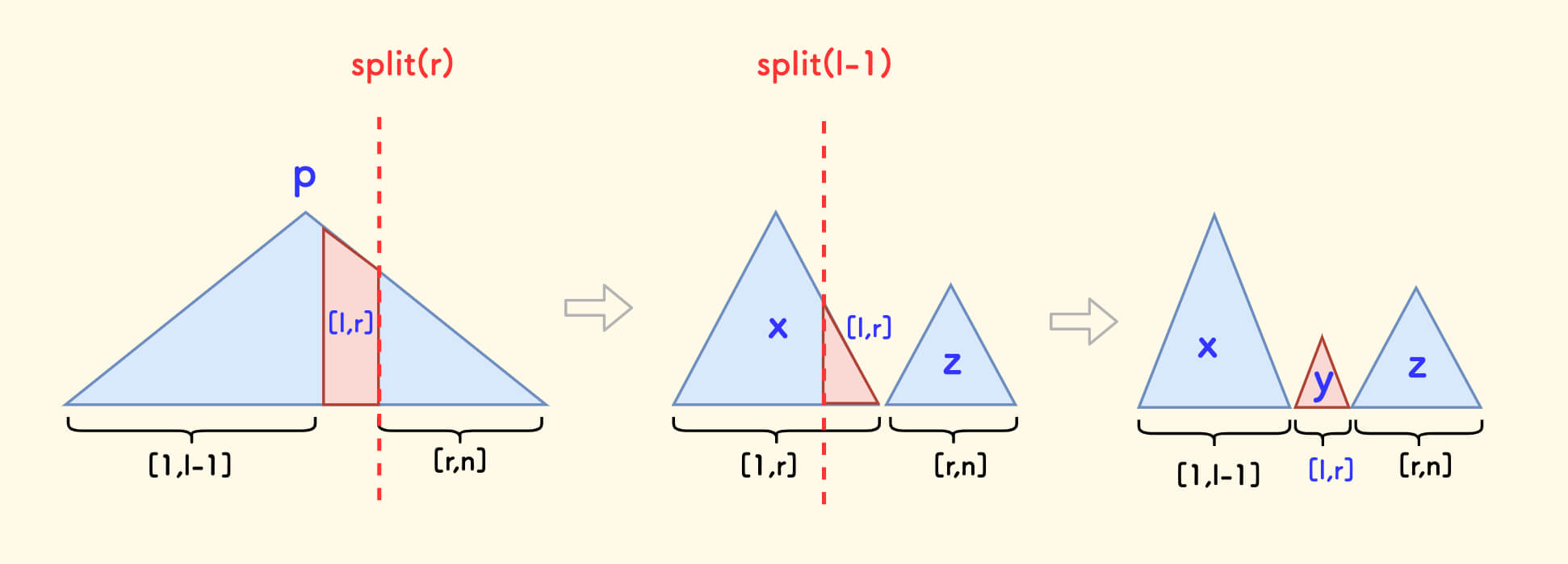
The memory limit of P2042 is relatively strict. Since static arrays are used to store the tree, you can try to reuse the already deleted slots.
Garbage Collection Mechanism
Create a new stack to track the free node numbers that have been deleted:
// Garbage collection stack
int gc_stack[N];
int gc_top = 0;
When deleting a subtree, you need to recursively put each node of the subtree into the gc reclamation pool:
void gc(int p) {
if (!p) return;
gc_stack[gc_top++] = p;
gc(ls), gc(rs);
}
When creating a new node, prioritize reusing the nodes in the reclamation pool:
int newnode(int val) {
// Reuse the reclaimed nodes, tt tracks the latest index in the tr array
int i = gc_top ? gc_stack[--gc_top] : ++tt;
memset(&tr[i], 0, sizeof tr[i]);
// Temporarily omit other initialization items ...
return i;
}
Finally, the batch deletion implementation using garbage collection is as follows:
Batch Deletion - C++ Code
void del(int k, int tot) {
int x, y, z;
// Carve out the target subtree y
help_split(x, y, z, k, tot);
// Reclaim the entire subtree y
gc(y);
// Merge x, z
root = merge(x, z);
}
Interval Sum ¶
Calculate the sum of
totconsecutive numbers starting from thek-th number in the sequence.
First, add a field sum to each node to represent the sum of element values of all nodes in its subtree:
struct {
// ... Omit other fields
int sum; // Interval sum of the subtree
} tr[N];
This field only needs to be maintained by borrowing the pushup function, and the maintenance is the same as that of size:
void pushup(int p) {
tr[p].size = tr[ls].size + tr[rs].size + 1;
tr[p].sum = tr[ls].sum + tr[rs].sum + tr[p].val;
}To query the sum on an interval, you only need to first carve out the subtree, and then take the sum field on the root of the tree.
getsum Interval Sum Function - C++ Code
int getsum(int k, int tot) {
int x, y, z;
help_split(x, y, z, k, tot);
int ans = tr[y].sum;
root = merge(merge(x, y), z);
return ans;
}
Extending it, if you want to maintain the interval maximum, it is a similar approach, you can borrow the pushup function.
Maximum Subsegment Sum ¶
This is the most difficult of the 6 operations:
Find the sum of the sub-sequence with the largest sum in the current sequence.
Three additional fields need to be defined:
struct {
// Omit other fields...
int sum; // Sum of the interval represented
int mpre; // Maximum prefix sum of the interval
int msuf; // Maximum suffix sum of the interval
int msum; // Maximum subsegment sum within the interval
} tr[N];Premise, always pay attention to the interval tree perspective of the treap:
The interval represented by the parent node = the interval of the left child + the parent node + the interval of the right child.
As with the interval sum, the maximum subsegment sum msum can be maintained in the pushup function.
For node p, there are two cases for the maximum subsegment sum in the interval it represents:
The case of passing through
p:At this time, the maximum subsegment sum is equal to the maximum of the following two subcases:
- Maximum suffix sum of the left child interval + value of
p+ maximum prefix sum of the right child interval. - Or only take the single node
pitself.

// Case of passing through p tr[p].msum = max(tr[ls].msuf + tr[p].val + tr[rs].mpre, tr[p].val);- Maximum suffix sum of the left child interval + value of
The case of not passing through
p:At this time, it is easy to know that
p.msumcomes from the largest of themsumof the left and right children.
// Case of not passing through p, take the largest msum of the left and right children if (ls) tr[p].msum = max(tr[p].msum, tr[ls].msum); if (rs) tr[p].msum = max(tr[p].msum, tr[rs].msum);


Two cases, constantly synthesize and take the maximum value.
However, the mpre and msuf fields of the parent node p must also be maintained:
Find the maximum suffix sum
msufof the parent nodep:There are also two cases, the case containing
pand the case not containingp, take the maximum value of the two cases.
tr[p].msuf = max({ tr[rs].sum + tr[p].val + tr[ls].msuf, tr[rs].msuf, 0 });Find the maximum prefix sum
mpreof the parent nodep, the same analysis.
tr[p].mpre = max({ tr[ls].sum + tr[p].val + tr[rs].mpre, tr[ls].mpre, 0 });


One detail is that mpre and msuf must always be guaranteed to be at least 0, because we only consider calculating the non-negative summation components.
maxsum Function and pushup Maintenance - C++ Code
void pushup(int p) {
tr[p].size = tr[ls].size + tr[rs].size + 1;
tr[p].sum = tr[ls].sum + tr[rs].sum + tr[p].val;
tr[p].mpre = max({tr[ls].mpre, tr[ls].sum + tr[p].val + tr[rs].mpre, 0});
tr[p].msuf = max({tr[rs].msuf, tr[rs].sum + tr[p].val + tr[ls].msuf, 0});
tr[p].msum = max(tr[ls].msuf + tr[p].val + tr[rs].mpre, tr[p].val);
if (ls) tr[p].msum = max(tr[p].msum, tr[ls].msum);
if (rs) tr[p].msum = max(tr[p].msum, tr[rs].msum);
}
// Returns the maximum subsegment sum on the entire tree
int maxsum() { return tr[root].msum; }
int newnode(int val) {
// Other code omitted...
tr[i].msum = tr[i].sum = tr[i].val = val;
tr[i].mpre = tr[i].msuf = max(0, val); // Note at least take 0
return i;
}Interval Assignment ¶
Change all
totconsecutive numbers starting from thek-th number in the sequence toc.
As mentioned earlier, this is an interval update and requires the optimization of the lazy propagation mechanism [Go to.
However, lazy propagation will affect the interval sum, and some modifications are needed.
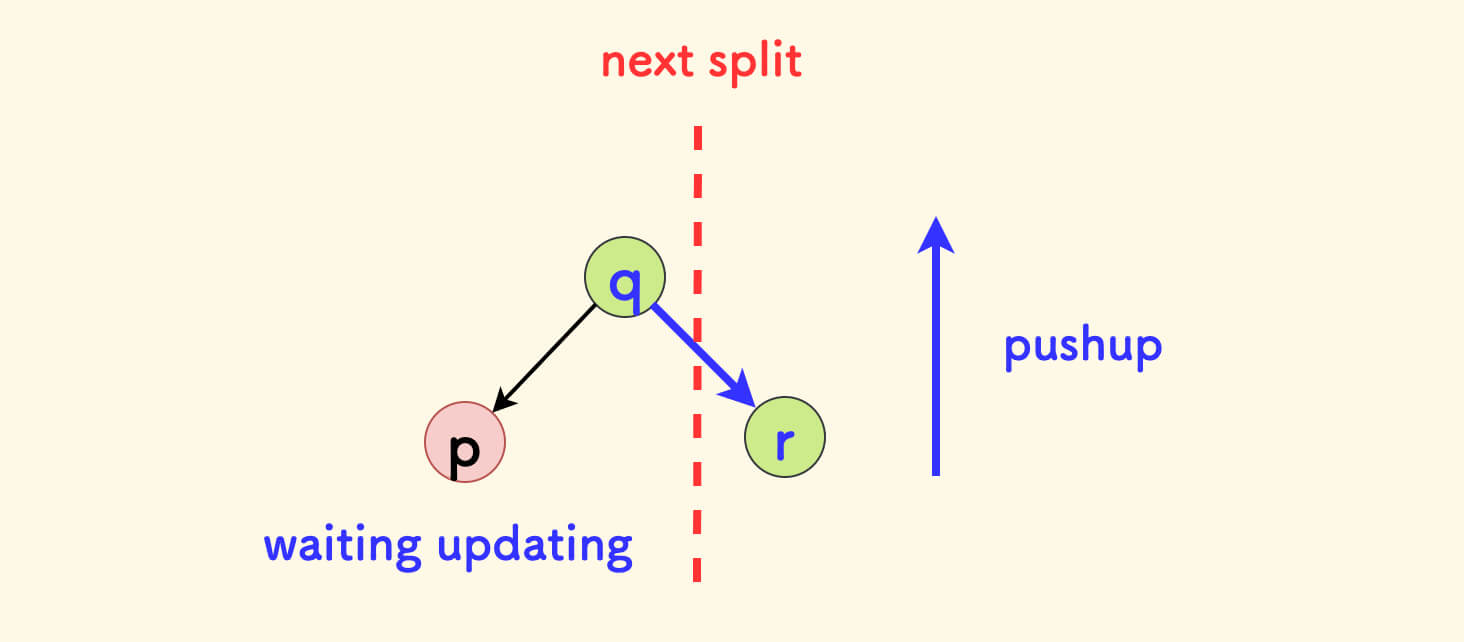
If a lazy tag is only made on a node without updating, then the process of pushup maintaining the interval sum will be miscalculated.
For example, a lazy update tag is made on node p, its parent node is q, and the other child is r. If the next split or merge only passes through r without passing through p, the lazy update will not be triggered, and the summation of the pushup function on the q node will be miscalculated.
For the same reason, the mpre, msuf, and msum maintained by the pushup function will all be wrong.
The solution is to not only put a tag, but also execute one layer down in advance.
Similarly, when the tag is placed down in the pushdown function, it is also necessary to execute one layer down.
In this way, it can be ensured that: the information of the ancestor nodes maintained upwards will not be wrong, only the nodes in their subtrees will be updated lazily.
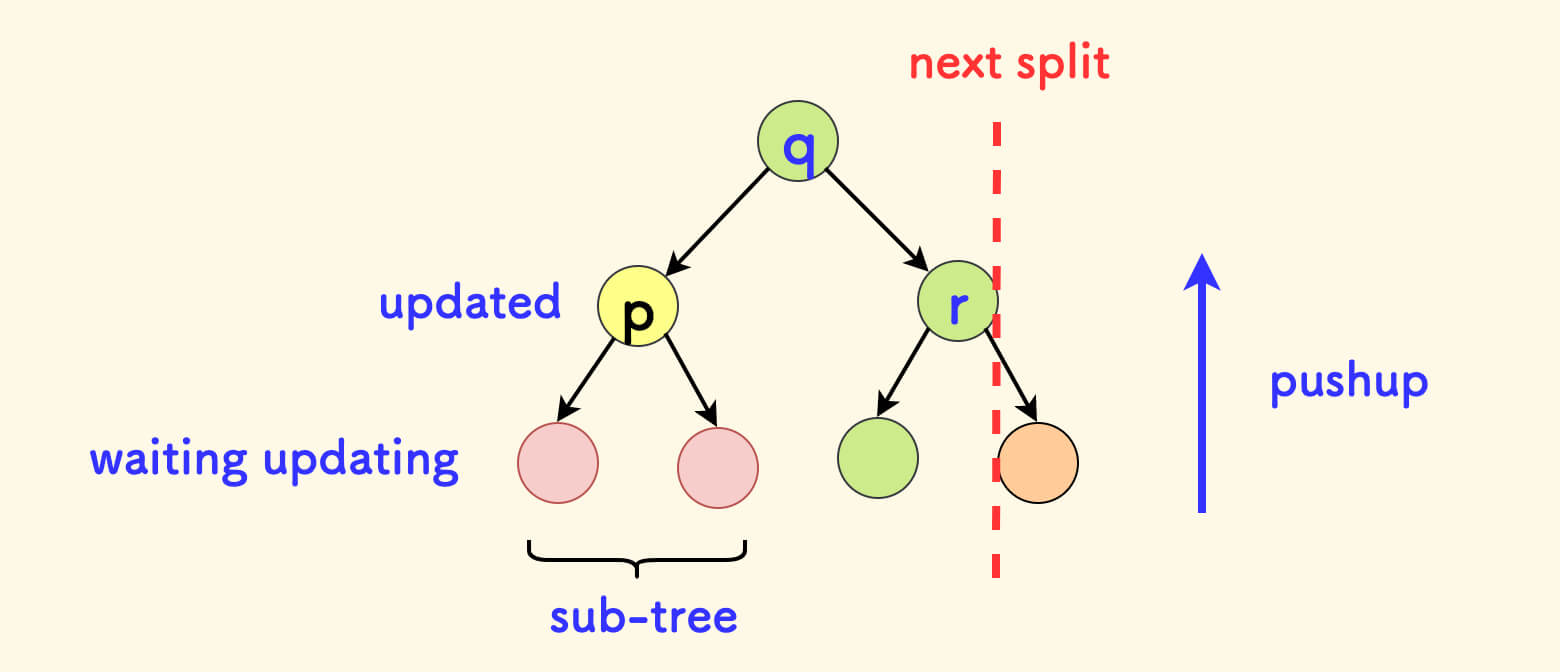
In this way, the lazy propagation mechanism will not be too affected, it just goes one layer further down in advance. The coupling problem caused by pushup maintaining information is also eliminated.
makesame Function - C++ Code
void do_cover(int p) {
if (!tr[p].cov_tag) return;
// Modify the value of the current node
int c = tr[p].val = tr[p].cov_val;
// Because lazy update is used, the sum of the subtree is no longer equal to: the sum of the left and right subtrees + p.val
// Here you have to synchronously modify the interval sum sum and the mpre, msuf, and msum that depend on it
int s = tr[p].sum = c * tr[p].size;
tr[p].mpre = tr[p].msuf = max(0, s);
tr[p].msum = max(c, s);
// Pass down the tag
tr[ls].cov_tag = 1, tr[ls].cov_val = c;
tr[rs].cov_tag = 1, tr[rs].cov_val = c;
// Clear the current tag
tr[p].cov_tag = 0;
tr[p].cov_val = 0;
}
void pushdown(int p) {
if (!p) return;
// The current node executes interval cover
do_cover(p);
// Execute one layer down in advance
if (ls) do_cover(ls);
if (rs) do_cover(rs);
}
void makesame(int k, int tot, int c) {
int x, y, z;
help_split(x, y, z, k, tot);
// Put a tag
tr[y].cov_tag = 1;
tr[y].cov_val = c;
// Execute one layer down in advance
do_cover(y);
root = merge(merge(x, y), z);
}
Interval Reversal ¶
Reverse the
totconsecutive numbers starting from thek-th number in the sequence.
Interval reversal is also an interval update operation and also needs to use the lazy propagation mechanism to optimize.
Interval reversal, can be gradually completed by exchanging the left and right subtrees layer by layer.
Assuming that the subtree of the target interval has been carved out, the following diagram demonstrates the reversal process of this subtree:
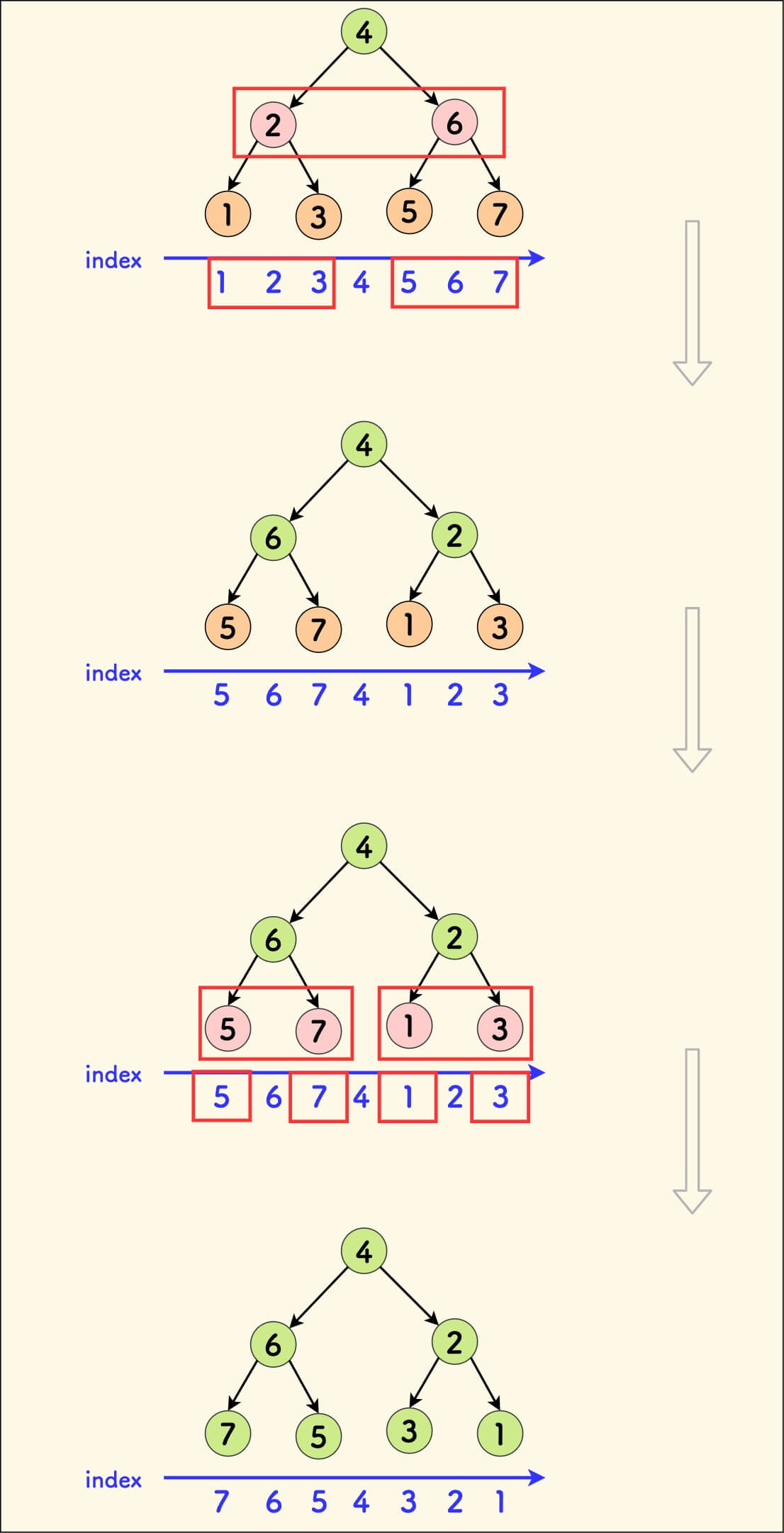
That is, in the pushdown downward process, you only need to exchange the left and right subtrees each time.
Add a field rev_tag to the node, which is 0 or 1. If an even number of reversals are continuously performed on an interval, the reversal tag can be eliminated.
struct {
// Omit other fields
int rev_tag; // Reverse lazy tag
} tr[N];
// Put a tag using XOR
rev_tag ^= 1;Exchanging the left and right subtrees will affect the meaning of the maximum prefix sum mpre and the maximum suffix sum msuf, so they must be maintained together.
// Exchange left and right child subtrees
swap(ls, rs);
// Also exchange the prefix and suffix sums
swap(tr[p].mpre, tr[p].msuf);
Similarly, execute one layer down to eliminate the impact on the maximum subsegment sum information maintained during the pushup process.
reverse Function Interval Reversal - C++ Code
void do_reverse(int p) {
if (!tr[p].rev_tag) return;
// Exchange left and right children
swap(ls, rs);
// Also exchange the prefix and suffix sums
swap(tr[p].mpre, tr[p].msuf);
// Pass down the tag
tr[ls].rev_tag ^= 1;
tr[rs].rev_tag ^= 1;
// Clear the current tag
tr[p].rev_tag = 0;
}
void pushdown(int p) {
if (!p) return;
do_reverse(p);
// Tag downwards, execute one more layer
if (ls) do_reverse(ls);
if (rs) do_reverse(rs);
}
// Reverse tot elements at k
void reverse(int k, int tot) {
int x, y, z;
help_split(x, y, z, k, tot);
// Put a tag
tr[y].rev_tag ^= 1;
// Execute one layer in advance
do_reverse(y);
root = merge(merge(x, y), z);
}
So far, all 6 interval operations have been explained.
Template Code ¶
- Luogu P2042 - Maintaining a Sequence (many pitfalls): Problem, Code
- Luogu P3391 - Artistic Balanced Tree (only involves interval reversal): Problem, Code
Concluding Remarks ¶
fhq treap is really a very cost-effective data structure. There are only two core operations, and other operations are built on this basis.
Finally, make some summaries.
Ordinary balanced tree treap:
- Treap is a combination of BST and Heap.
- Capabilities are all based on two core operations: split and merge.
- How to carve out the target subtree is the key.
- Split and merge do not affect the relative order of inorder traversal.
Treap that supports interval operations:
- To perform interval operations, split by position.
- View it as an interval tree: any interval can be carved out to correspond to a subtree.
- To perform interval updates, you can use “lazy propagation” optimization.
- Divide and conquer to build a tree.
- Suitable for borrowing the
pushupfunction: interval query operations. - Suitable for borrowing the
pushdownfunction: lazy tag propagation for interval updates. - The lazy propagation mechanism will bring about logical coupling with the upward maintenance of
pushup, the solution: execute one layer down in advance.
Update 2024/04/30: However, I think it also has disadvantages compared to segment trees and binary indexed trees: it takes up more memory and depends on a random function.
Footnotes ¶
- Binary Search Tree - Wikipedia
- Data Structure - Heap Theory and Common Algorithm Problems
- Treap - Wikipedia
- Reference: Dong Xiao’s fhq Balanced Tree Explanation
- O(n) Tree Building of Non-Rotating treap - OI wiki
(End)
Please note that this post is an AI-automatically chinese-to-english translated version of my original blog post: http://writings.sh/post/fhq-treap.
Related Readings:
- Interval Sum and Counting Treap Solution
- LIS Problem Treap Solution
- LIS Counting Problem Treap Solution
Original Link: https://writings.sh/post/en/fhq-treap